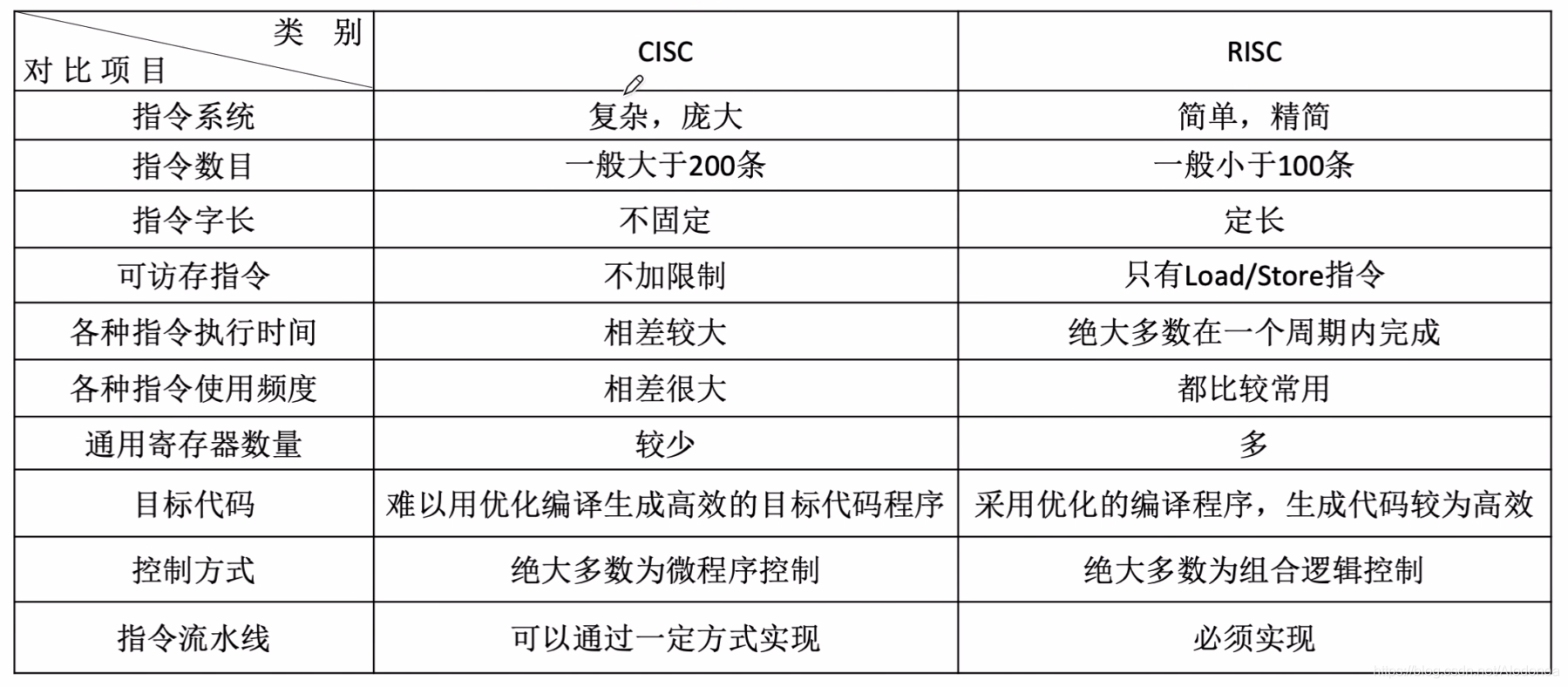
4.1.1指令的基本概念和指令的基本格式
操作码:指明CPU进行什么操作。
地址码:知指明CPU对谁进行操作。
PC:程序计数器,每执行一条指令会+1指向下一条指令。
指令的概念和基本格式:是指一台计算机执行某种操作的命令,一台计算机的所有指令的集合构成指令集,也叫做指令系统,位于计算机的硬件和OS层面。
不同计算机只能执行自己系统的指令,如Intel的x86架构,手机是ARM架构,因此手机App和电脑不互通。
4.1.2指令的分类
4.1.2.1按照地址码数量分类
1)零地址指令:只给出操作码OP,无显式地址,有两种情况:不需要操作数的指令,如空操作,停机,关中断。零地址的运算类指令只用在堆栈计算机中,参与运算的两个操作数隐含在栈顶和次栈顶。计算结果压会栈顶,如栈运算的后缀表达式。

