

正文字数:4204 阅读时长:6分钟
AI就像一个加速器,正在渗透在多媒体应用的方方面面,改进甚至颠覆传统的图像视频处理方法。本文整理自腾讯云高级研发工程师刘兆瑞在LiveVideoStackCon 2020北京站上的演讲,将从超低码率压缩场景下AI技术在前置处理中的优化、AI技术的画质修复探索以及智能编辑场景的落地实践三个方面展开。
文 / 刘兆瑞
整理 / LiveVideoStack
大家好,首先非常荣幸有机会收到LiveVideoStack邀请来和大家分享腾讯视频云在AI视觉上的落地实践与应用,以及AI视觉泛化应用过程遇到的机遇和挑战。
首先简单做个自我介绍,加入腾讯以后,就一直在腾讯视频云工作,早先负责PSTN云通信平台,之后进行极速高清转码平台的研发工作,与此同时也针对视频的场景和特性进行编码器的优化。现在主要负责腾讯明眸(画质修复、画质增强)的研发工作,该工作与腾讯多媒体实验室联合研发,已经在腾讯视频云上得到比较好的落地与应用。
今天分享的内容更多以一个工程师的角度,和大家分享我们是如何把AI视觉真正的落地,应用在广泛、海量的视频处理过程中。所以在技术选型上,可能不会去选择目前state of the art的技术,更多会考虑模型的稳定性、泛化能力以及资源的消耗、成本。接下来的分享是我们在实际落地过程中遇到的问题、踩过的坑,以及我们的一些trick。希望能为做类似业务落地的同学提供一定的参考。
上图是腾讯视频云在直播点播媒体处理、智能编辑等方面的产品矩阵,可以看到,无论是直播、点播中应用的视频压缩和画质修复技术,还是智能编辑中应用的审核、识别、标签等技术,都离不开AI的支持。
0 1
极速高清,视频压缩的挑战
近年来,视频编码领域也是在飞速发展,从H264编码标准到现在的H265再到AV1。但是从实际用户的使用情况观察,目前H264标准依旧是主流,甚至90%以上的用户还在使用H264。其实,H264已经是十几年前的标准,有很多可以优化的痛点,我们希望可以结合AI技术,使H264在当前标准的基础上,获得新的编码压缩增益。
1.1 极速高清,单一视频的极致压缩
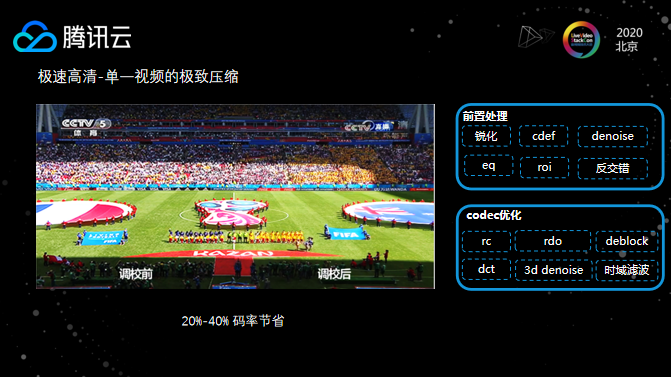
首先简单对腾讯云极速高清产品做个定义,简单而言它是一个结合了前置处理、编码器优化的整体视频压缩解决方案。给客户提供更低码率的同时,保证主观感受不变差,甚至更好的主观感受。
提到压缩肯定离不开编码器,从编码器角度来说,目前x264其实是非常成熟、优秀的编码器,但它仍然存在一定优化空间,比如x264是通用的编码器,不会针对一些垂直领域去做调优,但对于云服务的一些垂直场景,编码器内部还有很多可以调试优化的地方。在不同垂直品类的视频场景,我们在码率控制、rdo分析、deblock滤波等等编码器内部都做了新的编码工具。同时视频源的质量也是参差不齐的,所以针对不同质量的视频源会进行锐化、去噪等辅助操作。极速高清方案整体压缩下来,与普通转码相比会有额外20%-40%的码率节省。
1.2 场景分类,海量视频的分类压缩
但是对于云上业务,每天转码海量的视频,我们不可能针对每个视频tune编码特性和参数,而我们在编码器上很多优化的编码工具都是针对垂直场景,如果使用场景不匹配,会出现一定的反效果。所以针对不同场景、不同品类,和编码团队配合,更好的使用编码工具是非常有意义的一件事。

