
日常开发中,我们经常会编写一些类似下面示例中的代码:
func writeToFile(fname string, data []byte, mu *sync.Mutex) error {
mu.Lock()
f, err := os.OpenFile(fname, os.O_RDWR, 0666)
if err != nil {
mu.Unlock()
return err
}
_, err = f.Seek(0, 2)
if err != nil {
f.Close()
mu.Unlock()
return err
}
_, err = f.Write(data)
if err != nil {
f.Close()
mu.Unlock()
return err
}
err = f.Sync()
if err != nil {
f.Close()
mu.Unlock()
return err
}
err = f.Close()
if err != nil {
mu.Unlock()
return err
}
mu.Unlock()
return nil
}我们看到这类代码的特点就是在函数中会申请一些资源并在函数退出前释放或关闭这些资源,比如这里的文件描述符 f 和互斥锁 mu。函数的实现需要确保这些资源在函数退出时被及时正确地释放,无论函数的执行流是按预期顺利进行还是出现错误。为此,开发人员需对函数中的错误处理尤为关注,在错误处理时不能遗漏对资源的释放,尤其是有多个资源需要释放的时候,就像上面示例那样,这大大增加了开发人员的心智负担。同时当待释放的资源个数较多时,整个代码逻辑将变得十分复杂,程序可读性、健壮性也随之下降。但即便如此,如果函数实现中的某段代码逻辑抛出 panic,传统的错误处理机制依然没有办法捕获它并尝试从 panic 恢复。
解决上述提到的这些问题正是 Go 语言引入 defer 的初衷。
1. defer 的运作机制
defer 的运作离不开函数,这里至少有两点含义:
- 在 Go 中,只有在函数(和方法)内部才能使用 defer;
- defer 关键字后面只能接函数(或方法),这些函数被称为 deferred 函数。defer 将它们注册到其所在 goroutine 用于存放 deferred 函数的栈数据结构中,这些 deferred 函数将在执行 defer 的函数退出前被按后进先出(LIFO)的顺序调度执行(如下图所示)。
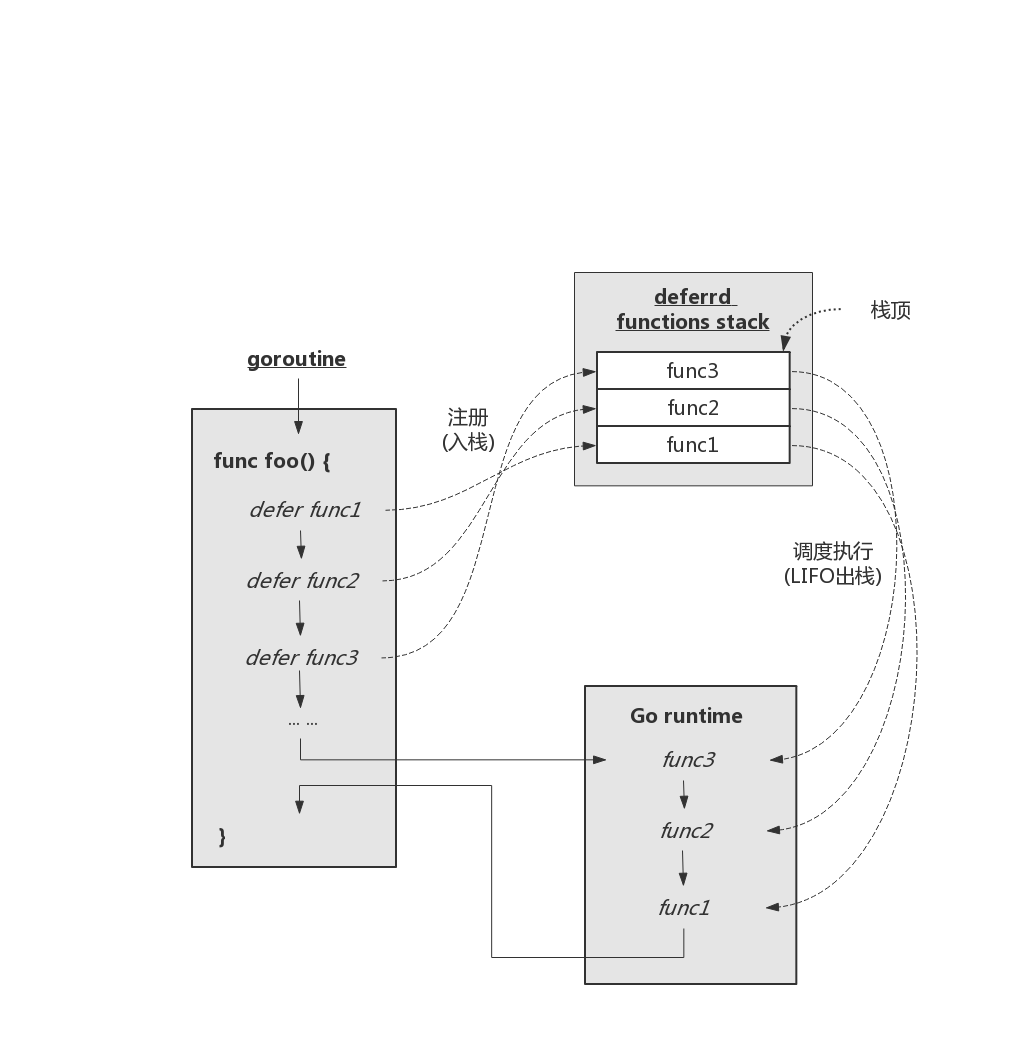
