long count();
//anyMatch判断的条件里,任意一个元素成功,返回true
boolean anyMatch(Predicate<? super T> predicate);
//allMatch判断条件里的元素,所有的都是,返回true
boolean allMatch(Predicate<? super T> predicate);
//noneMatch跟allMatch相反,判断条件里的元素,所有的都不是,返回true
boolean noneMatch(Predicate<? super T> predicate);
========================================
List<String> strs = Arrays.asList("a", "a", "a", "a", "b");
boolean aa = strs.stream().anyMatch(str -> str.equals("a"));
boolean bb = strs.stream().allMatch(str -> str.equals("a"));
boolean cc = strs.stream().noneMatch(str -> str.equals("a"));
long count = strs.stream().filter(str -> str.equals("a")).count();
System.out.println(aa);// TRUE
System.out.println(bb);// FALSE
System.out.println(cc);// FALSE
System.out.println(count);// 4
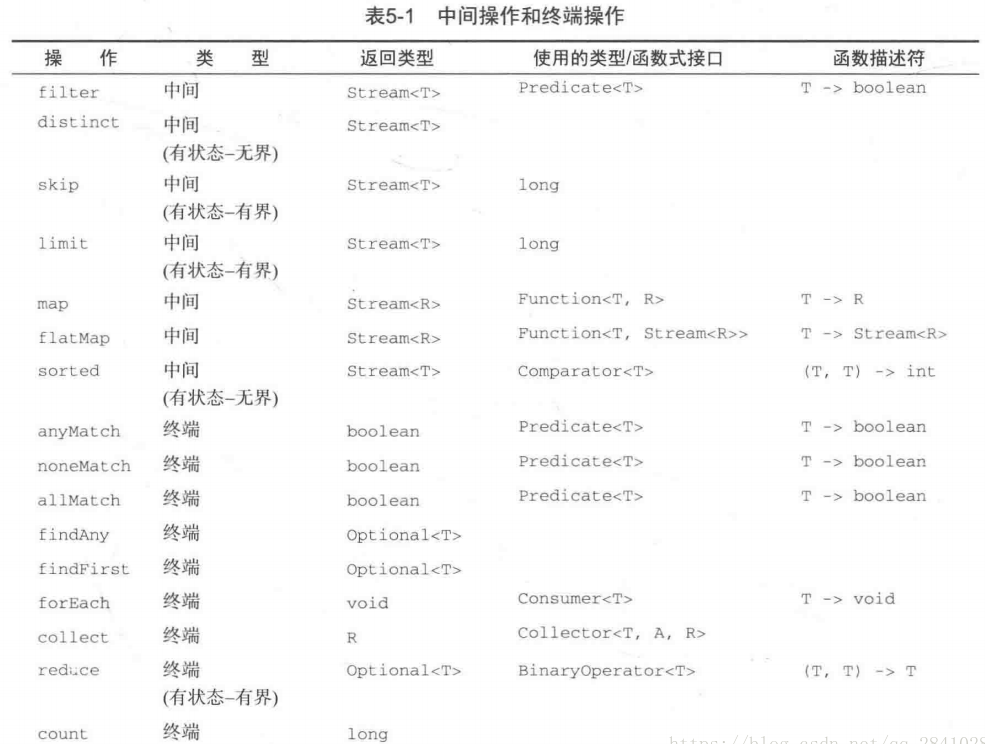
中间操作
流中间操作在应用到流上,返回一个新的流:
map:通过一个 Function 把一个元素类型为 T 的流转换成元素类型为 R 的流。
flatMap:通过一个 Function 把一个元素类型为 T 的流中的每个元素转换成一个元素类型为 R 的流,再把这些转换之后的流合并。
filter:过滤流中的元素,只保留满足由 Predicate 所指定的条件的元素。
distinct:使用 equals 方法来删除流中的重复元素。
limit:截断流使其最多只包含指定数量的元素。
skip:返回一个新的流,并跳过原始流中的前 N 个元素。
sorted:对流进行排序。
peek:返回的流与原始流相同。当原始流中的元素被消费时,会首先调用 peek 方法中指定的 Consumer 实现对元素进行处理。
dropWhile:从原始流起始位置开始删除满足指定 Predicate 的元素,直到遇到第一个不满足 Predicate 的元素。
takeWhile:从原始流起始位置开始保留满足指定 Predicate 的元素,直到遇到第一个不满足 Predicate 的元素。
终结操作
终结操作产生最终的结果。
forEach 和 forEachOrdered 对流中的每个元素执行由 Consumer 给定的实现。在使用 forEach 时,并没有确定的处理元素的顺序;forEachOrdered 则按照流的相遇顺序来处理元素,如果流有确定的相遇顺序的话。
reduce进行递归计算
collect生成新的数据结构
count