上图是一个简单的直观对比,左边两张图像使用同样的锐化强度处理,但游戏场景会有失真的情况。从编码器的对比来看,如果你使用同样crf35的编码强度去压缩,可以发现大逃杀类游戏已经产生了大量模糊,但秀场视频还能够保持不错的质量感官。
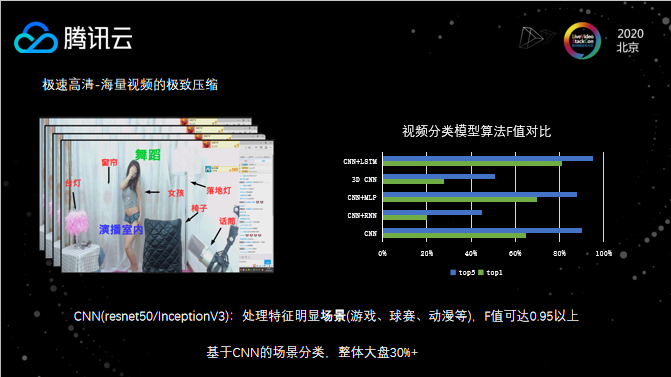
前面提到视频场景分类的必要性,我们在场景分类的模型选择上是基于CNN的,主要是考虑CNN模型已经非常成熟、稳定,同时资源的消耗也比较低,速度能够达到我们实时的需求。此外,CNN在推理过程中使用CPU就可以达到我们的要求,这也是一个非常诱人的优点,毕竟在很多情况下,GPU资源还是相对比较稀缺。
1.3 基于AI的辅助压缩

我们通过场景分类来更好的利用编码特性和工具,但我们也知道在编码中没有极限,尤其是To B服务要满足客户的各类需求。比如实际场景中的一个例子,源是非常复杂的高动态的MV类视频,需要输出720P@30fps,并且压缩到500Kbps以下,同时因为播放端等因素限制,必须使用H264编码。上图是使用x264编码器在slow复杂度下压缩出来的效果,可以看到这个压缩出来的结果还是比较差。

下面跟大家分享下,我们对于这个问题的尝试和思考过程。我们知道码率、质量和分辨率之间是有一个间隔交错的区间,也就是说在码率非常低的情况下,低分辨率的质量(视觉效果)可能会优于高分辨率。从原理上来看,低分辨率和高分辨率相比,细节信息是更少的。用低码率来压缩高分辨率视频,会出现非常多的块效应。而低分率视频对人眼的感官来说只是模糊、不够清晰。因此可以通过一些模糊、去噪的手段,主动减少一些视频细节。这样处理后,整个视频的块效应变少了,当然也会带来额外的模糊效应。从客观指标来看(PSNR、SSIM、VMAF),各个指标都有比较大的降低,虽然主观有一定提升,但从客观指标和整体方案来看,并不完美。

