
作为工业级的流计算框架,Flink 被设计为可以每天处理 TB 甚至 PB 级别的数据,所以如何高吞吐低延迟并且可靠地在算子间传输数据是一个非常重要的课题。此外,Flink 的数据传输还需要支持框架本身的特性,例如反压和用于测量延迟的 latency marker。在社区不断的迭代中,Flink 逐渐积累了一套值得研究的网络栈(Network Stack),本文将详细介绍 Flink Network Stack 的实现细节以及关键的优化技术。
本文主要基于 Nico Kruber 在去年 9 月 Flink Forward Berlin 上的分享 [1],涉及到的技术主要有 1.5 版本引入的 Credit-based 数据流控制以及在延迟和吞吐方面做的优化。在开始之前,我们首先来回顾下 Flink 计算模型里的核心概念,这写概念会在后续被频繁地提及。
Flink 计算模型
Flink 计算模型分为逻辑层和执行层,逻辑层主要用于描述业务逻辑,而执行层则负责作业具体的分布式执行。
用户提交一个作业以后,Flink 首先在 client 端执行用户 main 函数以生成描述作业逻辑的拓扑(StreaGraph),其中 StreamGraph 的每个节点是用户定义的一个算子(Operator)。随后 Flink 对 StreamGraph 进行优化,默认将不涉及 shuffle 并且并行度相同的相邻 Operator 串联起来成为 OperatorChain 形成 JobGraph,其中的每个节点称为 Vertice,是 OperatorChain 或独立的 Operator。
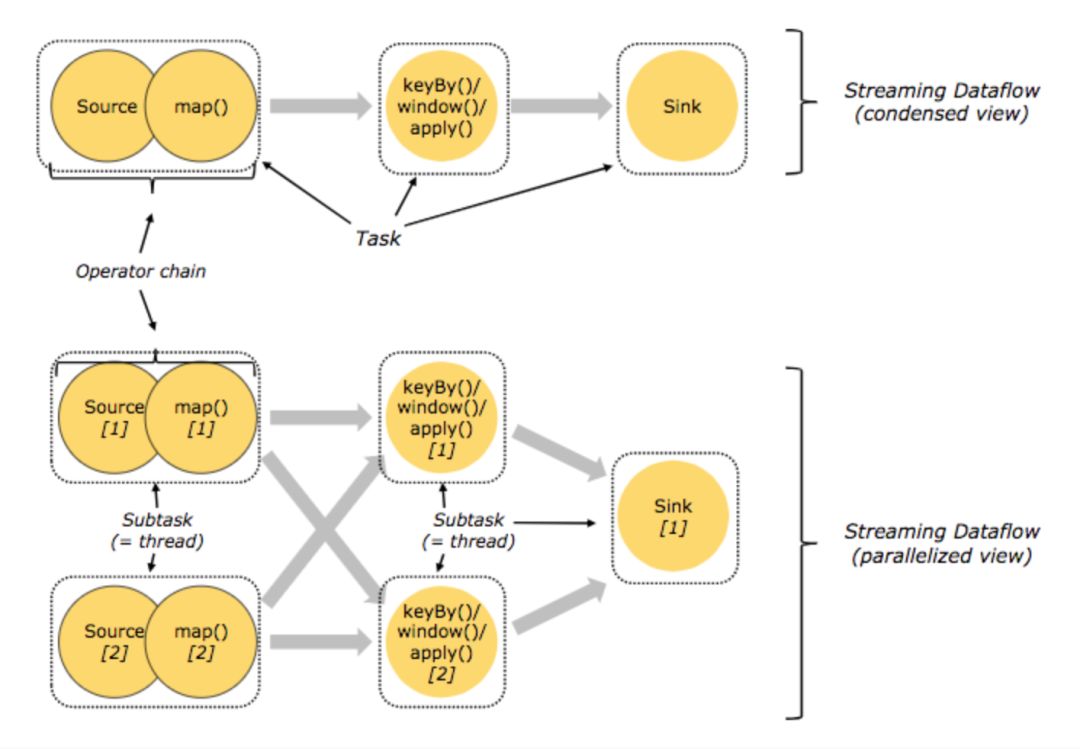
图1.分布式运行时
每个 Vertice 在执行层会被视为一个 Task,而一个 Task 对应多个 Subtask,Subtask 的数目即是用户设置的并行度。Subtask 根据 Flink 的调度策略和具体的部署环境及配置,会被分发到相同或者不同的机器或者进程上,其中有上下游依赖关系的 Subtask 会有数据传输的需要,这是通过基于 Netty 的 Network Stack 来完成的。