无论是执行到函数体尾部返回,还是在某个错误处理分支显式 return,亦或是出现 panic,已经存储到 deferred 函数栈中的函数都会被调度执行。因此,deferred 函数是一个可以在任何情况下都可以为函数进行收尾工作的好场合。
我们回到本节开头的例子,我们把收尾工作挪到 deferred 函数中,代码变更后如下:
func writeToFile(fname string, data []byte, mu *sync.Mutex) error {
mu.Lock()
defer mu.Unlock()
f, err := os.OpenFile(fname, os.O_RDWR, 0666)
if err != nil {
return err
}
defer f.Close()
_, err = f.Seek(0, 2)
if err != nil {
return err
}
_, err = f.Write(data)
if err != nil {
return err
}
return f.Sync()
}我们看到 defer 的使用对函数 writeToFile 的实现逻辑的简化是显而易见的,资源释放函数的 defer 注册动作紧邻着资源申请成功的动作,这样成对出现的惯例极大降低了遗漏资源释放的可能性,开发人员也因此再也不用小心翼翼地在每个错误处理分支中检查是否遗漏了某个资源的释放动作了。同时,代码的简化又意味代码可读性的提高以及健壮性的增强。
2. defer 的常见用法
除了释放资源这个最基本、最常见的用法之外,defer 的运作机制决定了它还可以在其他一些场合发挥作用,这些用法在 Go 标准库中均有体现。
1) 拦截 panic
在上一小节我们提到过,defer 的运行机制决定了无论函数是执行到函数体末尾正常返回,还是在函数体中的某个错误处理分支显式调用 return 返回,亦或是函数体内部出现 panic,已经注册了的 deferred 函数都会被调度执行。因此,defer 的第二个重要用途就是用来拦截 panic,并按需要对 panic 进行处理,可以尝试从 panic 中恢复(这也是 Go 语言中唯一一种从 panic 恢复的手段),也可以如下面标准库代码中这样,重新 panic,但为新的 panic 传一个新的 error 值:
func makeSlice(n int) []byte {
// If the make fails, give a known error.
