
作者: Cyandev, iOS 和 MacOS 开发者,目前就职于字节跳动
0x00 前言
异常处理是许多高级语言都具有的特性,它可以直接中断当前函数并将控制权转交给能够处理异常的函数。不同语言在异常处理的实现上各不相同,本文主要来分析一下 Objective-C 和 C++ 这两个语言。
为什么要把 Objective-C 和 C++ 放在一起呢?因为它们在实现机制上太像了,更严格地说,Objective-C 的异常处理机制就是借助 C++ 来实现的。而说到 Objective-C 的异常处理,还需要引出一个问题,就是内存泄漏。它产生的原因是什么?要怎么解决?这里我们先留个疑问,在文章后面会解释。
0x10 异常处理做了什么
异常处理,核心不在异常,而在处理。也就是说不管你抛出的是 NSException 还是原始类型,这只是一个信息承载的方式,异常处理最关键的是如何把这个异常传递给能够处理它的人。还有最重要的一点,在这个过程中把现场“清理干净”(这也是 C++ RAII 的精髓所在)。
考虑下面的代码片段:
`static void bar() {
struct tracker {
~tracker() {
std::cout << this << " destroyed" << std::endl;
}
} tracker;
throw "baz";
}
static void foo() {
struct tracker {
~tracker() {
std::cout << this << " destroyed" << std::endl;
}
} tracker;
bar();
std::cout << "dummy operation" << std::endl;
}
int main(int argc, char * argv[]) {
try {
foo();
} catch (...) {
std::cout << "I catch it!" << std::endl;
}
// ...
}
`
执行之后将会打印:
0x7ffee5090918 destroyed 0x7ffee5090948 destroyed I catch it!
可以直观得看到栈帧经历了 bar → foo → main 的过程,因为 C++ 栈上对象释放也是当前栈帧末尾做的,这里需要额外注意的是 foo 函数并没有执行完毕,但仍然成功释放了栈上的 tracker 对象。因此 C++ 在栈帧回溯上的做法一定不是简单地 setjmp / longjmp[1]。
0x20 RAII 清理过程
我们将代码稍微修改一下:
`static void bar(bool should_throw) {
struct tracker {
~tracker() {
std::cout << this << " destroyed" << std::endl;
}
};
tracker tracker1;
if (should_throw) {
throw "baz";
}
tracker tracker2;
}
`
这时假设我们调用 bar(false),我们会看到 tracker1 和 tracker2 销毁的两条日志,但当我们调用 bar(true),由于 tracker2 构造之前抛出了异常,我们只会看到 tracker1 的销毁日志。这也说明是否抛出异常,一个栈帧的清理过程是两条不同的 routine。
为了搞明白发生了什么,我们可以看下汇编代码:
bar: 0x10c18b910 <+0>: pushq %rbp 0x10c18b911 <+1>: movq %rsp, %rbp 0x10c18b914 <+4>: subq $0x20, %rsp // ... 0x10c18b934 <+36>: testb $0x1, -0x1(%rbp) 0x10c18b938 <+40>: je 0x10c18b98e ; 跳过抛出异常的逻辑 // ... 0x10c18b954 <+68>: callq 0x10c25a288 ; symbol stub for: __cxa_allocate_exception // ... 0x10c18b96f <+95>: callq 0x10c25a29a ; symbol stub for: __cxa_throw 0x10c18b974 <+100>: jmp 0x10c18b9b1 ; 跳转到最后的 ud2 指令处 0x10c18b979 <+105>: movq %rax, -0x10(%rbp) 0x10c18b97d <+109>: movl %edx, -0x14(%rbp) 0x10c18b980 <+112>: leaq -0x8(%rbp), %rdi 0x10c18b984 <+116>: callq 0x10c18bae0 ; bar(bool)::tracker::~tracker() 0x10c18b989 <+121>: jmp 0x10c18b9a6 ; 异常路径下 tracker 析构结束,继续异常处理流程 0x10c18b98e <+126>: leaq -0x18(%rbp), %rdi 0x10c18b992 <+130>: callq 0x10c18bae0 ; bar(bool)::tracker::~tracker() 0x10c18b997 <+135>: leaq -0x8(%rbp), %rdi 0x10c18b99b <+139>: callq 0x10c18bae0 ; bar(bool)::tracker::~tracker() 0x10c18b9a0 <+144>: addq $0x20, %rsp 0x10c18b9a4 <+148>: popq %rbp 0x10c18b9a5 <+149>: retq 0x10c18b9a6 <+150>: movq -0x10(%rbp), %rdi 0x10c18b9aa <+154>: callq 0x10c25a228 ; symbol stub for: _Unwind_Resume 0x10c18b9af <+159>: ud2 0x10c18b9b1 <+161>: ud2 ; 到达不可达路径,强制触发 SIGILL 结束进程