Network Stack 主要包括三项内容,Subtask 的输出模式(数据集是否有界、阻塞或非阻塞)、调度类型(立即调度、等待上一阶段完成和等待上一阶段有输出)和数据传输的具体实现(buffer 和 buffer timeout)。
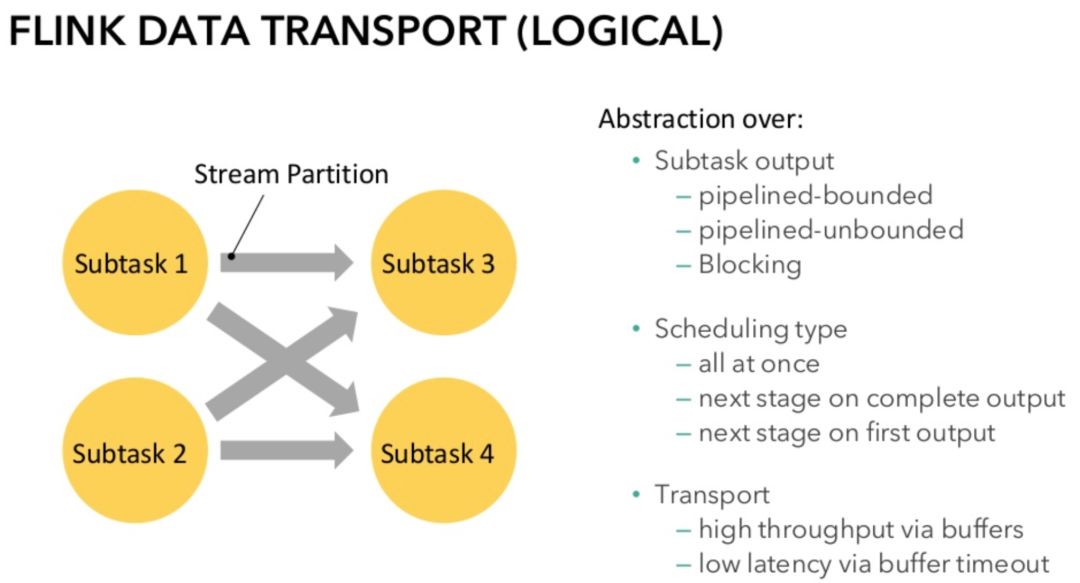
图2.网络栈概览
下文的内容会主要围绕数据传输部分展开,逐一介绍其中的优化技术。
Credit-based 数据流控制
在上文图二左半部分可以看到 Subtask 之间有一条独立的数据传输管道,其实这是逻辑视图,而在物理层 Flink 并不会为维护 Subtask 级别的 TCP 连接,Flink 的 TCP 连接是 TaskManager 级别的。对于每个 Subtask 来说,根据 key 的不同它可以输出数据到下游任意的 Subtask,因此 Subtask 在内部会维护下游 Subtask 数目的发送队列,相对地,下游 Subtask 也会维护上游 Subtask 数目的接收队列。相同两个 TaskManager 上不同的 Subtask 的数据传输会通过 Netty 实现复用和分用跑在同一条 TCP 连接上。
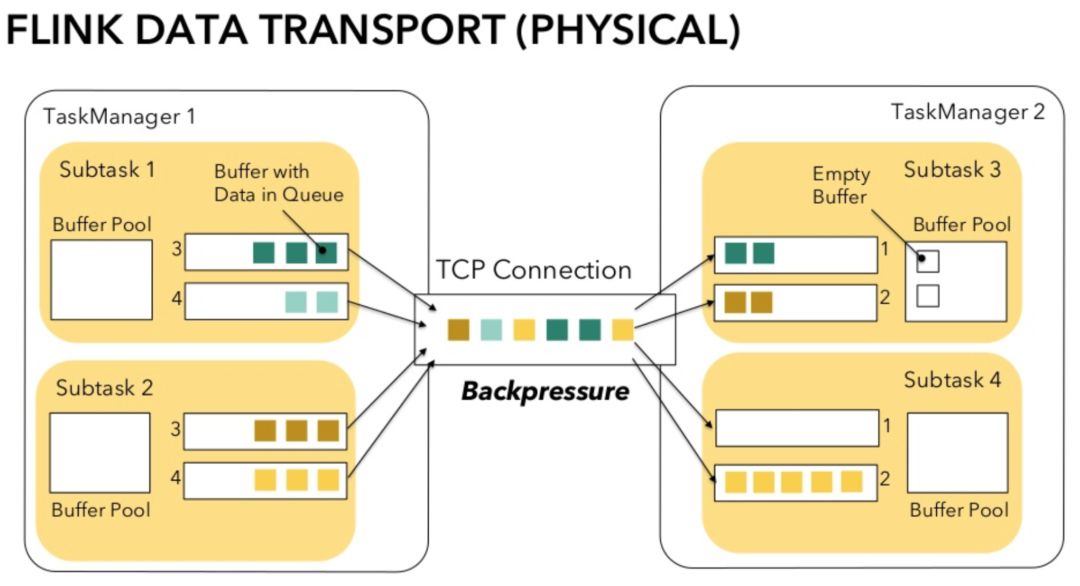
图3.网络传输物理视图
这种实现的问题在于当某个 Subtask 出现反压时,反压不仅会作用于该 Subtask 的 Channel,还会误伤到这个 TaskManager 上的其他 Subtask,因为整个 TCP 连接都被阻塞了。比如在图 3 中,因为 Subtask 4 一个 Channel 没有空闲 Buffer,使用同一连接的其他 3 个 Channel 也无法通信。为了解决这个问题,Flink 自 1.5 版本引入了 Credit-based 数据流控制为 TCP 连接提供更加细粒度的控制。
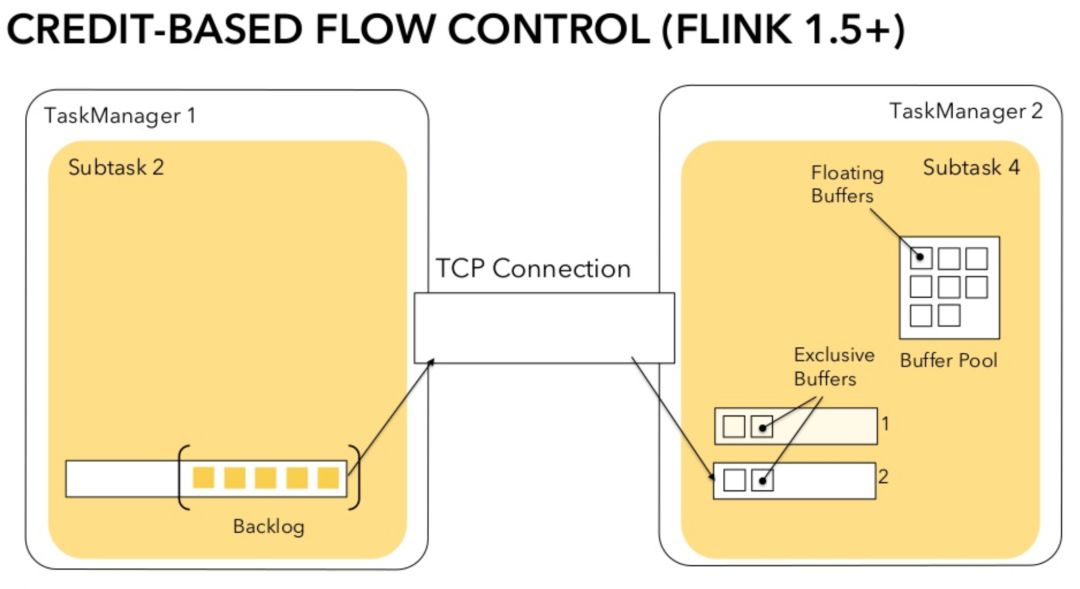
图4.Channel 初始状态
