
Hacker News是Y Combinator旗下的一个新闻频道,属于digg类产品,
SEOmoz曾经在2008年7月隆重推出Reddit、Stumbleupon、Del.icio.us和Hacker News算法全揭秘。由此,这些知名Web2.0网站的算法浮出水面。谷文栋曾在2009年时如下讲述了Hacker News的Ranking算法:
(p – 1) / (t + 2)^1.5
其中,
1)p 表示文章得到的投票数,之所以要使用 (p – 1),应该是想去掉文章提交者的那一票。
2)(t + 2)^1.5, 这个是时间因子。t 表示当前时间与文章提交时间间隔的小时数。但为什么要加 2 之后再取 1.5 的幂,似乎就没什么道理可言了,也许是个 trial-and-error 的结果吧。
他对“1.5”这个参数也没有做出解释。
Amir Salihefendic(他是Plurk、Todoist的Co-Founder)在今年10月份撰文《How Hacker News ranking algorithm works 》完整地解释了Hacker News的Ranking算法,从中我们才得以知道那个神秘的“1.5”是什么。稍后我们还会拿这个排序规则与Reddit的排序规则做对比。
一、Hacker News的ranking算法
Hacker News是用Arc编写的(Arc是Lisp的一个“方言”)开源项目,源代码可以从 http://ycombinator.com/arc/arc3.tar 获取。Ranking算法就写在这个包的news.arc文件里。鉴于这种语言是未来的语言,不容易看懂,所以代码就不贴了,光把注释贴出来:
; Ranking
; Votes divided by the age in hours to the gravityth power.
; Would be interesting to scale gravity in a slider.
努力领会这段神谕的同时,Amir说其实本质上执行的ranking规则是:
Score = (P-1) / (T+2)^G
where,
P = points of an item (and -1 is to negate submitters vote)
T = time since submission (in hours)
G = Gravity, defaults to 1.8 in news.arc
也就是说,前文所谓的莫名其妙的“1.5”,其实就是“Gravity(万有引力)”参数,默认是1.8。p之所以减去1,就是要去掉文章提交者的那一票。
1.1.Gravity(G)和Time(T)的作用
Gravity和time对于一篇文章(即一个item)的得分有着重要影响。一般来说:
- 随着T的增加(即时间的流逝),得分将下降,意味着更早被提交进来的文章将会得到越来越低的分数;
- 对于更早的文章,如果gravity增加,得分将会下降得更快。
(在这里要说明一下,著名的搜索引擎网站wolframalpha的plot语法能帮你根据公式(代入参数)画图,方便编纂文档随时举例或者调整算法,超赞。)
·得分是如何取决于time的
Amir利用wolframalpha绘制了公式代入参数后的趋势变化图,如下所示(下图访问链接http://goo.gl/ddYe):
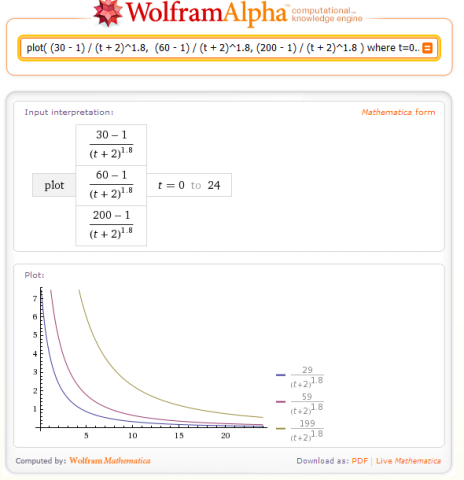
How score is behaving over time
上图中,定参Gravity为默认值1.8,随着时间的流逝,文章得分都会迅速下降。你还能看出来,24小时后(即t=24时)无论你的文章得到多少投票,它依然会得到一个非常低的得分。
·得分是如何取决于gravity的
当固定投票数,改变gravity又会如何呢?(下图访问链接http://is.gd/iJSbT):