可以看到我们的函数中的确存在两条栈帧清理的执行链路。有趣的是,当我们继续增加新的异常路径,栈帧清理的执行路径也会随之增加。也就是说,当异常发生时,runtime 必须要按一定的路径来逐一退出栈帧到 exception handler,不能将栈帧直接重置,否则就会引发资源泄漏。这个过程叫做 **Stack Unwinding[2]**,在 macOS 中, C++ ABI 使用了 libunwind 来配合实现异常处理机制。
0x21 noexcept 关键字
C++ 中的 [noexcept](https://en.cppreference.com/w/cpp/language/noexcept_spec "noexcept") 关键字用于标注一个函数或 lambda 是否可能会抛出异常,对于下面的代码片段:
`static void bar() /* noexcept */;
static void foo() {
struct tracker {
~tracker() {
std::cout << this << " destroyed" << std::endl;
}
};
tracker tracker1;
bar();
tracker tracker2;
}
`
bar 函数是否标注 noexcept 也将决定 foo 函数的 code generation 结果,也就是说编译器是否要为一个函数生成多条清理执行路径,是会取决于栈空间对象分配过程之间是否有“潜在抛出异常的表达式”。
即便 bar 函数中什么操作都没有,因为没有标注 noexcept,编译器依旧会为它生成两条清理执行路径,因为编译器不确定 bar 函数内部会不会抛出异常,为了避免资源泄漏,编译器只能保守推断。而当我们显式标注 noexcept 之后,我们依然可以在那个函数中调用会抛出异常的函数或者直接使用 throw 表达式,编译器只会产生警告,当然,这样做的结果就是会导致 caller 发生资源泄漏。
0x30 抛出异常时发生了什么
现在我们就可以正向跟踪一下抛出异常时都经历了哪些过程。我们直接反编译下面这个十分简单的代码片段:
static void bar() { throw 0; }
得到:
bar: 0x10a2152f0 <+0>: pushq %rbp 0x10a2152f1 <+1>: movq %rsp, %rbp 0x10a2152f4 <+4>: incq 0x11af2d(%rip) ; __profc__ZNSt3__1lsINS_11char_traitsIcEEEERNS_13basic_ostreamIcT_EES6_PKc + 24 0x10a2152fb <+11>: movl $0x4, %edi 0x10a215300 <+16>: callq 0x10a2e329a ; symbol stub for: __cxa_allocate_exception 0x10a215305 <+21>: movl $0x0, (%rax) 0x10a21530b <+27>: movq 0xeb626(%rip), %rsi ; (void *)0x000000010e467b00: typeinfo for int 0x10a215312 <+34>: movq %rax, %rdi 0x10a215315 <+37>: xorl %edx, %edx 0x10a215317 <+39>: callq 0x10a2e32ac ; symbol stub for: __cxa_throw
这里有两个关键的步骤:__cxa_allocate_exception 和 __cxa_throw,LLVM 对它们的描述可以参考这个文档:https://libcxxabi.llvm.org/spec.html\[3\]。
其中 __cxa_allocate_exception 代码如下,
`static
inline
void*
thrown_object_from_cxa_exception(__cxa_exception* exception_header)
{
return static_cast<void*>(exception_header + 1);
}
void *__cxa_allocate_exception(size_t thrown_size) throw() {
size_t actual_size = cxa_exception_size_from_exception_thrown_size(thrown_size);
// Allocate extra space before the __cxa_exception header to ensure the
// start of the thrown object is sufficiently aligned.
