
前言
小伙们好,我是阿沐!一个喜欢通过实际项目实践来分享技术点的程序员!
你们有没有遇到被面试官嘲讽的场景;之前有位刚毕业的小学弟在上海魔都某某某大公司面试,二面主要是问了关于redis的相关知识点,回答的也是磕磕绊绊的,其中一个问题是如何实现搜索附近人加好友功能;想跟大家一起分享、一起探讨下。如果有不正确的地方,欢迎指正批评,共同进步~
面试官的主要考点
- 考点一:面试官考点之Geohash是什么
知识存储量,没用过但是不能不知道 - 考点二:面试官考点之原理与算法
考验算法基本功 - 考点三:面试官考点之redis的geohash的基础命令
考察底子 - 考点四:面试官考点之实现想法与方案
考察思维能力 - 考点五:面试官考点之实际项目应用
实战经验
当你看到面试官想考验你这些知识点的时候;你在面试官问的过程中,就脑海在飞快的转动着,组合一系列的数据场景准备应战。
Geohash概念介绍
geohash就是一种地理位置编码。用来查询附近的POI(POI是“Point of Interest”的缩写,中文可以翻译为“兴趣点”。在地理信息系统中,一个POI可以是一栋房子、一个商铺、一个邮筒、一个公交站等),也是一种算法的思想。
通过将地球看成一个二维的平面图,然后将平面递归切分成更小的模块,然后将空间经纬度数据进行编码生成一个二进制的字符串,再通过base32将其转换为一个字符串。最终是通过比较geohash的值的相似程度查询附近目标元素。
Geohash能实现什么功能?
- 地图导航; 高德地图、百度地图、腾讯地图
- 附近人功能;微信附近人、微信摇一摇、拼夕夕附近人、扣扣附近人
Geohash 算法原理
讲真地,当我要准备讲解原理和算法的时候,也很纠结,毕竟算法不是我的强项且百度一下千篇一律;并且都是大神级人物总结,且不敢妄自菲薄,所以还是站在前人的肩膀上来理解下geohash原理与算法。
“附近的人”也就是常说的 LBS (Location Based Services,基于位置服务),它围绕用户当前地理位置数据而展开的服务,为用户提供精准的增值服务。
“附近的人” 核心思想如下:
① 以“自己”为中心,搜索附近的用户
② 以“自己”当前的地理位置为准,计算出别人和 “我” 之间的距离
③ 按“自己”与别人距离的远近排序,筛选出离我最近的用户或者商店等
那么我们按照我们以往的操作方式:我们在搜索附近人时,会将整个站点的用户信息塞到一个list中,然后去遍历所有节点,检查哪一个节点在自己的范围内;时间复杂度就变成了n*m(n搜索次数,m用户数据)这谁顶得住啊,就是全部放redis一旦数据量上来也顶不住,搜索效率极低。
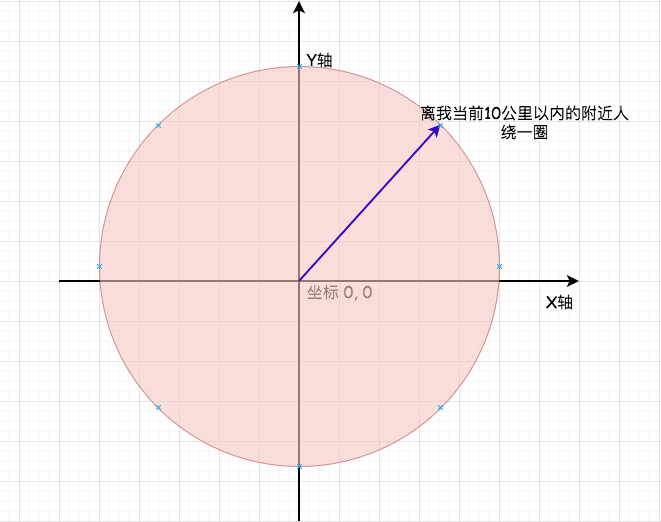
上面大家应该可以看出来吧,其实就是把自己的坐标作为一个中心;哎,然后我们要找到围绕我们方圆10公里以内的附近小伙伴:
X轴:我们可以看做是纬度,左半边范围是-180°~ 0°;右半边是0° ~ 180°
Y轴:我们可以看做是经度,上半边范围是0° ~ 90°;下半边是-90° ~ 0°
原点:我们就看做是(0,0)位置;就好像是我们自己的位置
举例子
假如我们现在地点在广州字节跳动有限公司(广州市天河区珠江东路6号)经纬度是:113.326059(经度),23.117596(纬度)
geohash实质就是将经纬度进行二分法的形式落于相对应的区间中,越分越细一直到趋近于某一个临界值,那么分的层数越多,精确度越准确。
原则是:左区间标注 0;右区间标注 1。
例如我们用代码实现上面经纬度二分法生成的二进制:
/**
* @desc 利用递归思想 找出经纬度的二进制编码
* @param float $place 经度或纬度
* @param string $binary_array 每次递归拿到的bit值
* @param int $max_separate_num递归总次数
* @param array $section 区间值
* @param int $num 递归次数
* @return array
*/
public function binary($place = 0, $binary_array = [], $max_recursion_num = 20, $section = [], $num = 1)
{
if (!$section) return $binary_array;
// 获取中间值
$count = ($section['max'] - $section['min']) / 2;
// 左半边区间
$left = [
'min' => $section['min'],
'max' => $section['min'] + $count
];
// 右半边区间
$right = [
'min' => $section['min'] + $count,
'max' => $section['max']
];
// 假如给点的经纬度值大于右边最小值 则属于右半边区间为1 否则就是左半边区间 0
array_push($binary_array, $place > $right['min'] ? 1 : 0);
// 如果递归次数已经达到最大值 则直接返回结果集
if ($max_recursion_num <= $num) return $binary_array;
// 下一次递归我们需要传入的经纬度 区间值
$section = $place > $right['min'] ? $right : $left;
// 继续针对自身做的递归处理 一直到出现结果