2)一地址指令:只有一个操作数,OP(A1) -> A1,如自加自减求反求补。或者需要两个操作数但其中一个操作数隐含在寄存器如ACC中,(ACC)OP(A1) ->ACC。完成一条一地址指令需要访存三次,取指令->读A1->写A1。

3)二地址指令:有两个操作数,通常为算术运算和逻辑运算相关。(A1)OP(A2)->A1。完成一条一地址指令需要访存四次,取指令->读A1->读A2->写A1。

4)三地址指令:两个操作数,通常为算术运算或者逻辑运算相关。(A1)OP(A2)->A3。完成一条一地址指令需要访存四次,取指令->读A1->读A2->写A3。

5)四地址指令:(A1)OP(A2)->A3。完成一条一地址指令需要访存四次,取指令->读A1->读A2->写A3,执行完指令后。程序计数器的值不是+1,而是指向下一条要执行的指令A4地址。

4.1.2.2按照指令长度分类
半字长指令,单字长指令,双字长指令。这里半字长,单字长,双字长是说指令长度是机器字长的多少倍。 有的计算机是定长指令字结构:所有指令长度都相同。 有的计算机是变长指令字结构:各种指令字长度不同
4.1.2.3按照操作码长度分类
定长操作码:所有指令的操作码长度相同。容易设计但灵活性低。
可变长操作码:各种指令的操作码长度可变。使得控制器的译码器电路设计复杂,但是灵活性高。
4.1.2.4按照操作类型分类
数据传送类型如LOAD,把存储器的数据放到寄存器中,完成了主存和CPU之间的数据传送; 算术逻辑操作如加减乘除等; 移位操作如逻辑移位和算术移位以及循环移位; 转移操作如实现程序执行流如调用和返回会使得PC的数值改变; 输入输出操作如CPU寄存器和IO端口之间的数据传送。 大类上,数据传送是数据传送类型,算术逻辑操作和移位操作是运算类操作,转移操作是程序控制类操作,输入输出操作是输入输出类。
4.1.3定长操作码格式
定长操作码,指令在指令的最高位分配固定若干位表示操作码,n位操作码的指令最大可以表示2^n^位条指令,定长操作码可以提高计算机指令译码和识别速度。
4.1.4可扩展操作码指令格式
定长指令字结构+可变长操作码 -> 扩展操作码指令格式。
假设下列一种情况,指令字长16位,每个地址码4位
三地址指令: 操作码为16 - 4 * 3 = 4位,若全部用于三地址指令,则2^4^ = 16条,若还需要设计其他指令如二地址和一地址以及零地址,需要把操作码为1111的情况留作扩展操作码使用,则三地址指令为0000~1110间15条。
操作码为16 - 4 * 3 = 4位,若全部用于三地址指令,则2^4^ = 16条,若还需要设计其他指令如二地址和一地址以及零地址,需要把操作码为1111的情况留作扩展操作码使用,则三地址指令为0000~1110间15条。
二地址指令:
 操作码为8位,情况同上,只能1111 0000 ~ 1111 1110间15条指令。计算方式同上。
操作码为8位,情况同上,只能1111 0000 ~ 1111 1110间15条指令。计算方式同上。
一地址指令:
 操作码为12位,情况同上,只能1111 1111 0000 ~ 1111 1111 1110间15位。计算方式同上。
零地址指令:
操作码为12位,情况同上,只能1111 1111 0000 ~ 1111 1111 1110间15位。计算方式同上。
零地址指令:
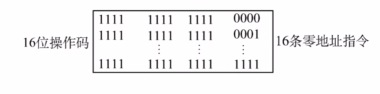 操作码为16位,1111 1111 1111 0000 ~ 1111 1111 1111 1111间16位。此时不再需要留出一条作为扩展操作码使用。当然了,若指令长位32位或者更长,操作码还可以扩展的话,那就是1111 1111 1111 0000 ~ 1111 1111 1111 1110间15位了,情况以此类推。