defer func() {
if recover() != nil {
panic(ErrTooLarge)
}
}()
return make([]byte, n)
}下面代码则是通过 deferred 函数拦截 panic 并恢复了程序的继续运行:
package main
import "fmt"
func bar() {
fmt.Println("raise a panic")
panic(-1)
}
func foo() {
defer func() {
if e := recover(); e != nil {
fmt.Println("recovered from a panic")
}
}()
bar()
}
func main() {
foo()
fmt.Println("main exit normally")
}
$ go run deferred_func_3.go
raise a panic
recovered from a panic
main exit normallydeferred 函数在 panic 的情况下依旧能够被调度执行的特性让下面两个看似行为等价的函数在 panic 的时候得到不同的执行结果:
var mu sync.Mutex
func f() {
mu.Lock()
defer mu.Unlock()
bizOperation()
}
func g() {
mu.Lock()
bizOperation()
mu.Unlock()
}当 bizOperation 抛出 panic 时,函数 g 无法释放 mutex,而函数 f 则可以释放 mutex,让后续函数依旧可以申请 mutex 资源。
虽然 deferred 函数可以拦截到绝大部分的 panic,但有些 runtime 之外的致命问题也是无法拦截并恢复的,比如下面代码中通过 C 代码”制造“的 crash,deferred 函数便无能为力:
package main
//#include <stdio.h>
// void crash() {
// int *q = NULL;
// (*q) = 15000;
// printf("%d\n", *q);
// }
import "C"
import (
"fmt"
)
func bar() {
C.crash()
}
func foo() {
defer func() {
if e := recover(); e != nil {
fmt.Println("recovered from a panic:", e)
}
}()
bar()
}
func main() {
foo()
fmt.Println("main exit normally")
}执行这段代码我们就会看到虽然有 deferred 函数拦截,但程序仍然崩溃掉了:
SIGILL: illegal instruction
PC=0x409a7f4 m=0 sigcode=1
goroutine 0 [idle]:
runtime: unknown pc 0x409a7f4
... ...2) deferred 函数可以修改函数的具名返回值
下面是 Go 标准库中通过 deferred 函数访问函数具名返回值变量的两个例子:
func (s *ss) Token(skipSpace bool, f func(rune) bool) (tok []byte, err error) {
defer func() {
if e := recover(); e != nil {
if se, ok := e.(scanError); ok {
err = se.err
} else {
panic(e)
}
}
}()
... ...
}
// $GOROOT/SRC/net/ipsock_plan9.go
func dialPlan9(ctx context.Context, net string, laddr, raddr Addr) (fd *netFD, err error) {
defer func() { fixErr(err) }()
... ...
}我们也来写一个更直观的示例:
package main
import "fmt"
func foo(a, b int) (x, y int) {
defer func() {
x = x * 5
y = y * 10
}()
x = a + 5
y = b + 6
return
}
func main() {
x, y := foo(1, 2)
fmt.Println("x=", x, "y=", y)
}运行这个程序:
$ go run deferred_func_5.go
x= 30 y= 80我们看到 deferred 函数在 foo 真正将执行权返回给 main 函数之前将 foo 的两个返回值 x 和 y 分别作了 5 倍和 10 倍放大。
3) deferred 函数可以用于输出一些调试信息
deferred 函数被注册以及调度执行的时间点十分适合用来输出一些调试信息。比如下面 Go 标准库中 net 包中的 hostLookupOrder 方法就使用 deferred 函数在特定日志级别下输出一些日志便于程序调试和跟踪。
func (c *conf) hostLookupOrder(r *Resolver, hostname string) (ret hostLookupOrder) {
if c.dnsDebugLevel > 1 {
defer func() {
print("go package net: hostLookupOrder(", hostname, ") = ", ret.String(), "\n")
}()
}
... ...
}更为典型的莫过于在出入函数时打印留痕日志(一般在调试日志级别下),这里摘录一下 Go 官方参考文档中提供的一个实现:
func trace(s string) string {
fmt.Println("entering:", s)
return s
}
func un(s string) {
fmt.Println("leaving:", s)
}
func a() {
defer un(trace("a"))
fmt.Println("in a")
}
func b() {
defer un(trace("b"))
fmt.Println("in b")
a()
}
func main() {
b()
}4) 还原变量旧值
defer 还有一种比较小众的用法,这用法依旧是来自对 Go 标准库源码的阅读。在 syscall 包下面有这样的一段代码:
func init() {
// do not trigger loading of zipped file system here
oldFsinit := fsinit
defer func() { fsinit = oldFsinit }()
fsinit = func() {}
Mkdir("/dev", 0555)
Mkdir("/tmp", 0777)
mkdev("/dev/null", 0666, openNull)
mkdev("/dev/random", 0444, openRandom)
mkdev("/dev/urandom", 0444, openRandom)
mkdev("/dev/zero", 0666, openZero)
chdirEnv()
}我们看到这段源码的作者利用了 deferred 函数对变量的旧值进行还原:即先将 fsinit 存储在一个局部变量 oldFsinit 中,然后在 deferred 函数中将 fsinit 的值重新置为存储在 oldFsinit 中的旧值。
3. 关于 defer 使用的几个关键问题
绝大多数 Gopher 都喜欢 defer,它让函数变得简洁且健壮。 但”工欲善其事,必先利其器“,一旦要用 defer,有几个关于 defer 使用的关键问题是需要提前了解清楚的,以避免掉进一些不必要的”坑“。
1) 明确哪些函数可以作为 deferred 函数
对于自定义的函数或方法,defer 可以给与无条件的支持,但是对于有返回值的自定义函数或方法,返回值会在 deferred 函数被调度执行的时候被自动丢弃掉。
Go 语言中除了自定义函数/方法,还有 Go 语言内置的/预定义的函数,下面是 Go 语言内置函数的完全列表:
Functions:
append cap close complex copy delete imag len
make new panic print println real recover内置函数是否都能作为 deferred 函数呢?我们看一下下面的示例:
package main
func bar() (int, int) {
return 1, 2
}
func foo() {
// builtin functions:
// append cap close complex copy delete imag len
// make new panic print println real recover
var c chan int
var sl []int
var m = make(map[string]int, 10)
m["item1"] = 1
m["item2"] = 2
var a = complex(1.0, -1.4)
var sl1 []int
defer bar()
defer append(sl, 11)
defer cap(sl)
defer close(c)
defer complex(2, -2)
defer copy(sl1, sl)
defer delete(m, "item2")
defer imag(a)
defer len(sl)
defer make([]int, 10)
defer new(*int)
defer panic(1)
defer print("hello, defer\n")
defer println("hello, defer")
defer real(a)
defer recover()
}
func main() {
foo()
}运行该实例:
go run deferred_func_6.go
# command-line-arguments
./deferred_func_6.go:22:2: defer discards result of append(sl, 11)
./deferred_func_6.go:23:2: defer discards result of cap(sl)
./deferred_func_6.go:25:2: defer discards result of complex(2, -2)
./deferred_func_6.go:28:2: defer discards result of imag(a)
./deferred_func_6.go:29:2: defer discards result of len(sl)
./deferred_func_6.go:30:2: defer discards result of make([]int, 10)
./deferred_func_6.go:31:2: defer discards result of new(*int)
./deferred_func_6.go:35:2: defer discards result of real(a)我们看到 Go 编译器给出一组错误提示!从这组错误提示中我们看到:append、cap、len、make、new 等内置函数是不能直接作为 deferred 函数的,而 close、copy、delete、print、recover 等是可以直接被 defer 注册为 deferred 函数的。
对于那些不能直接作为 deferred 函数的内置函数,我们可以使用一个包裹它的匿名函数来间接满足要求,以 append 为例:
defer func() {
_ = append(sl, 11)
}()但这么做的实际意义是什么是需要开发者自己把握。
2) 把握好 defer 关键字后面表达式的求值时机
牢记一点:defer 关键字后面的表达式是在将 deferred 函数注册到 deferred 函数栈的时候进行求值的。
下面用一个典型的例子来说明一下 defer 后表达式的求值时机:
package main
import "fmt"
func foo1() {
for i := 0; i <= 3; i++ {
defer fmt.Println(i)
}
}
func foo2() {
for i := 0; i <= 3; i++ {
defer func(n int) {
fmt.Println(n)
}(i)
}
}
func foo3() {
for i := 0; i <= 3; i++ {
defer func() {
fmt.Println(i)
}()
}
}
func main() {
fmt.Println("foo1 result:")
foo1()
fmt.Println("\nfoo2 result:")
foo2()
fmt.Println("\nfoo3 result:")