return $this->binary($place, $binary_array, $max_recursion_num, $section, $num + 1);
}
// 实例化调用该方法
require_once './Geohash.php';
$geohash = new Geohash();
echo json_encode($geohash->binary(23.117596,[],$geohash->baseLengthGetNums(4, 1), $geohash->interval[0],1));
//结果集
[1,0,1,0,0,0,0,0,1,1]-> 二进制 101000 00011 这样是不是很清晰
//再看不明白的话 那么久打印出范围值:
[{"min":-90,"max":90},{"min":0,"max":90},{"min":0,"max":45},{"min":22.5,"max":45},{"min":22.5,"max":33.75},{"min":22.5,"max":28.125},{"min":22.5,"max":25.3125},{"min":22.5,"max":23.90625},{"min":22.5,"max":23.203125},{"min":22.8515625,"max":23.203125}]从上面的脚本实现来看是不是更清晰了呢?那么我在使用lua语言给大家实现展示一下,本身原理基本一致:
local cjson = require("cjson")
-- 定义经纬度区间范围
local interval = {
{ min = -90, max = 90 },
{ min = -180, max = 180 }
}
--- @desc 利用递归思想 找出经纬度的二进制编码
--- @param place string 经度或纬度
--- @param binary_array table 每次递归拿到的bit值
--- @param max_separate_num number 递归总次数
--- @param section table 区间值
--- @param num number 递归次数
function binary(place, binary_array, max_recursion_num, section, num)
-- body
place = tonumber(place) or 0
binary_array = binary_array and binary_array or {}
max_recursion_num = tonumber(max_recursion_num) or 20
section = section and section or {}
num = tonumber(num) or 1
if not next(section) then
return binary_array
end
print(cjson.encode(section))
-- 获取中间值
local count = (section["max"] - section["min"]) / 2
-- 左半边区间
local left = {
min = section["min"],
max = section["min"] + count
}
-- 右半边区间
local right = {
min = section["min"] + count,
max = section["max"]
}
-- 假如给点的经纬度值大于右边最小值 则属于右半边区间为1 否则就是左半边区间 0
binary_array[#binary_array+1] = place > right["min"] and 1 or 0
-- 如果递归次数已经达到最大值 则直接返回结果集
if max_recursion_num <= num then
return binary_array
end
-- 下一次递归我们需要传入的经纬度 区间值
local _section = place > right["min"] and right or left
return binary(place, binary_array, max_recursion_num, _section, num + 1)
end
local res = binary(113.326059, {}, _base_length_get_nums(4, 1), interval[2], 1)
print(cjson.encode(res))
//打印结果
{"max":180,"min":-180}
{"max":180,"min":0}
{"max":180,"min":90}
{"max":135,"min":90}
{"max":135,"min":112.5}
{"max":123.75,"min":112.5}
{"max":118.125,"min":112.5}
{"max":115.3125,"min":112.5}
{"max":113.90625,"min":112.5}
{"max":113.90625,"min":113.203125}
[1,1,0,1,0,0,0,0,1,0]我们可以实际手动打一遍执行下,聪明的朋友应该看到一个函数php($geohash->baseLengthGetNums)和lua中(_base_length_get_nums)私有方法,这个是干嘛用的,通过方法注释我们看到大概意思是我们二分层数:
--- @desc 根据指定编码长度获取经纬度的 二分层数
--- @param int $length 编码精确度
--- @param int $type 类型 0-纬度;1-经度