具体来说,在接受端的 Buffer 被划分为 Exclusive Buffer 和 Floating Buffer 两种,前者是固定分配到每条接受队列里面的,后者是在 Subtask 级别的 Buffer Pool 里供动态分配。发送队列里的数据称为 Blacklog,而接收队列里的 Buffer 称为 Credit。Credit-Based 数据流控制的核心思想则是根据接收端的空闲 Buffer 数(即 Credit)来控制发送速率,这和 TCP 的速率控制十分类似,不过是作用在应用层。
假设当前发送队列有 5 个 Blacklog,而接收队列有 2 个空闲 Credit。首先接收端会通知发送端可以发送 2 个 Buffer,这个过程称为 Announce Credit。随后发送端接收到请求后将 Channel Credit 设为 2,并发送 1 个 Buffer(随后 Channel Credit 减为 1 ),并将剩余 4 个 Backlog 的信息随着数据一起发给接收端,这个两个过程分为称为 Send Buffer 和 Announce Blacklog Size。接收端收到 Backlog Size 之后会向 Buffer Pool 申请 Buffer 以将队列拓展至可以容纳 Backlog Size 的数据,但不一定能全部拿到。因为队列目前有一个空闲 Buffer,因此只需要向 Buffer Pool 申请 3 个 Buffer。假设 3 个 Buffer 都成功申请到,它们会成为 Unannounced Credit,并在下一轮请求中被 Announce。
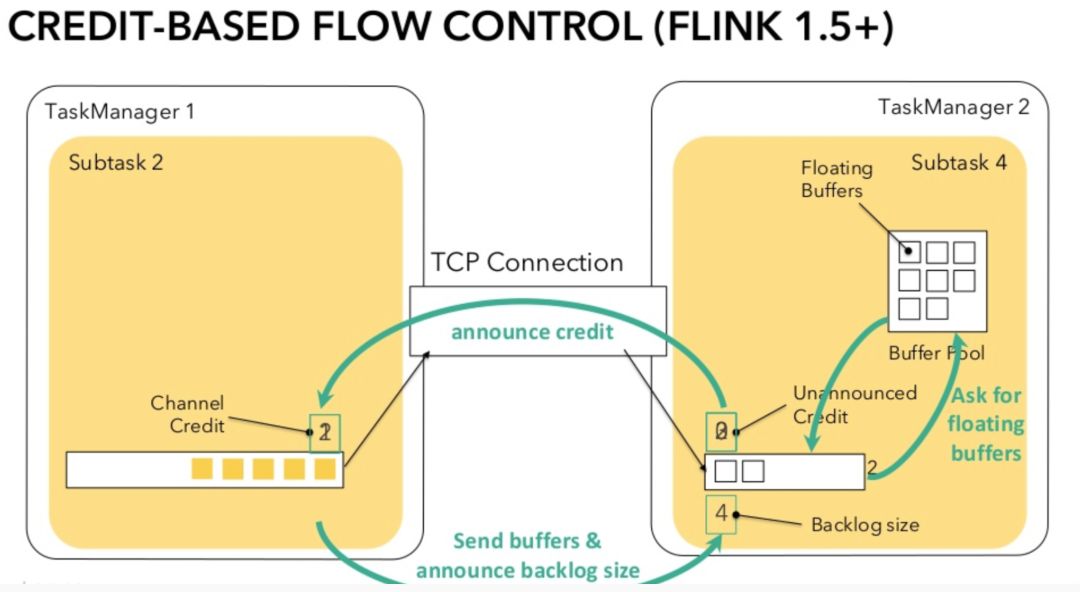
图5.Credit-based 流控制
当一条 Channel 发送端的 Announced Credit 与 接收端的 Unannounced Credit 之和不小于 Blacklog Size 时,该 Channel 处于正常状态,否则处于反压状态。
从总体上讲,Credit-based 数据流控制避免了阻塞 TCP 连接,使得资源可以更加充分地被利用,另外通过动态分配 Buffer 和拓展队列长度,可以更好地适应生产环境中的不断变化的数据分布及其带来的 Channel 状态抖动,也有利于缓减部分 Subtask 遇到错误或者处理速率降低造成的木桶效应。然而这个新的机制也会引入额外的成本,即每传输一个 Buffer 要额外一轮 Announce Credit 请求来协商资源,不过从官方的测试来看,整体性能是有显著提升的。