foo3()
}
我们对 foo1、foo2 和 foo3 中的 defer 后的表达式的求值时机做逐一分析:
- foo1 中 defer 后面直接用的是 fmt.Println 函数,每当 defer 将 fmt.Println 注册到 deferred 函数栈的时候,都会对 Println 后面的参数进行求值,根据上述代码逻辑,依次压入 deferred 函数栈的函数是:
fmt.Println(0) fmt.Println(1) fmt.Println(2) fmt.Println(3)
因此,当 foo1 返回后,deferred 函数被调度执行时,上述压入栈的 deferred 函数将以 LIFO 次序出栈执行,因此输出的结果为:3 2 1 0
- foo2 中 defer 后面接的是一个带有一个参数的匿名函数。每当 defer 将匿名函数注册到 deferred 函数栈的时候,都会对该匿名函数的参数进行求值,根据上述代码逻辑,依次压入 deferred 函数栈的函数是:
```go
func(0)
func(1)
func(2)
func(3)因此,当 foo2 返回后,deferred 函数被调度执行时,上述压入栈的 deferred 函数将以 LIFO 次序出栈执行,因此输出的结果为:
3
2
1
0- foo3 中 defer 后面接的是一个不带参数的匿名函数。根据上述代码逻辑,依次压入 deferred 函数栈的函数是:
func()
func()
func()
func()因此,当 foo3 返回后,deferred 函数被调度执行时,上述压入栈的 deferred 函数将以 LIFO 次序出栈执行。匿名函数以闭包的方式访问外围函数的变量 i,并通过 Println 输出 i 的值,此时 i 的值为 4,因此 foo3 的输出结果为:
4
4
4
4鉴于 defer 表达式求值时机的重要性,我们再来看一个例子:
package main
import "fmt"
func foo1() {
sl := []int{1, 2, 3}
defer func(a []int) {
fmt.Println(a)
}(sl)
sl = []int{3, 2, 1}
_ = sl
}
func foo2() {
sl := []int{1, 2, 3}
defer func(p *[]int) {
fmt.Println(*p)
}(&sl)
sl = []int{3, 2, 1}
_ = sl
}
func main() {
foo1()
foo2()
}我们分别分析一下这个实例中的 foo1、foo2 函数:
- foo1 中 defer 后面的匿名函数接收一个切片类型参数,当 defer 将该匿名函数注册到 deferred 函数栈的时候,会对它的参数进行求值,此时传入的变量 sl 的值为[]int{1, 2, 3},因此压入 deferred 函数栈的函数是:
func([]int{1,2,3})
之后虽然 sl 被重新赋值,但是当 foo1 返回后,deferred 函数被调度执行时,deferred 函数的参数值依然为[]int{1,2,3},因此 foo1 输出的结果为:[1 2 3]。
- foo2 中 defer 后面的匿名函数接收一个切片指针类型参数,当 defer 将该匿名函数注册到 deferred 函数栈的时候,会对它的参数进行求值,此时传入的参数为变量 sl 的地址,因此压入 deferred 函数栈的函数是:
func(&sl)
之后虽然 sl 被重新赋值。当 foo2 返回后,deferred 函数被调度执行时,deferred 函数的参数值依然为 sl 的地址,但此时 sl 的值已经变为[]int{3, 2, 1},因此 foo2 输出的结果为:[3 2 1]。
3) 知晓 defer 带来的性能损耗
defer 让 Gopher 在进行资源释放(如文件描述符、锁)的过程变动优雅很多,也不易出错。但在性能敏感的应用中,defer 带来的性能负担也是 Gopher 必须要知晓和权衡的问题。
我们用一个性能基准测试(benchmark)来直观地看看 defer 究竟带来多少性能损耗。
package defer_test
import "testing"
func sum(max int) int {
total := 0
for i := 0; i < max; i++ {
total += i
}
return total
}
func fooWithDefer() {
defer func() {
sum(10)
}()
}
func fooWithoutDefer() {
sum(10)
}
func BenchmarkFooWithDefer(b *testing.B) {
for i := 0; i < b.N; i++ {
fooWithDefer()
}
}
func BenchmarkFooWithoutDefer(b *testing.B) {
for i := 0; i < b.N; i++ {
fooWithoutDefer()
}
}运行该 benchmark 测试,我们得到如下结果:
$ go test -bench . defer_perf_benchmark_1_test.go
goos: darwin
goarch: amd64
BenchmarkFooWithDefer-8 34581608 31.6 ns/op
BenchmarkFooWithoutDefer-8 248793603 4.83 ns/op
PASS
ok command-line-arguments 2.830s从基准测试结果我们可以清晰的看到:使用 defer 的函数的执行时间是没有使用 defer 函数的 8 倍左右。
在 Go 1.13 中,Go 核心团队对 defer 性能做了大幅优化,官方给出了在大多数情况下,defer 性能提升 30%的说法。但笔者的实测结果是 defer 性能的确有提升,但远没有达到 30%这么大的幅度。在 Go 1.14 版本中,defer 性能据说还有大幅提升,让我们拭目以待。
4. 小结
多数情况下,我们的程序对性能并非那么敏感。在这样的情况下,笔者建议 gopher 们尽量使用 defer。defer 让资源释放变得优雅且不易出错,简化了函数实现逻辑,提高了代码可读性,让函数实现变得更加健壮。
本节要点:
- 理解 defer 的运作机制:deferred 函数注册与调度执行;
- 了解 defer 的常见用法;
- 了解 defer 使用的几个关键问题,避免入”坑“。