--- @return mixed
local function _base_length_get_nums(length, typ)
-- 第一种方法写死
local list = { {2, 3}, {5, 5}, {7, 8}, {10, 10}, {12, 13}, {15, 15}, {17, 18}, {20, 20}, {22, 23}, {25, 25}, {27, 28}, {30, 30} }
-- 第二种通过规律计算纬度位数组合成list
local cycle_num = 12
local list_res = {}
local lat, lng = 0, 0
for i = 1, 12, 1 do
lat = i % 2 == 0 and lat + 3 or lat + 2
lng = i % 2 == 0 and lng + 2 or lng + 3
list_res[#list_res + 1] = {lat, lng}
end
return list[length][typ]
end🤡 大家是不是还会有疑问,我的天啊,这个list变量哪里来的呀?是不是感觉跟奇怪?下面看下图GeoHash Base32编码长度与精度表格展示:
整体的计算方式:
latitude的范围是:-90° 到 90°
longitude范围是:-180° 到 180°
地球参考球体的周长:40075016.68米| Geohash长度 | Lat位数 | Lng位数 | Lat误差 | Lng误差 | km误差 |
|---|---|---|---|---|---|
| 1 | 2 | 3 | ±23 | ±23 | ±2500 |
| 2 | 5 | 5 | ±2.8 | ±5.6 | ±630 |
| 3 | 7 | 8 | ±0.7 | ±0.7 | ±78 |
| 4 | 10 | 10 | ±0.087 | ±0.18 | ±20 |
| 5 | 12 | 13 | ±0.022 | ±0.022 | ±2.4 |
| 6 | 15 | 15 | ±0.0027 | ±0.0055 | ±0.61 |
| 7 | 17 | 18 | ±0.00068 | ±0.00068 | ±0.076 |
| 8 | 20 | 20 | ±0.000086 | ±0.000172 | ±0.01911 |
| 9 | 22 | 23 | ±0.000021 | ±0.000021 | ±0.00478 |
| 10 | 25 | 25 | ±0.00000268 | ±0.00000536 | ±0.0005871 |
| 11 | 27 | 28 | ±0.00000067 | ±00000067 | ±0.0001492 |
| 12 | 30 | 30 | ±0.00000008 | ±00000017 | ±0.0000186 |
在纬度相等的情况下:
- 经度每隔0.00001度,距离相差约1米;
- 每隔0.0001度,距离相差约10米;
- 每隔0.001度,距离相差约100米;
- 每隔0.01度,距离相差约1000米;
- 每隔0.1度,距离相差约10000米。
在经度相等的情况下:
- 纬度每隔0.00001度,距离相差约1.1米;
- 每隔0.0001度,距离相差约11米;
- 每隔0.001度,距离相差约111米;
- 每隔0.01度,距离相差约1113米;
- 每隔0.1度,距离相差约11132米。
现在是不是一目了然了,规定Geohash长度最大长度是12层,每一层对应位数。哦哦哦!!!原来是这样来的呀,是不是超级简单。我们得到了经纬度的编码之后要干什么?肯定要对其进行组码了:
组合编码:
通过上述计算,纬度产生的编码为10100 00011,经度产生的编码为11010 00010。偶数位放经度,奇数位放纬度,把2串编码组合生成新串:11100 11000 00000 01101。是不是又有点懵了,它是如何组合的呢?下面一张图带你明白它的组合流程:
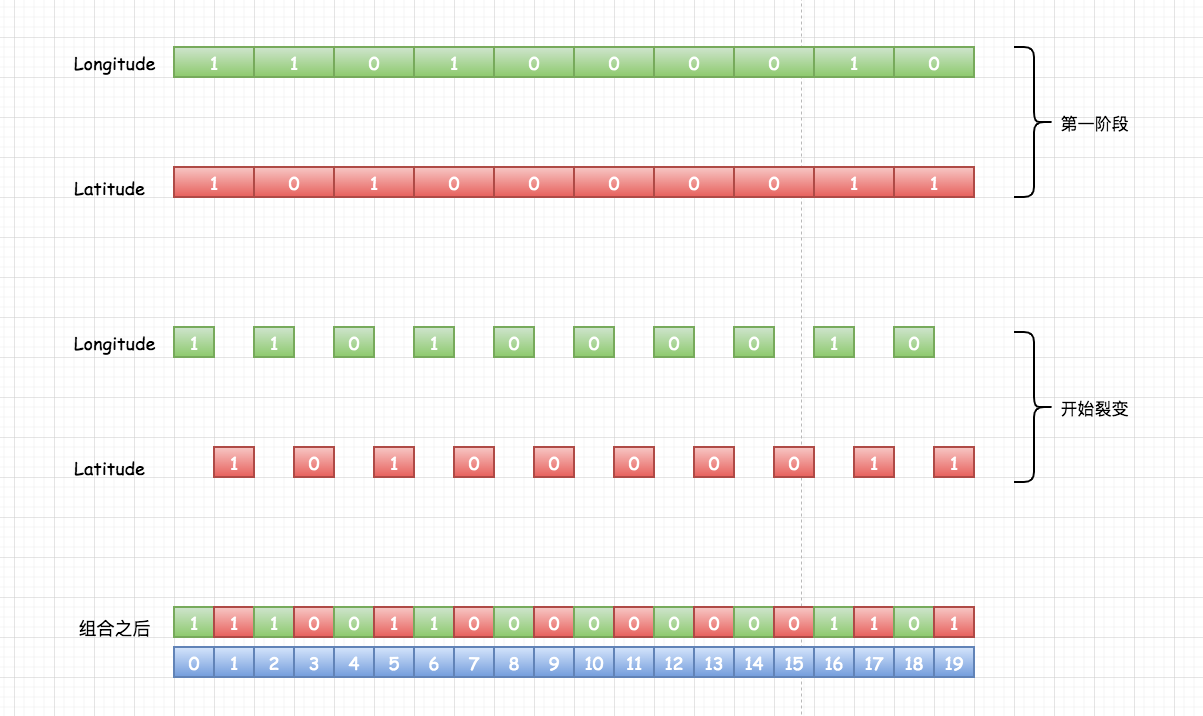
有木有豁然开朗的赶脚,组合就是这么简单;可能有的小伙伴在之阅读很多文章有点迷惑,奇偶交叉组合怎么组合的会有点一头雾水;但是仔细看来就是这么简单啦!
代码实现编码组合
/**
* @desc 编码组合
* @param $latitude_str 纬度
* @param $longitude_str 经度
* @return string
*/
public function combination($latitude_str, $longitude_str)
{
$result = '';
//循环经度数字 作为偶数位置
for ($i = 0; $i < strlen($longitude_str); $i++) {
// 拼接经度作为偶数位置
$result .= $longitude_str{$i};
// 维度存在则拼接字符串
if (isset($latitude_str{$i})) $result .= $latitude_str{$i};
}
return $result;
}
// 结果集
var_dump($geohash->combination('1010000011', '1101000010'));
11100110000000001101function combination(latitude_arr, longitude_arr)
local result = ''
for i = 1, #longitude_arr do