首先分析下模糊方案的缺点,模糊去噪的处理过程中,并不知道编码器的倾向喜好,会按照去噪算法统一的磨平细节,而没有考虑编码过程。所以我们思考是否可以基于AI视觉的技术,做一个reduce artifact的filter。我们希望这个filter能够主动磨掉一些细节,使视频和编码器有更好的亲和性,也就是说这个视频会更容易被编码器压缩,与此同时它不会把人眼关注的、明显的边缘磨掉,也就是在保证主体清晰度的前提下,编码客观指标也不会大幅下降。我们在模型训练的过程中,引入了编码过程,shuffle后还原的图像不直接计算loss,而是进行一次视频压缩,用压缩后的图像来计算loss。低码率压缩时,先经过reduce artifact处理,再进行转码,画面的人眼感官会有一个显著的提升。
02
腾讯明眸—永恒的追求,画质提升
2.1 视频超分辨率
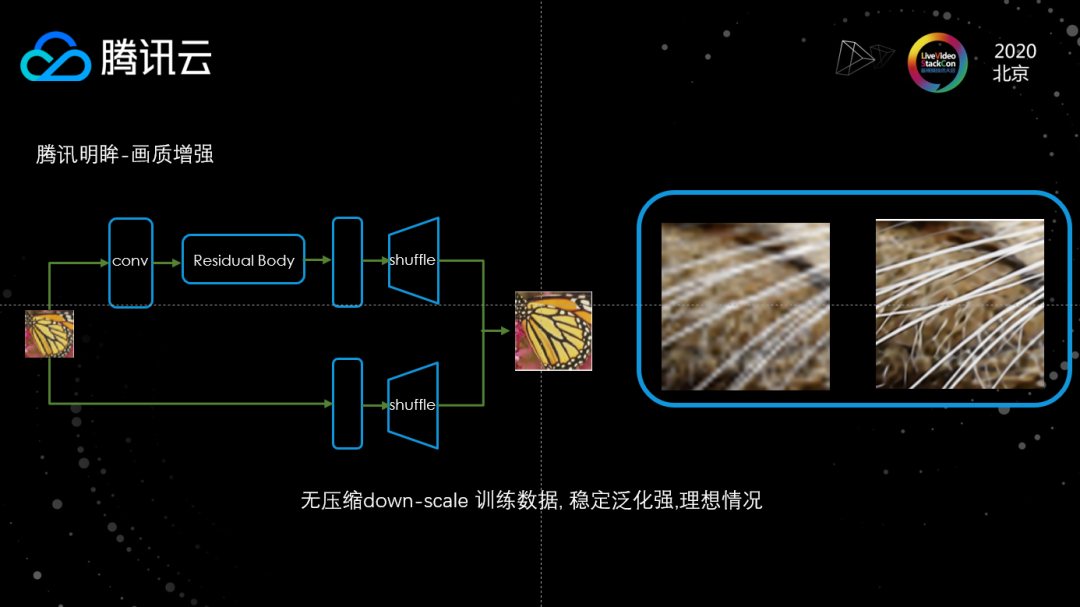
提到画质修复、画质增强,肯定离不开超分辨率。目前超分辨技术已经取得一定的突破,可以大规模的落地使用。其中,基于ResNet的WDSR模型目前有比较好的超分效果和稳定性。基于WDSR的视频超分有比较好的连贯性和稳定性,对每一个视频帧独立处理,连接成视频后不会有顿挫、抖动现象。
实际场景挑战 — 训练数据

在实际落地的过程中,还有很多新的问题需要关注和解决。首先训练数据非常重要,以上图为例,左边的视频已经有非常多噪点和模糊的情况,如果像实验环境下的视频一样使用无损的下采样数据进行训练,效果其实是微乎其微的。针对这样的情况,我们会把图像进行下采样,然后用比较高的CRF值(比较差的编码质量)对这个图像进行编码,这样训练数据中就有很多的噪点、伪影信息,训练出来的模型也会有比较好的去伪影能力。
海量视频的分类超分
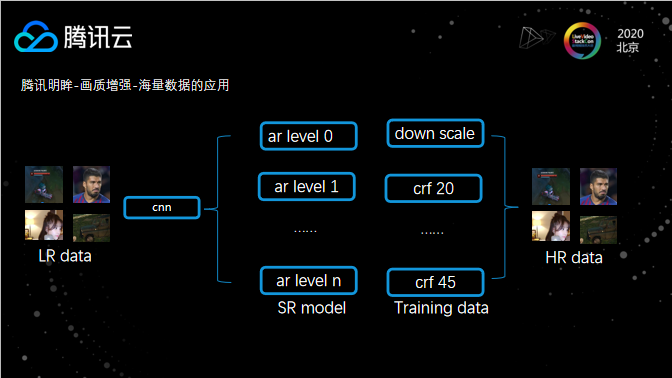
对于云上业务来说,每天需要处理海量的视频数据。如果对一个高清晰的视频进行超分,同时超分的模型是由一个高CRF数据集训练提供,会发现超分后视频的很多细节被磨平损失,反之亦然。所以不同训练数据构造的模型与视频源之间要有一定的匹配关系。针对这种场景,我们通过CRF值来构造多种压缩强度的数据源,进而用这些数据源训练出不同强度的超分模型。当需要进行超分处理时,先使用基于CNN清晰度分类模型,对视频源进行分类,判断视频源的清晰程度,然后使用跟清晰程度匹配的超分模型来进行处理。
Y or RGB?