size_t header_offset = get_cxa_exception_offset();
char *raw_buffer =
(char *)__aligned_malloc_with_fallback(header_offset + actual_size);
if (NULL == raw_buffer)
std::terminate();
__cxa_exception *exception_header =
static_cast<__cxa_exception *>((void *)(raw_buffer + header_offset));
::memset(exception_header, 0, actual_size);
return thrown_object_from_cxa_exception(exception_header);
}
`
该函数为我们要 throw 的 exception object 分配空间,该空间会包含一个 exception header,用来存储一些 C++ ABI 需要的信息,偏移后的空间用来存储用户数据。
异常对象准备好之后就开始了 throw 的过程,即 __cxa_throw,代码如下:
`void
__cxa_throw(void *thrown_object, std::type_info *tinfo, void (*dest)(void *)) {
__cxa_eh_globals globals = __cxa_get_globals();
__cxa_exception exception_header = cxa_exception_from_thrown_object(thrown_object);
exception_header->unexpectedHandler = std::get_unexpected();
exception_header->terminateHandler = std::get_terminate();
exception_header->exceptionType = tinfo;
exception_header->exceptionDestructor = dest;
setOurExceptionClass(&exception_header->unwindHeader);
exception_header->referenceCount = 1; // This is a newly allocated exception, no need for thread safety.
globals->uncaughtExceptions += 1; // Not atomically, since globals are thread-local
exception_header->unwindHeader.exception_cleanup = exception_cleanup_func;
_Unwind_RaiseException(&exception_header->unwindHeader);
// This only happens when there is no handler, or some unexpected unwinding
// error happens.
failed_throw(exception_header);
}
`
这个主要就是初始化一下 exception header,然后调用关键函数:_Unwind_RaiseException。这个函数位于 libunwind.dylib 中,我们可以从 Apple Open Source[4] 下载对应系统版本的 libunwind 源码。
从这里开始,C++ ABI 的工作就完成一半了,接下来就交给 libunwind 来对栈帧进行回退操作。
0x40 __unwind_info Section
编译器在编译 objects 时会产生 __eh_frame(Dwarf FDEs)或 __compact_unwind 两种 sections 用于记录 stack unwinding 需要的信息。对于 __compact_unwind,连接器最终创建可执行文件时就会产生 __unwind_info section,目前大多数程序都会使用这种方式。
这个 section 中会包含 unwind_info_section_header、unwind_info_section_header_index_entry 和 unwind_info_compressed_second_level_page_header 等几种结构体,定义都位于 libunwind 中。
它们之间的关系可以如下表示:
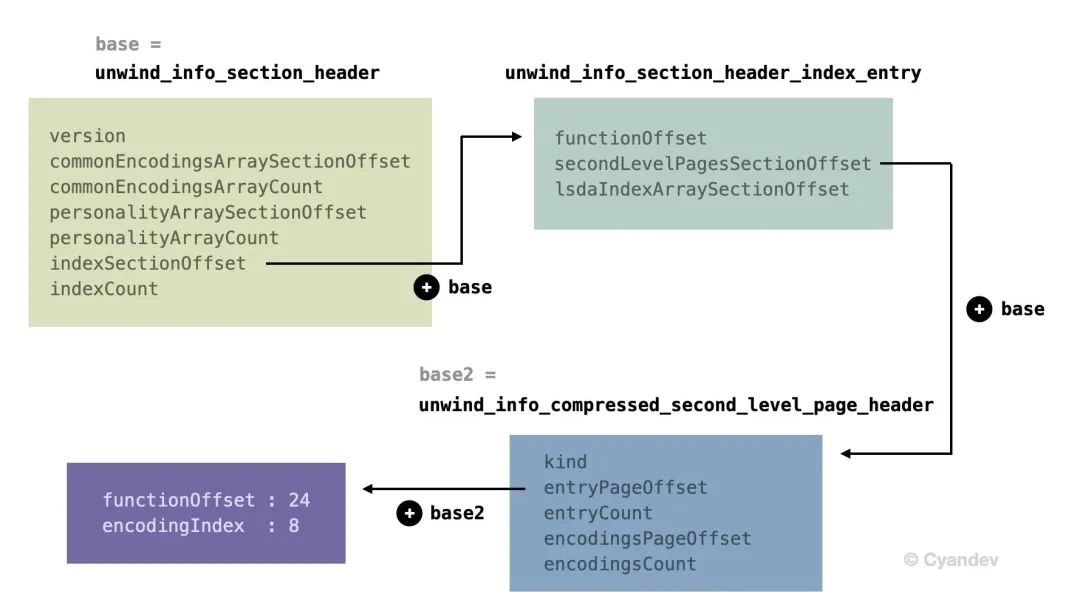
0x41 根据 IP 定位 Stack Unwinding 信息
libunwind 通过 UnwindCursor 类型来从 __unwind_info section 中搜索某函数指针所对应的相关数据。初始化入口函数为 setInfoBasedOnIPRegister:
`template <typename A, typename R>
void UnwindCursor<A,R>::setInfoBasedOnIPRegister(bool isReturnAddress)
{
pint_t pc = this->getReg(UNW_REG_IP);
// if the last line of a function is a "throw" the compile sometimes