result = result..longitude_arr[i]
if latitude_arr[i] then
result = result..latitude_arr[i]
end
end
return result
end
//结果集
print(cjson.encode(combination({1,0,1,0,0,0,0,0,1,1}, {1,1,0,1,0,0,0,0,1,0})))
11100110000000001101真的到了这时候,将经纬度转GeoHash字符串的工作已经完成了一半了,是不是赶脚超级无敌很简单~
base32算法:用0-9、b-z(去掉a, i, l, o)这32个字母进行base32编码,首先将11100 11000 00000 01101转成十进制,对应着十进制对应的编码就是可以组合成字符串了。我相信学习过编程的小伙们肯定都用过base64编码加解密,但是不确定是否去研究看过怎么加解密的。base32和base64的区别就在于:base32对应的二进制序列是5位,base64对应的二进制序列是6位。
又会有小伙们问了为啥要去掉(a, i, l, o)这四个字母? 有没有疑问的,有的请下方扣1!!!!!- 属于容易混淆的字符,例如:[1, I(大写i), l(小写L)],[0,O];实际编码的时候,也会看错的
- 元音,去除元音防止密码泄露,增加可靠性
编码组合成十进制再转换为字符串
原理:将组合之后的二进制序列每5位一组进行拆分转换;例如:
11100 = 2^4+2^3+2^2 = 16+8+4 = 28 也就是对应w字符串;看下下面对应的维基百科的字典表| decimal(十进制) | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| base32编码 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | b | c | d | e | f | g | h |
| decimal(十进制) | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| base32编码 | j | k | m | n | p | q | r | s | t | u | v | w | x | y | z |
是不是更加清晰明了了,照着对就可以啦;下面是编码实现获取组合字符串(解码这里就不写了,文末会有代码地址):
/**
* @desc 将二进制字符串转为十进制 再转换为对应的编码
* @param $str
* @return string
*/
public function encode($str = '')
{
$string = '';
// 按照5位分割字符串
$array = str_split($str, 5);
if (!$array) return $string;
foreach ($array as $va) {
//二进制转换为十进制
$decimal = bindec($va);
$string .= $this->base_32[$decimal];
}
return $string;
}
// 结果集是ws0e
var_dump($geohash->encode('11100110000000001101'));注意:将经纬度转换成二进制序列的过程中,转换的次数越多,所表示的精度越细,标识的范围越小。
Geohash 实战系列
- 基于mysql实现附近人查询
- 基于mysql + GeoHash实现附近人查询
- 基于redis + GeoHash实现附近人查询
- 基于mongoDB实现附近人查询
- 基于es搜索引擎实现附近人查询(说下方案)
基于mysql实现附近人查询
创建一个用户地理位置上报的表用来存放的经、纬度属性:
CREATE TABLE `user_place` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`user_id` int(10) DEFAULT NULL DEFAULT '0' COMMENT '用户id',
`longitude` double DEFAULT NULL DEFAULT '' COMMENT '经度',
`latitude` double DEFAULT NULL DEFAULT ''COMMENT '纬度',
`create_time` int(10) DEFAULT NULL DEFAULT '0' COMMENT '创建时间',
PRIMARY KEY (`id`),
KEY `idx_longe_lat` (`longitude`,`latitude`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;① 第一种方案:查询附近符合要求的附近人,然后再算距离(实习时用过)
SELECT * FROM `user_place` WHERE (longitude BETWEEN minlng(最小经度) AND maxlng(最大经度)) AND (latitude BETWEEN minlat(最小纬度) AND maxlat(最大纬度))
查询之后结果集之后,通过经纬度计算距离② 第二种方案:直接通过复杂的sql语句计算结果(实习时用过)
// 当前自己的经纬度坐标
$latitude = 23.117596
$longitude = 113.326059
//一系列的复杂计算用到了 mysql中的 三角函数 ASIN函数:反正弦值; POWER函数:用于计算 x 的 y 次方。其他的小伙伴们百度查吧 正弦、余弦