图6.Credit-based 流控制性能提升
重构 Task Thread 和 IO Thread 的协作模型
熟悉网络传输的同学应该对高吞吐和低延迟两者的 trade-off 十分熟悉。网络是以 batch 的形式来传输数据的,而每个 batch 都会带来额外的空间开销(header 等元数据)和时间开销(发送延迟、序列化反序列化延等),因此 batch size 越大则传输的开销越小,但是这也会导致延时更高,因为数据需要在缓存中等待的时间越久。对于实时类应用来说,我们通常希望延迟可以被限定在一个合理的范围内,因此业界大多数的做法是设置一个 batch timeout 来强制发送低于 batch size 的数据 batch,这通常需要额外设置设置一个线程来实现。
Flink 也不例外。在上图的 TCP 连接发送端是 Netty Server,而接收端是 Netty Client,两者都会有 event loop 不断处理网络 IO。以实时作业为例子,与 Netty 组件直接交互的是 StreamRecordWriter 和 StreamRecordReader (现已被 StreamWriter 和 StreamInputProcessor 代替),前者负责将 Subtask 最终输出的用 StreamRecord 包装的数据序列化为字节数组并交给 Netty Server,后者负责从 Netty Client 读取数据并反序列化为 StreamRecord。
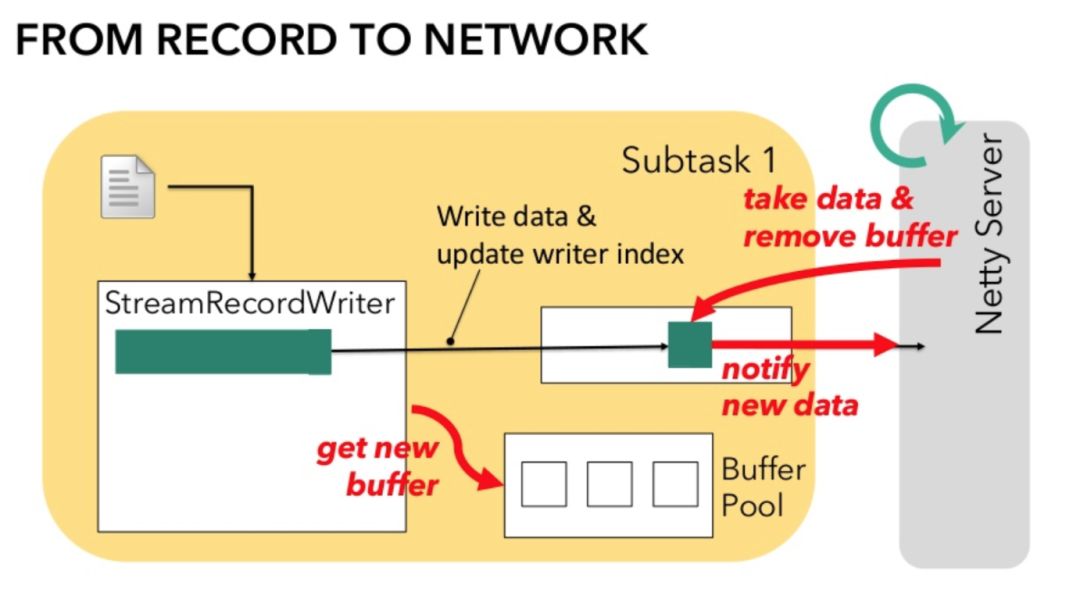
图7.StreamRecordWriter
当发送数据时,StreamRecordWriter 将记录反序列化为字节数组,并拷贝至 Netty Server 的 Channel 的一个 Buffer 中,如果 Buffer 满了它会提醒 Netty Server 将其发送。此后 StreamRecordWriter 会重新从 BufferPool 申请一个空的 Buffer 来重复上述过程,直至作业停止。