接下来跟大家分享下落地过程中遇到的问题。团队最开始基于Y通道进行超分,但经过一段时间的运营,发现视频源是清晰的情况下,如果单独把Y通道单独提取出来会有很多奇怪的纹理和毛刺,超分后会放大这些异常。如果基于RGB超分则不会有这样的问题。虽然Y通道有自身的缺点,但在实际的落地过程中,很多场景还是离不开基于Y通道的超分。比如直播中的 4K超分,为了保证实时性,会对一路直播流进行分布式的拆分,路由到多台GPU节点进行处理,而在分布式超分的场景中,使用Y通道传输可以节省带宽的消耗。
老片场景超分辨率:细节补足与帧间稳定性
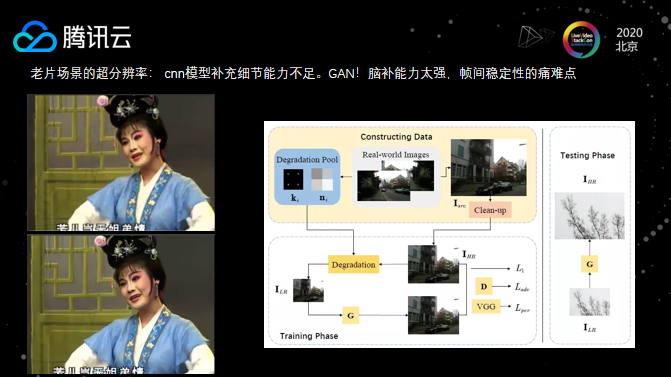
对于一些老片的场景,基于ResNet和CNN的超分模型,虽然可以提升视频质量,但是其对视频细节的捕捉能力还不够强,上述模型可以把一个非常差的视频提升到还不错的程度,但与目前所认可的高清还有一段差距。这种老片的视频场景,可以通过GAN网络来优化,GAN网络具有比较强的细节补充能力,这种补齐比较符合人眼感官,带来视觉效果的提升。当然,GAN网络在实际落地的过程中,还有很多需要解决的问题,首要问题就是GAN的不稳定性和帧间一致性的优化。
2.2 快速、可控的色彩增强
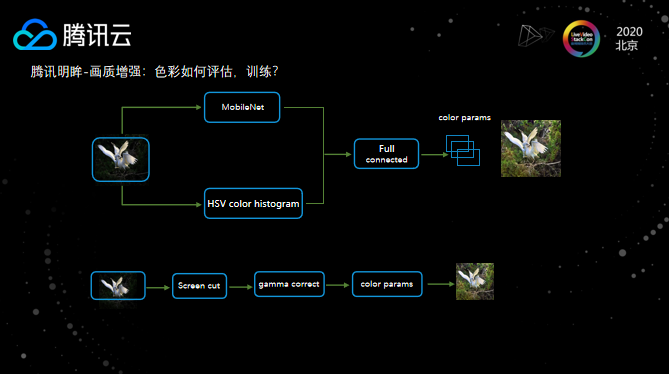
在色彩增强方面,这里将MobileNet的特征与HSV色彩直方图相结合,作为一个融合特征去分类训练,通过这个模型来获取调整对比度、亮度和色度的参数。这样处理后的模型比较小,速度也非常快,有利于大规模落地使用;其次,它不是端到端的处理,所以整个过程是可控的,由于颜色的变换对于人眼来说是非常敏感的,因此在落地的过程中,我们也更倾向于使用中间过程可控的方式。