How gravity parameter behaves
可以看到gravity越大,得分下降趋势就越快。
·Ranking规则的Python实现
这个得分函数就是这么简单:
def calculate_score(votes, item_hour_age, gravity=1.8):
return (votes - 1) / pow((item_hour_age+2), gravity)
Amir最后说道:“最关键的是你要理解这个算法如何起作用,以及你如何为自己的应用定制这个算法。”
相对于下面要讲述的Reddit排序算法,Hacker News的Ranking算法主要区别在于引入了time since submission这个参数,这个参数是不断变化的,从而导致一篇文章的得分不断变化。而Reddit下的一篇文章得分(Rank)是不变的,越新的文章得分越高,所以排序自然可能排在最前面。
二、Reddit的ranking算法
Reddit 是Digg类型网站,曾经在Digg 4改版引发用户众怒时被用户刻意追捧,独立访问数暴涨50%,并刻意将reddit链接分享至digg,使得digg主页充斥着对手reddit的链接。
谷文栋也曾于2008年12月发表过《Social Media Algorithm: Reddit》详细地解释了Reddit的公式及其参数构成。2010年11月,Amir也对此作了图文并茂的阐述:《How Reddit ranking algorithms work》。
它的公式如SEOmoz所描述的:
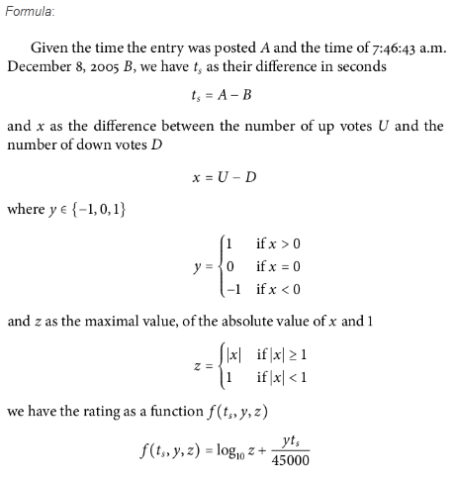
reddit formula
具体参数定义我就不再赘述了,可参考谷文栋或SEOmoz的文章。
Reddit也是开源的,其Python代码可从 http://code.reddit.com/ 寻到。他们的排序算法则因为性能问题改由Pyrex实现(Pyrex 是一种专门设计用来编写 Python 扩展模块的语言。根据 Pyrex Web 站点的介绍,“它被设计用来在友好易用的高级 Python 世界和凌乱的低级 C 世界之间搭建一个桥梁。”据说,“使用 Python like 的语法来编写 Python 的 C Module ,自动翻译成C语言代码,进而编译获取C代码的高效率。而且配合 Python 的 Distutils ,使得构建过程简单到了只需要 setup.py 的程度”)。
你可以点击链接 http://code.reddit.com/browser/r2/r2/lib/db/sorts.py?rev=4778b17e939e119417cc5ec25b82c4e9a65621b2 查看这个“hot ranking”算法被翻译为Python后的代码。
reddit很强调submission time(文章提交时间)。
2.1.提交时间的作用
提交时间对于文章评级有如下作用:
- 提交时间对ranking有很大影响,新文章肯定比老文章rank值高;
- 这个得分将不会随着时间流逝而递减,但新文章会得到更高的得分。这与Hacker News的算法有着显著区别。
下图显示了,固定Up和Down投票数的情况下,不同的提交时间,rank分值的变化:

从上图可以看出,同样的,随着时间的推移,新文章的得分会逐渐超越高同样投票数的老文章。
2.2.log函数的作用
这个“hot ranking”算法用了logarithm函数来确保最前面的投票权重大于接下来的投票。它的弯弯绕说法是这样的:
The first 10 upvotes have the same weight as the next 100 upvotes which have the same weight as the next 1000 etc...
谷文栋是这么解释的:
前 10 票获得的权重,与 11 到 101 票所获得的权重是一样的。
图形化的阐释是:

如果不用logarithm函数,那么情况就会是这样:

还是图解看上去直观吧?
2.3.反对票的作用
Reddit是少数几个允许有反对票的Digg类型新闻聚合网站,Hacker News就没有投反对票一说。
它的公式中有这么一个因子:
up_votes - down_votes
它的作用可以图形化为:

也就是说,那些有争议性话题的文章,得分将会比只得到赞同票的文章更低。
2.4.总结
Amir总结了一下Reddit的算法:
- Submission time(提交时间)是一个非常重要的参数,玩聚SR和RT就都是参照Reddit重视文章或热门消息的发布时间的。
- 前10票的得分,和接下来的100票,是一样的。这样,得了10票的文章,就可能和得了50票的文章得分相似。
- 争议性话题(得了很多反对票的)得分会很低。
(Amir还讲了Reddit的comment ranking,有兴趣可以自己去看看)
三、小结
就我在玩聚SR上使用Reddit排序算法的经验:
Hacker News的算法能够让老文章消失得更快,比如24小时之前的文章,基本就不会在榜单上存留。
Reddit的算法则能够让众望所归的那些优秀文章能够停留相当长时间,然后随着时间流逝,一点一点地被新的、好的文章挤下去。
Reddit的算法还有一个好处就是,当投票数变化了,才需要去重新计算一次文章的Rank,不用管时间的流逝。
参考资源:
1、Amir 2010年 《How Hacker News ranking algorithm works》;
2、谷文栋 2009年 《Social Media Algorithm: Hacker News》;
3、谷文栋 2008年 《Social Media Algorithm: Reddit》;
4、SEOmoz 2008年 《Reddit, Stumbleupon, Del.icio.us and Hacker News Algorithms Exposed!》。