fields = "user_id,ROUND(6378.138*2*ASIN(SQRT(POW(SIN(($latitude*PI()/180-latitude*PI()/180)/2),2)+COS($latitude*PI()/180)*COS(latitude*PI()/180)*POW(SIN(($longitude*PI()/180-longitude*PI()/180)/2),2)))*1000,2) AS distance";
selecet fields from `user_place` having distance <= 10 order by distance asc limit 10
③ 第三方案:mysql的四个内置函数
1、ST_GeoHash(longitude, latitude, max_length -- 生成geohash值
mysql> SELECT ST_GeoHash(116.336506,39.978729,10);
+-------------------------------------+
| ST_GeoHash(116.336506,39.978729,10) |
+-------------------------------------+
| wx4ermcsvp |
+-------------------------------------+
1 row in set (0.00 sec)
2、ST_LongFromGeoHash() -- 从geohash值返回经度
mysql> SELECT ST_LongFromGeoHash('wx4ermcsvp');
+----------------------------------+
| ST_LongFromGeoHash('wx4ermcsvp') |
+----------------------------------+
| 116.33651 |
+----------------------------------+
1 row in set (0.00 sec)
3、ST_LatFromGeoHash() -- 从geohash值返回纬度
mysql> SELECT ST_LatFromGeoHash('wx4ermcsvp');
+---------------------------------+
| ST_LatFromGeoHash('wx4ermcsvp') |
+---------------------------------+
| 39.97873 |
+---------------------------------+
1 row in set (0.00 sec)
4、ST_PointFromGeoHash() -- 将geohash值转换为point值
mysql> SELECT ST_AsText(ST_PointFromGeoHash('wx4ermcsvp',0));
+------------------------------------------------+
| ST_AsText(ST_PointFromGeoHash('wx4ermcsvp',0)) |
+------------------------------------------------+
| POINT(116.33651 39.97873) |
+------------------------------------------------+
1 row in set (0.00 sec)
具体用法其实都差不多的,小伙伴们可以查查相关资料看看!用的不是很多注意:单单基于 mysql 实现 “附近的人”;优点:简单,一张表存储经纬度即可;缺点:数据量比较小时可以使用,同时可以配合redis缓存查询结果集,效果也是ok的;但是数据量比较大的时候,我们可以看到需要大量的计算两个点之间的距离,对性能有很大的影响。(不推荐使用了)
基于mysql + GeoHash实现附近人查询
① 设计思路
在原本存储用户经纬度的表中:入库时计算经纬度对应的geohash字符串存储到表中;那么存储时需要我们明确字符串的长度。
那么我们查询的时候就不需要用经纬度查询,可以这样:select * from xx where geohash like 'geohash%'进行模糊查询,查询到结果集在通过经纬度计算距离;然后筛选指定的距离例如1000m以内,则是附近人。
② 代码实现
-- 先添加字段 geohash
alter table `user` add `geohash` varchar(64) NOT NULL DEFAULT NULL COMMENT '经纬度对应geohash码值',
-- 再添加geohash的普通索引
alter table `user` add index idx_geohash ( `geohash` )
-- 查询sql
select * from `user` where `geohash` like 'geohash%' order by id asc limit 100③ 问题分析
小伙们都知道geohash算法是将地图划分为多个矩形块,然后在对矩形块编码得到geohash字符串。那是不是会出现这种情况,明明这个人离我很近,但是我们又不在同一个矩形块里,那是不是我搜索的时候就搜不到这个人,那不是血亏(万一是一个漂亮的妹子呢)
④ 解决方案
我们在搜索时,可以根据当前的编码计算出附近的8个区域块的geohash码,然后全部拿到,再一个个的筛选比较;这样那个妹子不就被我搜到加好友了嘛!
