
计算机组成
5 乘法器和除法器
5.3 乘法器的优化1

计算机的最大优势在于它的运算速度。因此,当我们设计计算机当中的一个功能部件时,在保证其功能正确性的前提下,就得考虑它是否拥有足够好的性能。那么在这一节,我们就要一起对这个乘法器进行性能上的分析和优化。
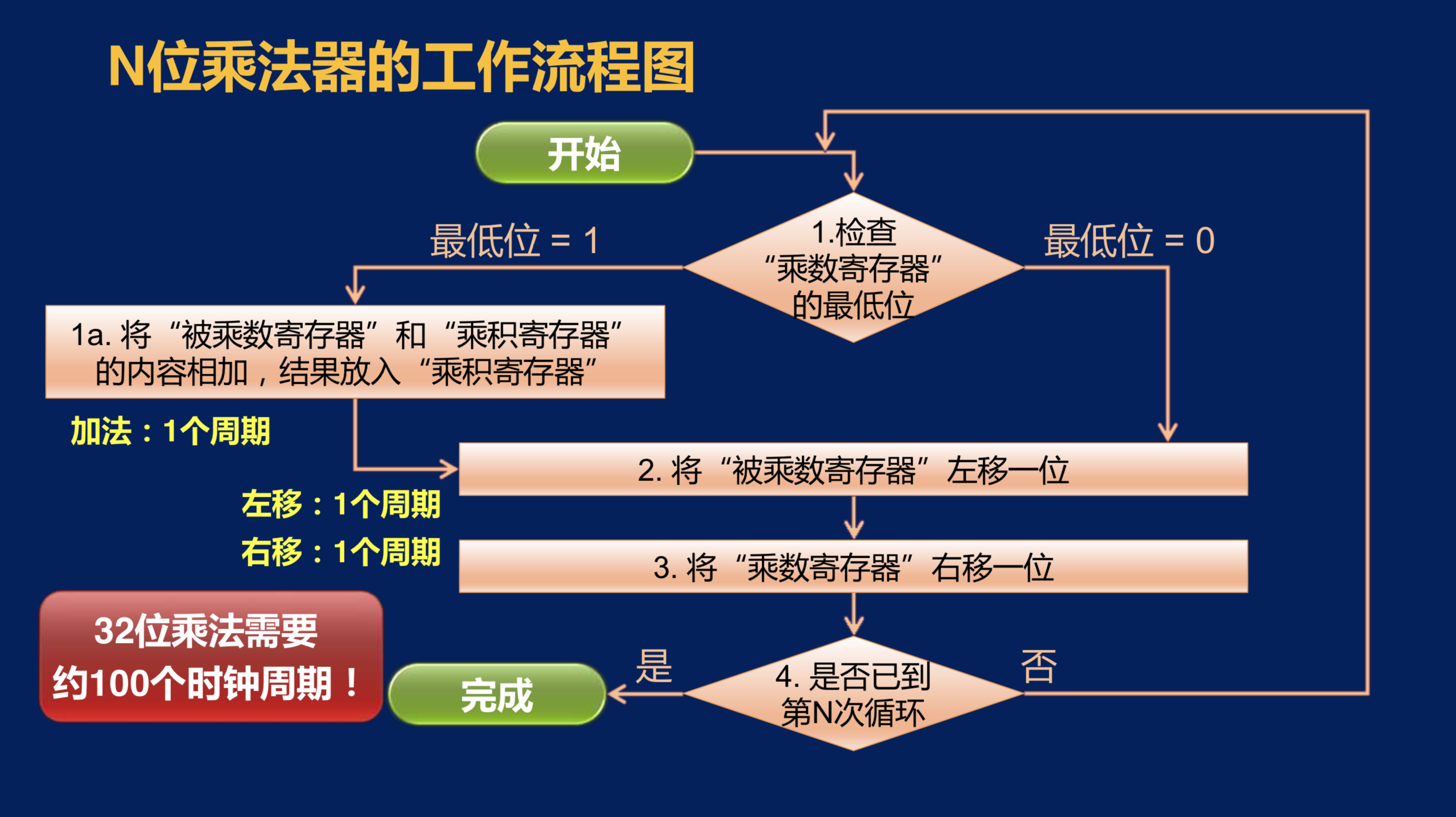
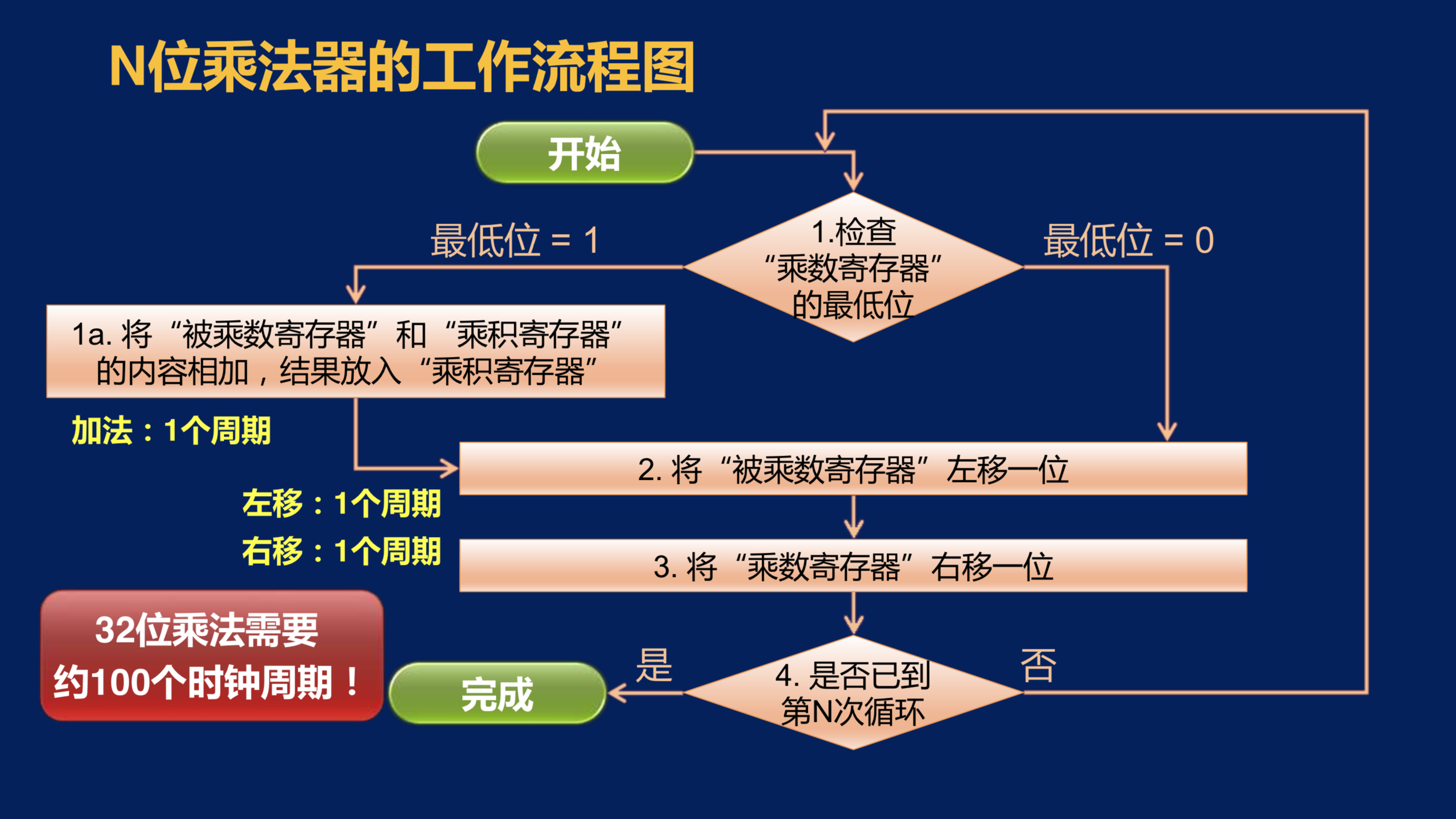
首先,我们来快速回顾一下N位乘法器的工作流程。
当我们做好初始化工作之后,首先检查乘数寄存器的最低位。如果最低位为1,那么就将被乘数寄存器和乘积寄存器的内容相加,并将结果放入到乘积寄存器当中。那么这一步实际上是控制逻辑给出了若干个控制信号,包括让加法器完成加法运算,并给了乘积寄存器写入的控制信号。因为加法器的输出是连接到乘积寄存器的输入端的,所以在下一个时钟上升沿来临的时候,乘积寄存器就会对加法器的输出进行采样并保存起来,这就完成了这一步所指的工作。