// emits no instructions after the call to __cxa_throw. This means
// the return address is actually the start of the next function.
// To disambiguate this, back up the pc when we know it is a return
// address.
if ( isReturnAddress )
--pc;
// ask address space object to find unwind sections for this pc
pint_t mh;
pint_t dwarfStart;
pint_t dwarfLength;
pint_t compactStart;
if ( fAddressSpace.findUnwindSections(pc, mh, dwarfStart, dwarfLength, compactStart) ) {
// if there is a compact unwind encoding table, look there first
if ( compactStart != 0 ) {
if ( this->getInfoFromCompactEncodingSection(pc, mh, compactStart) ) {
// ...
}
// ...
}
// ...
}
// no unwind info, flag that we can't reliable unwind
fUnwindInfoMissing = true;
}
`
其中 findUnwindSections 用来定位 __unwind_info section,里面就是直接用到了 dyld 的 API,这里就不展开了。接下来到了关键的一步,调用 getInfoFromCompactEncodingSection 开始根据 IP 搜索。
getInfoFromCompactEncodingSection 使用二分搜索,首先在所有 unwind_info_section_header_index_entry 结构这个较大的地址范围内中搜索可能包含该 IP 的项,然后在所有 unwind_info_compressed_second_level_page_header 二级结构中进一步搜索。最后能够确定出 funcStart、funcEnd、encodingIndex(从而得到 encoding):
`UnwindSectionCompressedPageHeader pageHeader(fAddressSpace, secondLevelAddr);
UnwindSectionCompressedArray pageIndex(fAddressSpace, secondLevelAddr + pageHeader.entryPageOffset());
const uint32_t targetFunctionPageOffset = targetFunctionOffset - firstLevelFunctionOffset;
// binary search looks for entry with e where index[e].offset <= pc < index[e+1].offset
uint32_t low = 0;
const uint32_t last = pageHeader.entryCount() - 1;
uint32_t high = pageHeader.entryCount();
while ( low < high ) {
uint32_t mid = (low + high)/2;
if ( pageIndex.functionOffset(mid) <= targetFunctionPageOffset ) {
if ( (mid == last) || (pageIndex.functionOffset(mid+1) > targetFunctionPageOffset) ) {
low = mid;
break;
}
else {
low = mid+1;
}
}
else {
high = mid;
}
}
funcStart = pageIndex.functionOffset(low) + firstLevelFunctionOffset + mh;
if ( low < last )
funcEnd = pageIndex.functionOffset(low+1) + firstLevelFunctionOffset + mh;
else
funcEnd = firstLevelNextPageFunctionOffset + mh;
uint16_t encodingIndex = pageIndex.encodingIndex(low);
if ( encodingIndex < sectionHeader.commonEncodingsArrayCount() ) {
// encoding is in common table in section header
encoding = fAddressSpace.get32(unwindSectionStart+sectionHeader.commonEncodingsArraySectionOffset()+encodingIndexsizeof(uint32_t));