⑤ 再次实现
-- 例如有一下8个值 geohash1、geohash2、geohash3、geohash4、geohash5、geohash6、geohash7、geohash8
-- 查询sql
select * from `user` where `geohash` regexp 'geohash1|geohash2|geohash3|geohash4' order by id asc limit 100然后查询的结果集进行距离计算,过滤掉大于指定距离的附近人。
基于redis + GeoHash实现附近人查询
① 设计思路
1、查找select指令操作:
1、geopos指令:geopos key member [member ...] 获取指定key里返回所有指定名称的位置(经度和纬度);时间复杂度O(log(n)),n是排序集中的元素数
注意事项:
① geopos命令返回的是一个数组,每个数组中的都由两个元素组成:第一个是位置的经度, 而第二个是位置的纬度。
② 若给定的元素不存在,则对应的数组项为nil(不要搞错以为是一个空数组)。
2、geodist指令:geodist key member1 member2 [m|km|ft|mi] 获取两个给定位置之间的距离;时间复杂度O(log(n)),n是排序集中的元素数
注意事项:
① member1和member2 为两个地理位置名称,例如用户id标识。
② [m|km|ft|mi]尾部参数:
m :米,默认单位
km :千米
mi :英里
ft :英尺
③ 计算出的距离会以双精度浮点数的形式被返回;位置不存在,则返回nil。
3、georadius指令:georadius key longitude latitude radius [m|km|ft|mi] [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC] [STORE key] [STOREDIST key]
根据用户给定的经纬度坐标来获取指定范围内的地理位置集合;时间复杂度: O(n+log(m)),n是圆形区域的边界框内的元素数,该元素由中心和半径定界,m是索引内的项数。
注意事项:
① 以给定的经纬度为中心
② [m|km|ft|mi]单位说明
m :米,默认单位
km :千米
mi :英里
ft :英尺
③ withdist: 在返回位置元素的同时, 将位置元素与中心之间的距离也一并返回。
④ withcoord: 将位置元素的经度和维度也一并返回。
⑤ withhash: 以 52 位有符号整数的形式,返回位置元素经过原始geohash编码的有序集合分值。这个选项主要用于底层应用或者调试, 实际中的作用并不大。
⑥ count 限定返回的记录数。
⑦ asc: 查找结果根据距离从近到远排序。
⑧ desc: 查找结果根据从远到近排序。
4、georadiusbymember指令:georadiusbymember key member radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC] [STORE key] [STOREDIST key]
获取指定范围内的元素数据,中心点是由给定的位置元素决定的,不是使用经度和纬度来决定中心点。时间复杂度: O(n+log(m)),n是圆形区域的边界框内的元素数,该元素由中心和半径定界,m是索引内的项数。
注意事项同上面georadius指令!!!
5、geohash指令:geohash key member [member ...] 获取一个或多个位置元素的geohash值;时间复杂度O(log(n)),n是排序集中的元素数
注意事项:
① 该命令返回的是一个数组格式,位置不存在则返回nil
② 数组结果集的值跟给出位置一一对应,说白了就是下标一致
2、添加insert指令操作:
geoadd指令:geoadd key longitude latitude member [longitude latitude member ...]
添加地理位置的坐标;时间复杂度O(log(n)),n是排序集中的元素数。
注意事项:
① 实际存储的数据类型是zset,member是zset的value,score是根据经纬度计算出geohash
② geohash是52bit的长整型,计算距离使用的公式是Haversine
③ geoadd添加的坐标会有少许的误差,因为geohash对二维坐标进行一维映射是有损耗的大家是不是感觉到有点奇怪,怎么这次的redis命令的时间复杂度都是O(log(n)),这是个啥意思呢?那我们么来一起科普一下:
① O(1)解析:
O(1)就是最低的时空复杂度了,也就是耗时/耗空间与输入数据大小无关,无论输入数据增大多少倍,耗时/耗空间都不变。
② O(n)解析:
比如时间复杂度为O(n),就代表数据量增大几倍,耗时也增大几倍。比如常见的遍历算法。
要找到一个数组里面最大的一个数,你要把n个变量都扫描一遍,操作次数为n,那么算法复杂度是O(n).