然后控制逻辑会向被乘数寄存器发出左移的控制信号,在下一个时钟上升沿来临的时候,被乘数寄存器就会完成左移一位的工作。当然,如果在第一步中检查的乘数寄存器的最低位是0,那控制逻辑就不会给出让加法器进行运算,和让乘积寄存器进行写入的控制信号,而会进入到第2步,完成被乘数寄存器左移的工作。再到下一个时钟上升沿,乘数寄存器会发现其右移的控制信号有效,所以它就完成一次右移的工作。
然后判断是否已经到了第N次循环。如果没有,说明运算还没有结束,再回到第1步继续执行;如果发现已经是第N次循环,说明运算已经完成。运算的结果就在当前的乘积寄存器当中。
我们分析这个工作流程,我们可以发现第1a步执行这个加法,我们需要一个时钟周期;第2步的左移又需要一个时钟周期;第3步的右移还需要一个时钟周期。因此,这个乘法器工作时,每执行一轮都需要3个时钟周期,那如果是一个32位的乘法器,那就大约需要100个时钟周期。(执行的轮数看乘数寄存器的位数)
我们来想一想有没有优化的办法。
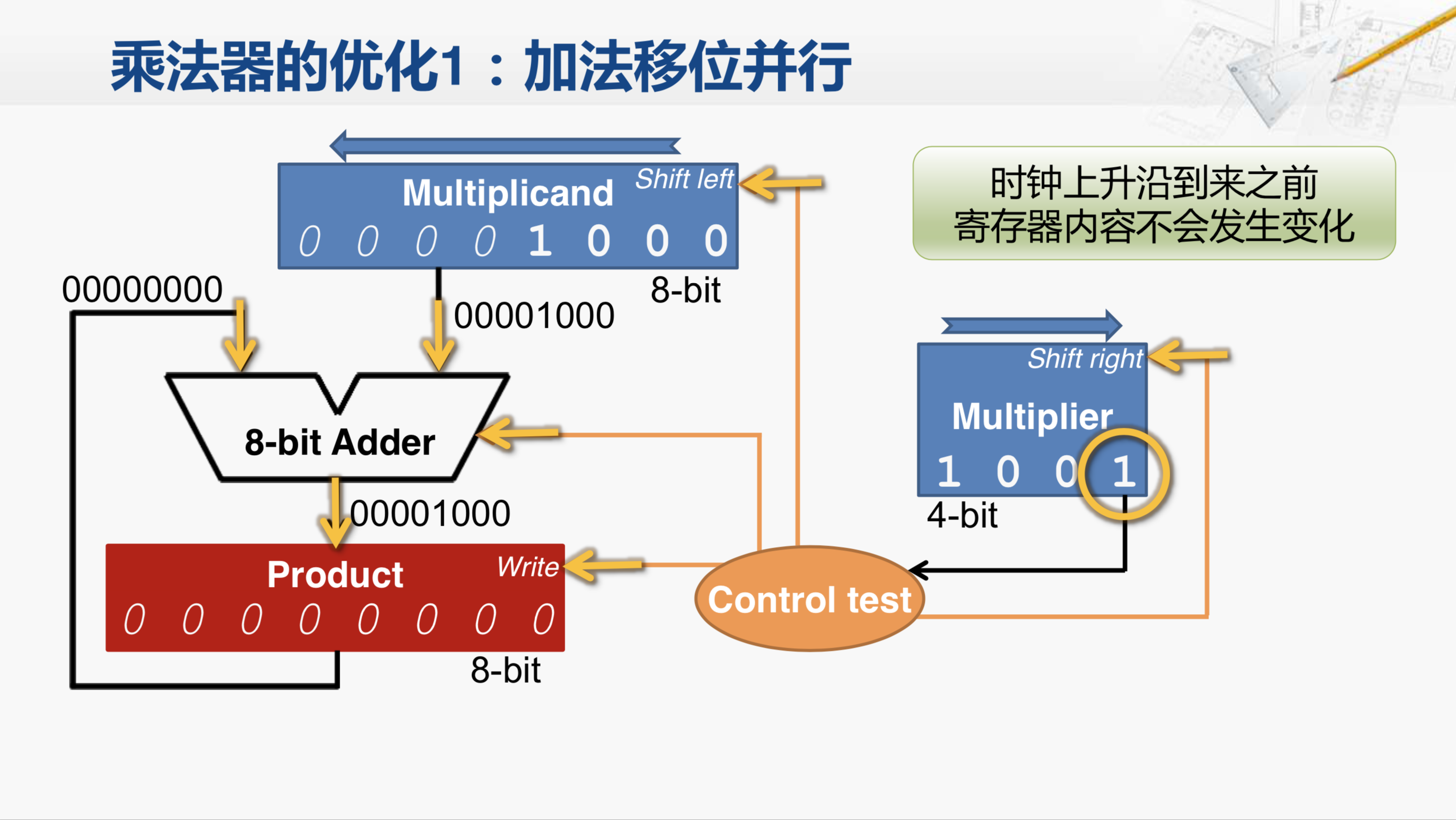
首先,我们很容易想到的优化就是刚才说的这些加法和移位的操作是否能够并行起来。虽然我们在介绍流程时,这些步骤是一步一步进行的,这样只是便于我们理解。在实际的实现上,它们并不需要一定有一个先后的顺序。因此,问题就在于我们的实现结构能否支持让这些加法和移位并行操作。
我们知道,寄存器的内容只会在时钟上升沿来临的时候发生变化,而在其他时候,无论输入端如何变化,寄存器的内容都不会发生变化。因此,我们就用这个乘法器的当前状态为例,进行分析。
假设现在时钟上升沿还没有来临,被乘数寄存器的输出就是它当前所保存的内容 0000 1000 这八位信号会被送到加法器的输入端,而加法器的另一个输入端连接的是乘积寄存器的输出端,因此,成绩寄存器现在的信号值是全0。