从上面三张图片的对比来看,足球和暗场景都会使色彩变的更加鲜艳,同时对于游戏场景,也能比较好地保证原始视频颜色的本真。
2.3 视频流畅度提升,视频插帧
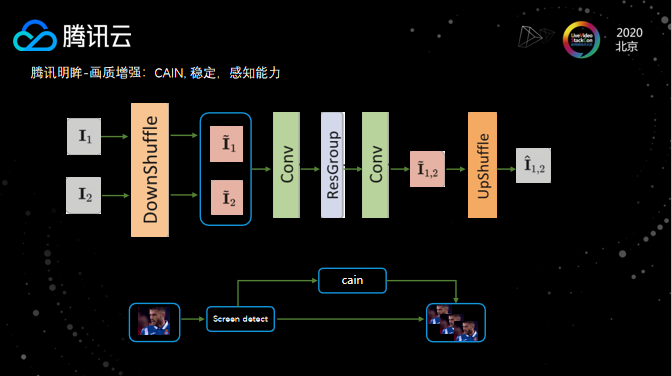
最后再介绍下我们在视频插帧所做的工作。相比于光流法,落地过程中更倾向于CAIN模型结构。CAIN网络的特性在于下限很高,稳定性比较强,很少有大面积的模糊错插。当然与光流法相比,CAIN插出来的清晰度较差。场景分割也是插帧中必不可少的一项操作,对于判断出的场景分割点,可以跳过不进行插帧,避免变化太大的问题。场景分割的实现方案可以考虑移植编码器的screencut算法,其在性能和稳定性上都经过了千锤百炼的优化,适用于大规模的落地使用。

上图是我们使用插帧效果的对比,虽然手部有一定程度的模糊,但在视频播放过程中,由于前后两帧都是清晰的,考虑到视觉残留效应,这种小的模糊是完全可以接受的。
0 3
云端全链路视频智能生产
最后再介绍下我们在视频编辑部分所支持的一些能力。
3.1 制作云 — 从生产、编辑到消费的全链路
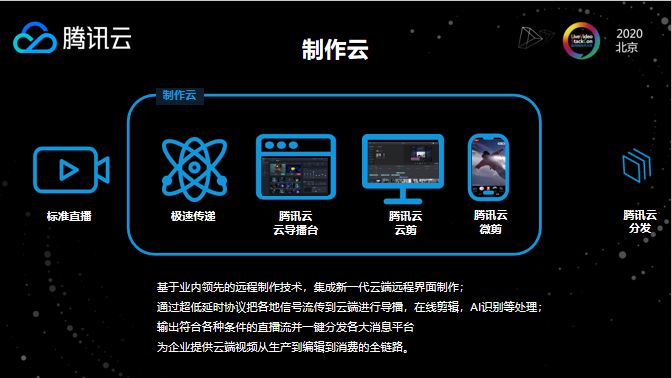
视频制作云,其集成了新一代的云端远程界面制作,通过超低延时协议把各地信号流传到云端进行导播,支持了在线剪辑和AI识别等处理,同时我们也为企业也提供了从生产到编辑到消费的全链路,支持一键分发到各大消息平台。

腾讯微剪,首发独创的小程序视频编辑工具,快速集成,支持音乐、滤镜等特效 。支持智能模板,根据输入素材自动视图拼接生成视频。

在直播制作方面,我们提供了云导播台。云导播台的优势就在于操作简单,功能上支持2s快速切换,直播内容无缝衔接。同时,云导播台是基于互联网的,所以非常容易支持一些互联网活动,比如支持直播过程中的实时发放红包和优惠券。
LiveVideoStackCon 2020 SFO(线上峰会)日程发布
无需漂洋过海,我们在线上等您!

LiveVideoStackCon 2020 美国旧金山站
北京时间:2020年12月11日-12月13日
点击 【阅读原文】了解更多日程信息
本文分享自微信公众号 - LiveVideoStack(livevideostack)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。