③ O(n^2)解析:
比如时间复杂度O(n^2),就代表数据量增大n倍时,耗时增大n的平方倍,这是比线性更高的时间复杂度。比如冒泡排序,就是典型的O(n^2)的算法,对n个数排序,需要扫描n×n次。
用冒泡排序排一个数组,对于n个变量的数组,需要交换变量位置次,那么算法复杂度就是O().
③ O(logn)解析:
比如O(logn),当数据增大n倍时,耗时增大logn倍(这里的log是以2为底的,比如,当数据增大256倍时,耗时只增大8倍,是比线性还要低的时间复杂度),二分查找就是O(logn)的算法,每找一次排除一半的可能,256个数据中查找只要找8次就可以找到目标。
④ O(nlogn)解析:
O(nlogn)同理,就是n乘以logn,当数据增大256倍时,耗时增大256*8=2048倍。这个复杂度高于线性低于平方。归并排序就是O(nlogn)的时间复杂度。 ② 优缺点
- 优点:效率高、实现简单、支持排序。
- 缺点:结果存在误差;若需要精准,则需要手动再筛选一次;大数量情况下,需要解耦缓存。若是集群环境,缓存key不宜过大,否则集群迁移会有问题;所以针对redis要细致解耦缓存,拆分为多个小key
③ 代码实现
/**
* @desc 添加用户地理位置 可以添加多个 大家可以测试下 修改下方法
* @param int $user_id
* @param int $latitude
* @param int $longitude
* @return int
*/
public function insert($user_id = 0, $latitude = 0, $longitude = 0)
{
$result = $this->redis->geoAdd($this->key, $longitude, $latitude, $user_id);
return $result;
}
/**
* @desc 搜索附近人结果集
* @param int $distance
* @param int $latitude
* @param int $longitude
* @return mixed
*/
public function searchNearby($distance = 300, $latitude = 0, $longitude = 0)
{
$result = $this->redis->georadius(
$this->key,
$longitude,
$latitude,
$distance,
'mi',
['WITHDIST','count' => 10,'DESC']
);
return $result;
}
// 调用 获取结果集
$res = new GeoRedis();
var_dump($res->searchNearby(300, 21.306,-157.858));
array(2) {
[0]=>
array(2) {
[0]=>
string(4) "1001" //用户id
[1]=>
string(8) "104.5615" //距离
}
[1]=>
array(2) {
[0]=>
string(4) "1002"
[1]=>
string(8) "104.5615"
}
}那么是不是有小伙伴们问:我要分页可咋办?其实在上面已经给出了答案,使用georadiusbymember命令中的 STOREDIST将排好序的数据存入一个zset集合中,以后分页查直接从zset集合中取数据即可:
localhost:6379> zrange user:nearby 0 10 withscores
1) "1001"
2) "1184565520453603"
3) "1002"
4) "1184565520453603"
5) "1003"
6) "1231646528010636"
7) "1004"
8) "1231732998886639"
9) "1005"
10) "1235058932387089"不过也有点不足的地方,就是我们不能根据筛选条件来直接查询,而是要查询到之后手动过滤;比如我们要查询18岁的美少女附近好友;
① 要么按照搜索条件细化分存储一份数据
② 要么就查询之后过滤
基于mongoDB实现附近人查询
① 设计思路
目前阿沐有一个类似直播项目首页推荐就有一个附近好友的功能;它就是基于MongoDB来实现附近好友功能。主要是通过它的两种地理空间索引2d和2dsphere,这两种索引底层还是基于geohash来构建的。
2dsphere索引支持:球星表面点、线、面、多点、多线、多面和几何集合;创建2dsphere索引语法:
-- 创建索引
db.coll.createIndex({'location':'2dsphere'})
-- 空间查询语法
① 位置相交 db.coll.map.find({'location':{'$geoIntersects':{'$geometry':area}})
② 位置包含 db.coll.map.find({'location':{'$within':{'$geometry':area}})
③ 位置接近 db.coll.map.find({'location':{'$near':{'$geometry':area}})2d索引支持平面几何形状和一些球形查询;支持球面查询但是不太友好,更适合平面查询;创建2d索引语法:
-- 创建索引 索引的精度通过bits来指定,bits越大,索引的精度就越高
db.coll.createIndex({'location':"2d"}, {"bits":30})
-- 查询语法
① 位置包含 db.coll.map.find({'location':{'$within':[[10,10],[20,20]]})
② 矩形包含 db.coll.map.find({'location':{'$within':{'$box':[[10,10],[20,20]]}})
