
Apache Flink是一个高效、分布式、基于Java和Scala(主要是由Java实现)实现的通用大数据分析引擎,它具有分布式 MapReduce一类平台的高效性、灵活性和扩展性以及并行数据库查询优化方案,它支持批量和基于流的数据分析,且提供了基于Java和Scala的API。
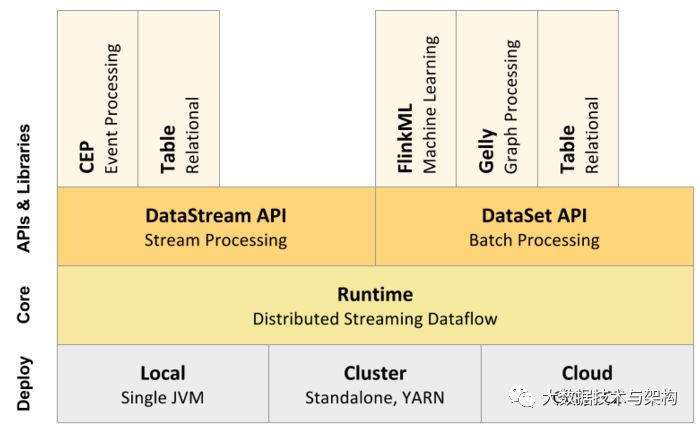
从Flink官方文档可以知道,目前Flink支持三大部署模式:Local、Cluster以及Cloud,如下图所示:
本文将简单地介绍如何部署Apache Flink On YARN(也就是如何在YARN上运行Flink作业),本文是基于Apache Flink 1.0.0以及Hadoop 2.2.0。
在YARN上启动一个Flink主要有两种方式:(1)、启动一个YARN session(Start a long-running Flink cluster on YARN);(2)、直接在YARN上提交运行Flink作业(Run a Flink job on YARN)。下面将分别进行介绍。
Fflink YARN Session
这种模式下会启动yarn session,并且会启动Flink的两个必要服务:JobManager和TaskManagers,然后你可以向集群提交作业。同一个Session中可以提交多个Flink作业。需要注意的是,这种模式下Hadoop的版本至少是2.2,而且必须安装了HDFS(因为启动YARN session的时候会向HDFS上提交相关的jar文件和配置文件)。我们可以通过./bin/yarn-session.sh脚本启动YARN Session,由于我们第一次使用这个脚本,我们先看看这个脚本支持哪些参数:
[flink]$ . /bin/yarn-session .sh
Usage:
Required
-n,--container <arg> Number of YARN container to allocate (=Number of Task Managers)
Optional
-D <arg> Dynamic properties
-d,--detached Start detached
-jm,--jobManagerMemory <arg> Memory for JobManager Container [ in MB]
-nm,--name <arg> Set a custom name for the application on YARN
-q,--query Display available YARN resources (memory, cores)
-qu,--queue <arg> Specify YARN queue.
-s,--slots <arg> Number of slots per TaskManager
-st,--streaming Start Flink in streaming mode
-tm,--taskManagerMemory <arg> Memory per TaskManager Container [ in MB]
各个参数的含义里面已经介绍的很详细了。在启动的是可以指定TaskManager的个数以及内存(默认是1G),也可以指定JobManager的内存,但是JobManager的个数只能是一个。好了,我们开启动一个YARN session吧:
. /bin/yarn-session .sh -n 4 -tm 8192 -s 8
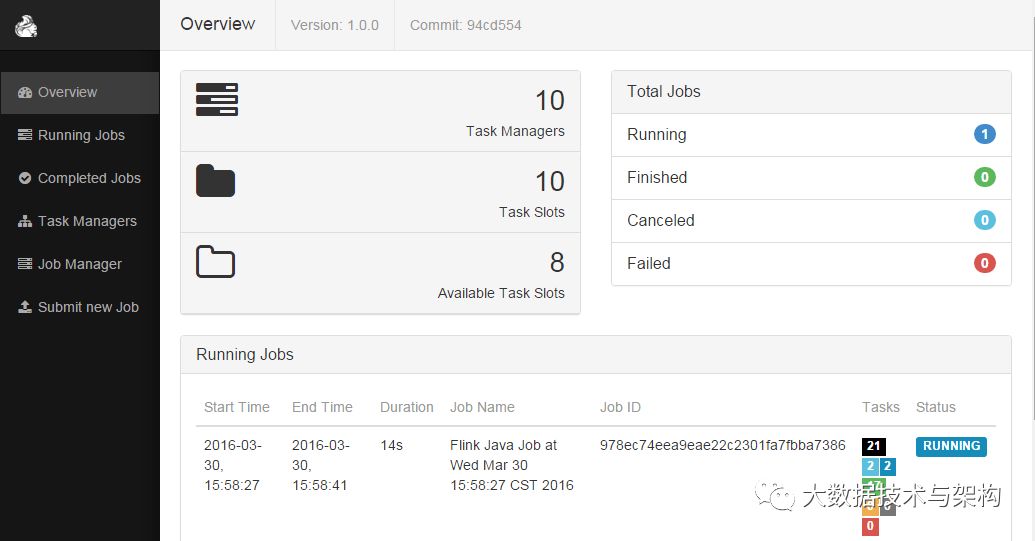
上面命令启动了4个TaskManager,每个TaskManager内存为8G且占用了8个核(是每个TaskManager,默认是1个核)。在启动YARN session的时候会加载conf/flink-config.yaml配置文件,我们可以根据自己的需求去修改里面的相关参数(关于里面的参数含义请参见Flink官方文档介绍吧)。一切顺利的话,我们可以在https://www.iteblog.com:9981/proxy/application_1453101066555_2766724/#/overview上看到类似于下面的页面:
启动了YARN session之后我们如何运行作业呢?很简单,我们可以使用./bin/flink脚本提交作业,同样我们来看看这个脚本支持哪些参数:
[iteblog @ www.iteblog.com flink- 1.0 . 0 ]$ bin/flink
./flink <ACTION> [OPTIONS] [ARGUMENTS]
The following actions are available :
Action "run" compiles and runs a program.