}
else {
// encoding is in page specific table
uint16_t pageEncodingIndex = encodingIndex-sectionHeader.commonEncodingsArrayCount();
encoding = fAddressSpace.get32(secondLevelAddr+pageHeader.encodingsPageOffset()+pageEncodingIndexsizeof(uint32_t));
}
`
得到 encoding 才能进一步确定函数是否具有 LSDA(Language Specific Data Area),编译器会将异常相关的信息存放到这个区域中。通过 encoding 也可以得到 personality 函数指针,该函数指针会被存储起来在后面与 LSDA 配合一起用来判断一个栈帧是否可以处理某个异常。
有了这些数据就可以开始做 stack unwinding 了。
0x50 Two-Phase Unwinding
在 libunwind 中,stack unwinding 经历两个阶段:lookup、cleanup。首先第一个 lookup 阶段用于查找是否有哪个栈帧可以处理这个异常,如果没有,就会直接跳过第二阶段,从而执行 failed_throw → std::__terminate 来结束进程。
第二阶段与第一阶段非常类似,都是从栈顶重新 walk 所有栈帧,找到是否有某个栈帧或者 landing pad 可以处理异常。所以我们就直接来看第二阶段的代码吧:
`static _Unwind_Reason_Code unwind_phase2(unw_context_t* uc, struct _Unwind_Exception* exception_object)
{
unw_cursor_t cursor2;
unw_init_local(&cursor2, uc);
// walk each frame until we reach where search phase said to stop
while ( true ) {
// ask libuwind to get next frame (skip over first which is _Unwind_RaiseException)
unw_step(&cursor2);
// get info about this frame
unw_word_t sp;
unw_proc_info_t frameInfo;
unw_get_reg(&cursor2, UNW_REG_SP, &sp);
unw_get_proc_info(&cursor2, &frameInfo);
// if there is a personality routine, tell it we are unwinding
if ( frameInfo.handler != 0 ) {
__personality_routine p = (__personality_routine)(long)(frameInfo.handler);
_Unwind_Action action = _UA_CLEANUP_PHASE;
if ( sp == exception_object->private_2 )
action = (_Unwind_Action)(_UA_CLEANUP_PHASE|_UA_HANDLER_FRAME); // tell personality this was the frame it marked in phase 1
_Unwind_Reason_Code personalityResult = (p)(1, action,
exception_object->exception_class, exception_object,
(struct _Unwind_Context)(&cursor2));
switch ( personalityResult ) {
case _URC_CONTINUE_UNWIND:
// continue unwinding
break;
case _URC_INSTALL_CONTEXT:
unw_resume(&cursor2);
// unw_resume() only returns if there was an error
return _URC_FATAL_PHASE2_ERROR;
default:
// something went wrong
DEBUG_MESSAGE("personality function returned unknown result %d", personalityResult);
return _URC_FATAL_PHASE2_ERROR;
}
}
}
// clean up phase did not resume at the frame that the search phase said it would
return _URC_FATAL_PHASE2_ERROR;
}
`
walk 的过程就是不断调用 unw_step 找到下个栈帧的 unw_proc_info_t,然后调用之前找到的 personality 函数判断栈帧是否可以处理这个异常。之前我们提到了 LSDA,但是这里并没有看到使用到它,那是因为 personality 函数会调用 libunwind 中暴露的 _Unwind_GetLanguageSpecificData 函数来获取,这里传入 personality 的只需要 _Unwind_Context 对象。