为了实现 batch timeout,Flink 设置了一个 OutputFlusher 线程,它会定时 flush 在 Channel 中的 Buffer,也就是通知 Netty Server 有新的数据需要处理。Netty Server 会在额外分配线程来读取该 Buffer 到其已写的位置并将相关内容发送,其后该未写满 Buffer 会继续停留在 Channel 中等待后续写入。
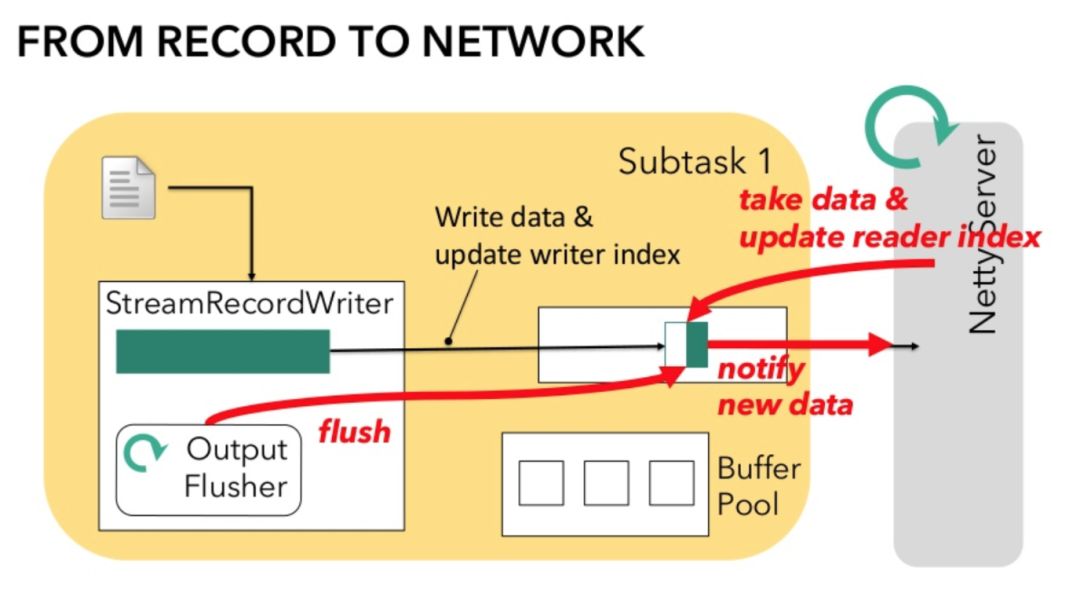
图8.OutputFlusher
这种实现主要有两个问题: 一是 OutputFlusher 和 StreamRecordWriter 主线程在 Buffer 上会有竞争条件,因此需要同步操作,当 Channel 数量很多时这会带来性能上的损耗;二是当我们需要延迟尽可能小时,会将 timeout 设为 0 (实际上提供了 flushAlways 选项),然后每写一条记录就 flush 一次,这样会带来很高的成本,最坏的情况下会造成 Netty Server 频繁触发线程来读取输入,相当于为每个 Buffer 设置一个 event loop。一个简单的优化想法是,既然 Netty Server 本来就有 event loop,为什么不让 Netty 线程自己去检测是否有新数据呢?因此 Flink 在 1.5 版本重构了这部分的架构,弃用了要求同步的 OutputFlusher 线程,改为使用 StreamRecordWriter 和 Netty 线程间的非线程安全交互方式来提高效率,其中核心设计是 BufferBuilder 和 BufferConsumer。

图9.BufferBuilder & BufferConsumer
BufferBuilder 和 BufferConsumer 以生产者消费者的模式协作,前者是会被 StreamRecordWriter 调用来写入 Buffer,后者会被 Netty Server 线程调用,两者通过 volatile int 类型的位置信息来交换信息。通过这种方式,StreamRecordWriter 不会被 OutputFlusher 阻塞,资源利用率更高,网络传输的吞吐量和延迟均可受益。