Syntax : run [OPTIONS] <jar-file> <arguments>
"run" action options :
-c,-- class <classname> Class with the program entry point
( "main" method or "getPlan()" method.
Only needed if the JAR file does not
specify the class in its manifest.
-C,--classpath <url> Adds a URL to each user code
classloader on all nodes in the
cluster. The paths must specify a
protocol (e.g. file : //) and be
accessible on all nodes (e.g. by means
of a NFS share). You can use this
option multiple times for specifying
more than one URL. The protocol must
be supported by the { @ link
java.net.URLClassLoader}.
-d,--detached If present, runs the job in detached
mode
-m,--jobmanager <host : port> Address of the JobManager (master) to
which to connect. Specify
'yarn-cluster' as the JobManager to
deploy a YARN cluster for the job. Use
this flag to connect to a different
JobManager than the one specified in
the configuration.
-p,--parallelism <parallelism> The parallelism with which to run the
program. Optional flag to override the
default value specified in the
configuration.
-q,--sysoutLogging If present, supress logging output to
standard out.
-s,--fromSavepoint <savepointPath> Path to a savepoint to reset the job
back to ( for example
file : ///flink/savepoint-1537).
我们可以使用run选项运行Flink作业。这个脚本可以自动获取到YARN session的地址,所以我们可以不指定--jobmanager参数。我们以Flink自带的WordCount程序为例进行介绍,先将测试文件上传到HDFS上:
hadoop fs -copyFromLocal LICENSE hdfs : ///user/iteblog/
然后将这个文件作为输入并运行WordCount程序:
./bin/flink run ./examples/batch/WordCount.jar --input hdfs : ///user/iteblog/LICENSE
一切顺利的话,可以看到在终端会显示出计算的结果:
( 0 , 9 )
( 1 , 6 )
( 10 , 3 )
( 12 , 1 )
( 15 , 1 )
( 17 , 1 )
( 2 , 9 )
( 2004 , 1 )
( 2010 , 2 )
( 2011 , 2 )
( 2012 , 5 )
( 2013 , 4 )
( 2014 , 6 )
( 2015 , 7 )
( 2016 , 2 )
( 3 , 6 )
( 4 , 4 )
( 5 , 3 )
( 50 , 1 )
( 6 , 3 )
( 7 , 3 )
( 8 , 2 )
( 9 , 2 )
(a, 25 )
(above, 4 )
(acceptance, 1 )
(accepting, 3 )
(act, 1 )
如果我们不想将结果输出在终端,而是保存在文件中,可以使用--output参数指定保存结果的地方:
./bin/flink run ./examples/batch/WordCount.jar \
--input hdfs : ///user/iteblog/LICENSE \
--output hdfs : ///user/iteblog/result.txt
然后我们可以到hdfs:///user/iteblog/result.txt文件里面查看刚刚运行的结果。
需要注意的是:1、上面的--input和--output参数并不是Flink内部的参数,而是WordCount程序中定义的;
2、指定路径的时候一定记得需要加上模式,比如上面的hdfs://,否者程序会在本地寻找文件。
Rrun a single Flink job on YARN
上面的YARN session是在Hadoop YARN环境下启动一个Flink cluster集群,里面的资源是可以共享给其他的Flink作业。我们还可以在YARN上启动一个Flink作业。这里我们还是使用./bin/flink,但是不需要事先启动YARN session:
./bin/flink run -m yarn-cluster -yn 2 ./examples/batch/WordCount.jar \
--input hdfs : ///user/iteblog/LICENSE \
--output hdfs : ///user/iteblog/result.txt
上面的命令同样会启动一个类似于YARN session启动的页面。其中的-yn是指TaskManager的个数,必须指定。
本文分享自微信公众号 - 大数据技术与架构(import_bigdata)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。