当找到一个可用栈帧时就会调用 unw_resume 函数跳转过去执行,这里就比较类似 longjmp 了,只不过跳转的地址和上下文是编译期确定好的。unw_resume 调用的 jumpto 内部是通过汇编来实现的(毕竟要操作寄存器了)
EXPORT int unw_resume(unw_cursor_t* cursor) { DEBUG_PRINT_API("unw_resume(cursor=%p)\n", cursor); AbstractUnwindCursor* co = (AbstractUnwindCursor*)cursor; co->jumpto(); return UNW_EUNSPEC; }
`__ZN9libunwind16Registers_x86_646jumptoEv:
void libunwind::Registers_x86_64::jumpto()
On entry, thread_state pointer is in rdi
movq 56(%rdi), %rax # rax holds new stack pointer
subq $16, %rax
movq %rax, 56(%rdi)
movq 32(%rdi), %rbx # store new rdi on new stack
movq %rbx, 0(%rax)
movq 128(%rdi), %rbx # store new rip on new stack
movq %rbx, 8(%rax)
# restore all registers
movq 0(%rdi), %rax
movq 8(%rdi), %rbx
movq 16(%rdi), %rcx
movq 24(%rdi), %rdx
# restore rdi later
movq 40(%rdi), %rsi
movq 48(%rdi), %rbp
# restore rsp later
movq 64(%rdi), %r8
movq 72(%rdi), %r9
movq 80(%rdi), %r10
movq 88(%rdi), %r11
movq 96(%rdi), %r12
movq 104(%rdi), %r13
movq 112(%rdi), %r14
movq 120(%rdi), %r15
# skip rflags
# skip cs
# skip fs
# skip gs
movq 56(%rdi), %rsp # cut back rsp to new location
pop %rdi # rdi was saved here earlier
ret # rip was saved here
`
这里构造了一个新的虚拟栈帧,然后通过 ret 指令跳转到 landing pad 或者之前某个栈帧去执行异常处理或者清理操作。
在上文里我们知道当栈帧清理结束后,会调用 _Unwind_Resume 继续异常处理的过程。_Unwind_Resume 会继续执行 unwinding 的第二个阶段,比较类似从当前位置继续抛异常。
0x60 Objective-C 与 NSException
实际上 Objective-C 也是借用了 C++ 的异常处理机制来实现它的异常处理。当我们执行 -[NSException raise] 时,CoreFoundation 内部会调用到 Objective-C runtime 的 objc_exception_throw,等同于 C++ 的 throw:
`void objc_exception_throw(id obj)
{
struct objc_exception *exc = (struct objc_exception *)
__cxa_allocate_exception(sizeof(struct objc_exception));
obj = (*exception_preprocessor)(obj);
// Retain the exception object during unwinding
// because otherwise an autorelease pool pop can cause a crash
[obj retain];
exc->obj = obj;
exc->tinfo.vtable = objc_ehtype_vtable+2;
exc->tinfo.name = object_getClassName(obj);
exc->tinfo.cls_unremapped = obj ? obj->getIsa() : Nil;
OBJC_RUNTIME_OBJC_EXCEPTION_THROW(obj); // dtrace probe to log throw activity
__cxa_throw(exc, &exc->tinfo, &_objc_exception_destructor);
__builtin_trap();
}
`
而捕获异常使用的 @try / @catch 作用与 C++ 的 try / catch 其实也是一个东西,甚至可以相互替换。
这里要说说内存泄漏的事情,有很多人会说不要在 Objective-C 中使用 NSException 否则会导致内存泄漏。使用不当的确会导致内存泄漏,比如在 MRC 编译模式下,当异常发生时会中断当前函数正常的执行路径,那么那些手动编写的 release 调用就会被跳过。而在 ARC 编译模式下,由于编译器已经有自动生成 retain / release 调用的能力,这等同于 Objective-C 具有了 RAII 的能力,因此编译器也会为每个 Objective-C 方法生成用于执行 release 的 landing pad。