而当前乘数寄存器的最低位为1,控制逻辑会据此产生相关的控制信号,包括让加法器进行加法运算,这样加法器就会产生对应的运算结果。与此同时,控制逻辑还会给出写输入信号 但是现在时钟上升沿还没有来,所以乘积寄存器其实什么也不会做。那我们注意,在这个时候控制逻辑实际上可以同时给出被乘数寄存器的移位信号,还可以给出乘数寄存器的移位信号,那现在,控制逻辑就将刚才流程图当中的第1a步、第2步和第3步所对应的控制信号都置为有效了,但是因为时钟上升沿还没有来,所以这些寄存器的内容都不会发生变化。
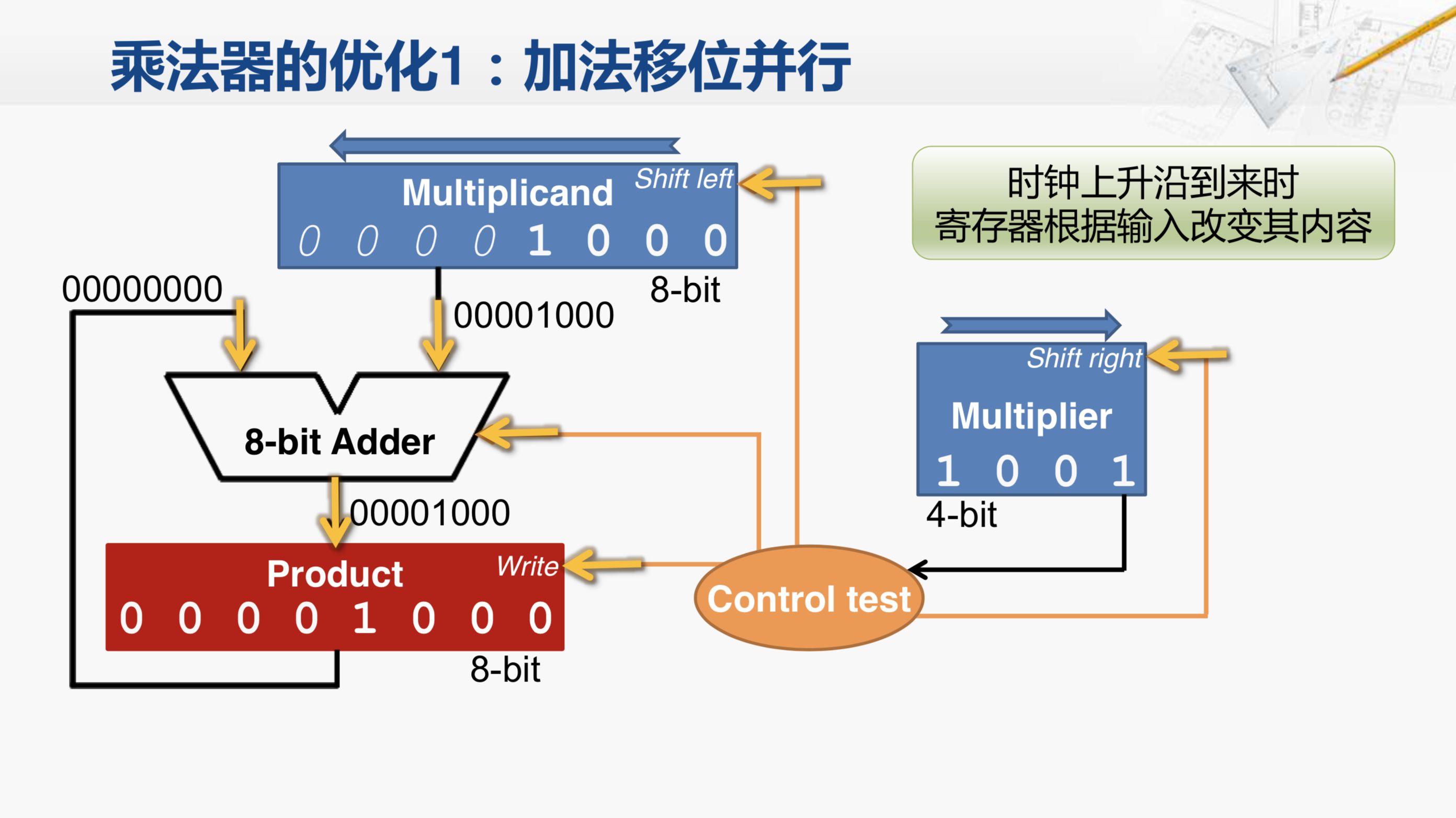
那么当时钟上升沿到来的时候,这些寄存器就会根据输入改变其内容。乘积寄存器会将输入端的数保存起来,被乘数寄存器会向左移动一位,乘数寄存器会向右移动一位。而这些操作都是在同一个时钟上升沿到来的时候完成的。请注意,我们现在假设这个时钟上升沿来了。