操作码为16位,1111 1111 1111 0000 ~ 1111 1111 1111 1111间16位。此时不再需要留出一条作为扩展操作码使用。当然了,若指令长位32位或者更长,操作码还可以扩展的话,那就是1111 1111 1111 0000 ~ 1111 1111 1111 1110间15位了,情况以此类推。
关于扩展操作码格式需要注意事项: 不允许短码是长码的前缀,如,二地址指令的操作码前4位是1111,三地址指令的操作码不能是1111,否则CPU就不能识别。 各指令操作码不能重复,否则也会使得CPU无法识别。
关于扩展操作码,CPU识别的过程:
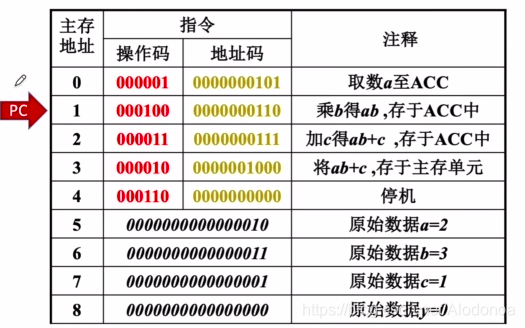 这里仍然使用讲义截图,使得PC先指向0,假设16位长度指令,操作码为4位二进制,地址码为12位二进制。CPU可以识别到第一条指令操作码是0000,是三地址指令,CPU中程序计数器(PC)识别到该程序是取变量a到ACC中,执行完毕PC+1;
此时要执行第二条指令,假设第二条指令是二地址指令且后续还有一地址指令,那么正常情况,操作码应该是1111 0000 ~ 1111 1110,CPU会先识别到前四位是1111,再继续识别后面四位,如果后四位不是1111而是0000 ~ 1110,则该指令是二地址指令,如果后面四位是1111,则是一地址指令1111 1111 0000 ~ 1111 1111 1111,若第二条指令操作码变成1110 0000,因为1110与三地址指令的操作码相同,CPU中PC就会把第二条指令读取到前四位1110结束,不再读取后面操作码,当作三地址指令去执行,然而实际上地址码只有8位,执行会出错。
后续指令执行的过程也相同,可以自行画图推理。
这里仍然使用讲义截图,使得PC先指向0,假设16位长度指令,操作码为4位二进制,地址码为12位二进制。CPU可以识别到第一条指令操作码是0000,是三地址指令,CPU中程序计数器(PC)识别到该程序是取变量a到ACC中,执行完毕PC+1;
此时要执行第二条指令,假设第二条指令是二地址指令且后续还有一地址指令,那么正常情况,操作码应该是1111 0000 ~ 1111 1110,CPU会先识别到前四位是1111,再继续识别后面四位,如果后四位不是1111而是0000 ~ 1110,则该指令是二地址指令,如果后面四位是1111,则是一地址指令1111 1111 0000 ~ 1111 1111 1111,若第二条指令操作码变成1110 0000,因为1110与三地址指令的操作码相同,CPU中PC就会把第二条指令读取到前四位1110结束,不再读取后面操作码,当作三地址指令去执行,然而实际上地址码只有8位,执行会出错。
后续指令执行的过程也相同,可以自行画图推理。
通常情况下,执行频率高的指令,会分配较短的操作码,使得译码器译码和分析时间减短;执行频率较低的指令,会分配较长的操作码。
讲义中还附上了另一种指令设计的思路
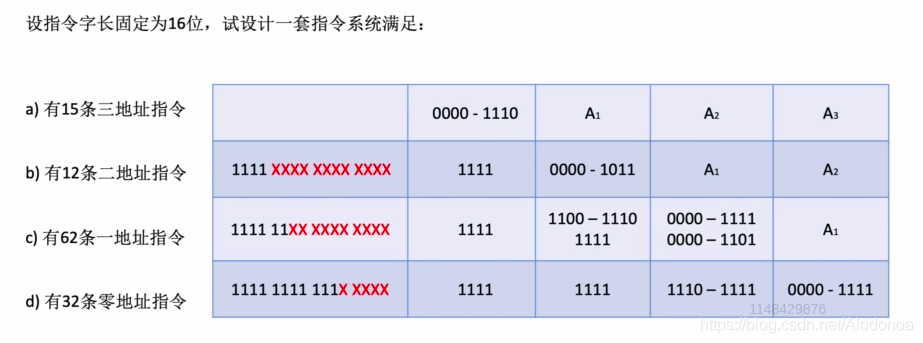 这里的设计思路,一地址指令A1中的1100 ~ 1110与A2中的0000 ~1111对应,A1中1111与A2中0000 ~ 1101对应。零地址指令同上。
这里的设计思路,一地址指令A1中的1100 ~ 1110与A2中的0000 ~1111对应,A1中1111与A2中0000 ~ 1101对应。零地址指令同上。
这里还有一个需要注意的公式,对于扩展操作码,假设地址长度为n,上一层留出m种状态,下一层可以扩展出m * 2^n^种状态。

求点赞!求鞭策!