在汇编代码中寻找 landing pad 的方法很简单,直接搜索这个函数中有无 _Unwind_Resume 调用和 ud2 伪指令,如果有,那么大概率这就是用于在异常情况清理栈帧的 landing pad。
不过值得注意的是,只有在 Objective-C++ 中编译器才会默认自动生成 landing pad,在 Objective-C 中则需要手动开启 [-fobjc-arc-exceptions](http://clang.llvm.org/docs/AutomaticReferenceCounting.html#exceptions "-fobjc-arc-exceptions") 选项。
Clang 文档中也提到了,Objective-C 的异常并不像 Java 里的异常那样普遍,一般触发了 NSException 的都是那些严重的错误,通常是程序的逻辑都出现了错误(bug),比如调用了不存在的方法或者 UITableView data source 出现不一致的情况等等。一般来讲,我们不应该静默处理掉这些异常,而是要 let it crash,此时内存泄漏的问题就不大了。但对于很多对稳定性和容错性有要求的程序,出现小范围的异常可能并不影响整体,那么就可以使用 -fobjc-arc-exceptions 选项来防止内存泄漏的产生。
我个人会倾向于不静默处理 NSException,因为 Cocoa 规约中提供了 NSError 来处理常规错误(网络、I/O、编码等不可控因素)。而 Swift 的错误处理则更像 Java 的异常,并且可以比较完美的桥接 NSError,从而让我们写出更优雅的错误处理代码。
这里插个题外话,Swift 的错误处理与 Objective-C、C++ 是有本质区别的。可以认为 Swift 在实现上更像是一种语法糖,我们需要显式处理每个可能的错误,即 Swift 没有 Unchecked Exception。由于错误不会跨栈帧逃逸,带来的好处就是不需要 stack unwinding 了,不管是性能还是代码大小都会得到比较好的控制。
0x60 小结
本文简单地讲述了一下 C++ 中异常处理机制的实现,从一个比较宏观的视角过了一遍整体流程。实际上,libunwind 和 libcxxabi 中还有很多比较复杂的实现机制,比如 UnwindCursor 如何 step,以及 LSDA 的结构和解析方式等等。这些如果展开讲可能就需要比较大的篇幅了,这里我就算是抛砖引玉了吧,感兴趣的朋友可以从这些点着手深入研究一下。
推荐阅读
关注我们
我们是「老司机技术周报」,每周会发布一份关于 iOS 的周报,也会定期分享一些和 iOS 相关的技术。欢迎关注。

关注有礼,关注【老司机技术周报】,回复「2020」,领取学习大礼包。
参考资料
[1]
setjmp / longjmp: https://en.wikipedia.org/wiki/Setjmp.h
[2]
Stack Unwinding: https://en.wikipedia.org/wiki/Call\_stack#Unwinding
[3]
https://libcxxabi.llvm.org/spec.html: https://libcxxabi.llvm.org/spec.html
[4]
Apple Open Source: https://opensource.apple.com/
[5]
dyldExceptions: https://opensource.apple.com/source/dyld/dyld-132.13/src/dyldExceptions.c
[6]
ErrorHandling: https://docs.swift.org/swift-book/LanguageGuide/ErrorHandling.html
[7]
exception-handling-in-c: https://monoinfinito.wordpress.com/series/exception-handling-in-c/
[8]
cxa_exception.cpp: https://code.woboq.org/llvm/libcxxabi/src/cxa\_exception.cpp.html
[9]
libcxxabi: https://libcxxabi.llvm.org/spec.html
[10]
Call_stack: https://en.wikipedia.org/wiki/Call\_stack#Unwinding
[11]
why-does-try-catch-in-objective-c-cause-memory-leak: https://stackoverflow.com/questions/27140891/why-does-try-catch-in-objective-c-cause-memory-leak
[12]
libunwind: https://opensource.apple.com/source/libunwind/libunwind-35.4/
本文分享自微信公众号 - 老司机技术周报(LSJCoding)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。