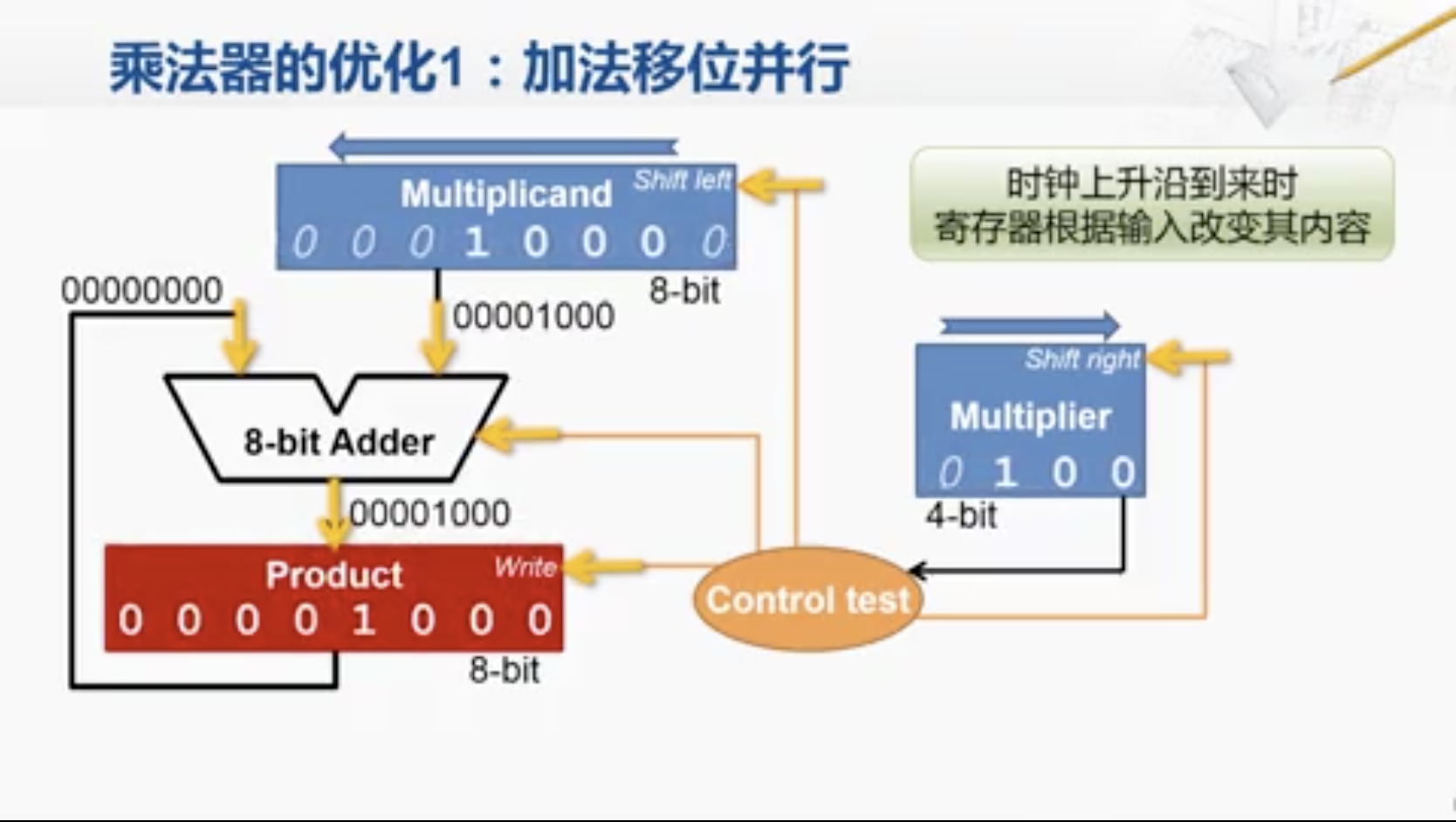
注意观察这3个寄存器它们是同时发生变化的,而且根据我们对寄存器的了解,我们已经知道在时钟上升沿之后很短的一个时间,寄存器所改变的内容就会传送到输出端。因此,我们可以注意到,被乘数寄存器的内容现在已经改变,因此很快它的输出也会变成0001 0000,并传递到加法器,但是,我们可以放心的是,即使这个信号经过了加法器,并产生了新的运算结果,这个运算结果也不会改变乘积寄存器的内容。因为等这个信号传递到了乘积寄存器的输入端时,已经过去了一段时间,这时候乘积寄存器对输入端的采样工作已经完成,其输入端信号的改变不会影响这个寄存器的内容了。这样,我们就在同一个时刻完成了所有的加法和移位的操作。那我们再回到刚才的那个流程图。
在这个流程图当中,这3个顺序执行的操作就可以进行优化。而我们这32位的乘法,也就不应该再需要100个时钟周期了。

经过优化以后的工作流程,在最开始的第1步和最后的第4步,还是跟原来一样。而中间的这3步,我们可以把它并排地放在一起。当第1步检查乘数寄存器的最低位,如果最低位是1的时候,第1a步、第2步和第3步将同时进行;如果最低位为0,则通过控制信号的不同,不执行第1a步,而同时执行第2步和第3步,完成之后就直接进入第4步。这样我们每一次循环只需要一个周期,我们用这个很简单的优化,就把性能提升为了之前的3倍。这样我们就有了一个速度更快的乘法器。

现在,我们已有了一个经过优化后的乘法器了。当然,这个乘法器其实还有很大的性能提升空间,比如说,对于乘法运算,每一个中间结果实际上不需要依赖其它的中间结果的运算,那我们可不可以把所有的中间结果一次性都算出来,然后再将这些中间结果进行相加,而不要经过一轮又一轮的迭代,这样是不是可以更好地提升性能呢?至于具体怎么做就留给你自己分析吧。