③ 中心包含 db.coll.map.find({'location':{'$within':{'$center':[[20,20],5]}})
④ 多边形包含 db.coll.map.find({'location':{'$within':{'$polygon':[[20,20],[10,10],[10,18],[13,21]]}})
⑤ 位置接近 db.coll.map.find({'location':{'$near':[10,20]})② 代码实现
1、创建数据库,插入几条数据;collection为起名 user(相当于mysql里面的表名)。三个字段user_id用户id,user_name名称,location 为经、纬度数据。
db.user.insertMany([
{'user_id':1001, 'user_name':'阿沐1', loc:[122.431, 37.773]},
{'user_id':1002, 'user_name':'阿沐2', location:[157.858, 21.315]},
{'user_id':1003, 'user_name':'阿沐3', location:[155.331, 21.798]},
{'user_id':1004, 'user_name':'阿沐4', location:[157.331,22.798]},
{'user_id':1005, 'user_name':'阿沐5', location:[151.331, 25.798]},
{'user_id':1006, 'user_name':'阿沐6', location:[147.942428, 28.67652]},
])2、因为我们以二维平面上点的方式存储的数据,想要进行LBS查询,那么还是选择设置2d索引:
db.coll.createIndex({'location':"2d"}, {"bits":30})3、根据自己当前的坐标经纬度查询
db.user.aggregate({
$geoNear:{
near: [157.858, 21.306], // 当前自己坐标
spherical: true, // 计算球面距离
distanceMultiplier: 6378137, // 地球半径,单位是米,默认6378137
maxDistance: 300/6378137, // 过滤条件300米内,需要弧度
distanceField: "distance" // 距离字段别名
}
})4、查看结果集中是否有符合条件的数据,若有数据则会多出刚刚设置的距离字段名distance,表示两点间的距离:
//当前结果集为模拟结果,因本机电脑docker没有安装mongo
{ "_id" : ObjectId("4e96b3c91b8d4ce765381e58"), 'user_id':1001, 'user_name':'阿沐1', "location" : [ 122.431, 37.773 ], "distance" : 5.10295397457355 }
{ "_id" : ObjectId("4e96b5c91b8d4ce765381e51"), 'user_id':1002, 'user_name':'阿沐2', "location" : [ 157.858, 21.315 ], "distance" : 255.81213803417531 }那么到这里是不是对mongo存储经纬度,然后查询附近人获取距离是不是有点了解了;其实性能还是很好地,只不过压力大的时候会出现mongo连接超时,我们可以针对mongo做一个集群;基本上算是比较稳定的了。
基于es搜索引擎实现附近人查询
① 设计思路
其实用es/sphinx/solr等等(后面也会具体聊聊搜索引擎)这类搜索引擎大都能支持查询附近人,因为效率高,查询速度快,而且结果集比较精准;所以还是比较推荐使用这个。
GET api/query/search/
{
"query": {
"geo_distance": {
"distance": "1km",
"location": {
"lat": 21.306,
"lon": 157.858
}
}
}
}大致流程就是这样:① 用户请求查询附近好友 ② 服务端收到请求,然后通过api(http或者rpc)请求上游搜索引擎组的数据 ③ 搜索组拿到请求参数解析查询对应关系链 ④ 高效率返回给调用者
支持分页查询以及更多条件的查询方案;性能优越、可分页;尤其在大数据量的情况下,其性能更友好。阿沐之前公司就是这样处理,类似个性化推荐;通过用户喜好从几百万商品中检索,整个流程也就是服务端请求搜索组接口。搜索组基本上都是Java开发者,由sorl搜索过度elasticcsearch引擎,再加上使用k8s部署es集群;挺好的!!!
仓库代码地址:https://github.com/woshiamu/amu/tree/master/redis
🐣 总结
哇哇哇,能有幸看到这里的小伙伴,我很服气你们了,我花了三天的时间去想去画去构思写好的文章;实话实说,写这篇文章压力挺大的;首先底层的算法原理,再者需要实践验证。网络上都是复制来复制去,我就想着走不一样的路线;既然大家都已经看过那么多跟geohash相关的文章,原理算法应该都ok的;假如我再去纠结讲着写,那岂不是有点自取其辱(大牛们都已经讲的很好了);所以决定通过不同的角度去思考一个问题;以及引发的思考。
本文主要还是通过实践动手结合实际的项目以及过往经验;展示geohash的不同场景下的使用,量级大和量极小怎么选择等等?也通过整理文章时,去解析小伙们会遇到的疑问,这些疑问估计很多文章都没有的,因为都是千篇一律。阿沐要做的就是复杂简单化,能动手实践的绝不只看不练!
座右铭:不管做什么,只要坚持下去就会看到不一样!
好了,我是阿沐,一个不想30岁就被淘汰的打工人 ⛽️ ⛽️ ⛽️ 。创作不易觉得「阿沐」写的有点料话:👍 关注一下,💖 分享一下,我们下期再见。