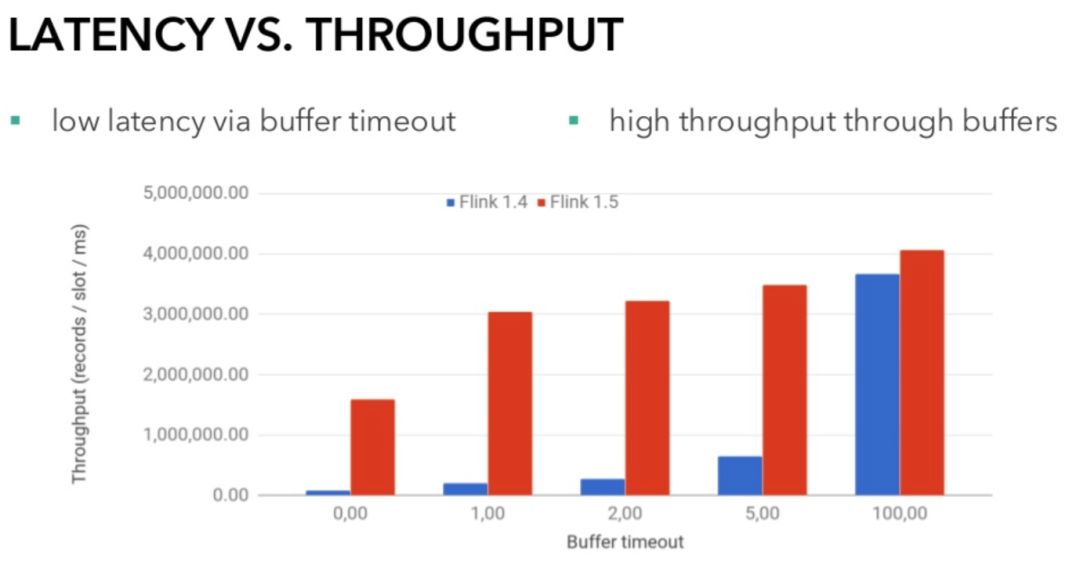
图10.重构前后性能对比
避免不必要的序列化和反序列化
众所周知,序列化和反序列化是成本很高的操作,尤其是对于实时计算来说,因此 Flink 在避免不必要的序列化和反序列化方面做了不少优化工作。
Object Reuse 模式(Stream API)
在作业拓扑优化阶段,Flink 会尽可能将多个 Operator 合并为 Operator Chain 来减少 Task 数,因为 Subtask 内的 Operator 运行在同一个线程,不需要经过网络传输。尽管 Chained Operator 之间没有网络传输,但不同 Operator 直接共享对象实例并不安全,因为对象可能同时被多个算子并发访问造成意想不到的后果,并且按照函数式编程的理念,Operator 不应该对外界造成副作用,一个典型的正面例子就是 Scala 中的 Pure Function [5],因此默认情况下两个 Chained Operator 的数据对象传递是通过深拷贝来完成的,而深拷贝则是通过一轮序列化和反序列实现。不过出于性能考虑,自 Flink 提供了 Object Resue Mode 来关闭 Chained Operator 间的数据拷贝。

图11.Object Reuse Mode
Object Resue Mode 属于高级选项,当使用 Object Reuse 时用户函数必须符合 Flink 要求的规范 [2],比如不能将输入的数据对象存到 State 中,再比如不能在输出对象之后仍对其进行修改。
要注意的是,Object Resue Mode 在 Stream API 中的行为和在 Batch API 中的行为并不完全一致,前者是避免了 Chained Operator 之间的深拷贝,但不同 Subtask 之间(即使在同一 JVM 内)仍然需要深拷贝,而后者是每一步都是复用之前的对象,是真正的意义上的 Object Reuse。为此了统一 Object Reuse 在两个 API 的语义,Flink 社区提出了 FLIP-21 [3],但由于具体方案没有达成共识目前还没有实现的计划。
输出到多个 Channel 时只序列化一次
由于 Flink 维护的 RecordWriter 是 Channel 级别的,当一条数据需要被输出到多个 Channel 时(比如 broadcast),同样的数据会被序列化多次,导致性能上的浪费。因此在 1.7 版本,Flink 将 RecordWriter 的写 Buffer 操作分为将数据反序列化为字节数组和将字节数组拷贝到 Channel 里两步,从而使得多个 Channel 可以复用同一个反序列化结果 [4]。
总结
在版本迭代中,Network Stack 一直在不断改进来适应新的特性或者提高性能。其中在 1.5 版本进行了比较多的改进,包括最重要的 Credit-based 流控制和重构 Task Thread 和 IO Thread 的协作模型。
作为底层基础架构,Network Stack 设计的好坏很大程度上决定了一个计算框架的性能上限,其重要性对于 Flink 开发者或者有意贡献代码的用户而言不必多说。而对于 Flink 用户而言,熟悉 Network Stack 也可以让你在开发阶段提前预计或者部署后及时发现应用的瓶颈,从而在应对生产环境的部署复杂性时更加游刃有余。
参考资料
1.Improving throughput and latency with Flink’s network stack
2.Operating on data objects in functions
3.FLIP-21 - Improve object Copying/Reuse Mode for Streaming Runtime
4.FLINK-9913 - Improve output serialization only once in RecordWriter
4.Pure Functions
本文作者:Paul Lin
本文链接: https://www.whitewood.me
— THE END —

本文分享自微信公众号 - 大数据技术与架构(import_bigdata)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。











