API 调用次数限制实现
1 年前
在开发接口服务器的过程中,为了防止客户端对于接口的滥用,保护服务器的资源, 通常来说我们会对于服务器上的各种接口进行调用次数的限制。比如对于某个 用户,他在一个时间段(interval)内,比如 1 分钟,调用服务器接口的次数不能够 大于一个上限(limit),比如说 100 次。如果用户调用接口的次数超过上限的话,就 直接拒绝用户的请求,返回错误信息。
最开始的想法
对于实现方法的第一印象,大概是,给每个用户一个配额,次数为 Q, 这个配额在用户第一次调用接口的时候分配给用户。然后在接下去的 P 时间段 内,如果用户访问 API 的次数大于 Q,就开始拒绝用户的调用请求。然后,这个 配额,在 P 时间之后,配额会被重置回 Q。
大概的伪代码如下:
can_access(identity): limit_counter = get(identity) if limiter_counter exists and limiter_counter.timestamp - CURRENT_TIME < LIMIT_INTERVAL and limit_counter >= limit: return false else if limiter_counter is nil or (limit_counter exists and limiter_counter.timestamp - CURRENT_TIME > LIMT_INTERVAL): put(identity, new LimiterCounter(1, CURRENT_TIME)) else put(identity, limiter_counter.increment()) end return true endredis 的 INCR 命令可以比较简单地实现这种方法,在 INCR 的文档页下面介绍了如何使用 INCR 命令实现 Rate Limtier。
这种实现方法,仔细想来,存在一个缺陷,就是,用户可以在一个时间段的末尾发起 Q 次请求,然后在下一个时间段的开始又 发起 Q 次请求,这样,一个用户可以在很短的时间之内发起 2Q 次请求。
可能普通用户不会刻意这么去做,但如果真的出现这种情况的时候,服务器会承受正常情况下两倍的负载, 这并不是我们所希望看见的。而且如果服务器被攻击的话,这种的缺陷,还是很可能会被利用的。
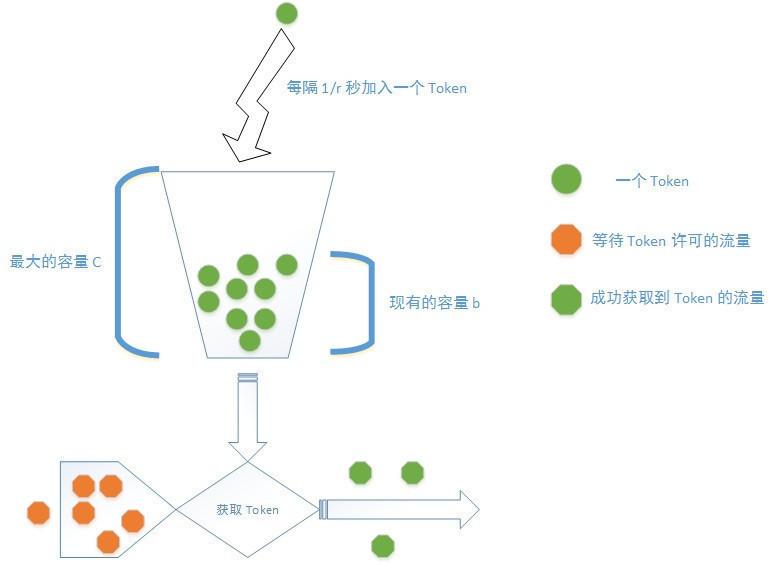
Token Bucket 算法
作为一个程序员,当我对于一个问题没有头绪时,可以
或者可以
简单的 Google 之后,在 StackOverflow 上面了解到 Token Bucket 算法, 这个算法通常用在计算机的网络设备上面,一般用于限制流量,很符合我所需要解决的问题。
在这个算法当中:
- 所有的流量在放行之前需要获取一定量的 token;
- 所有的 token 存放在一个 bucket(桶)当中,每 1/r 秒,都会往这个 bucket 当中加入一个 token;
- bucket 有最大容量(capacity or limit),在 bucket 中的 token 数量等于最大容量,而且没有 token 消耗时,新的额外的 token 会被抛弃。
简单地来看,可以将这个算法类比成有个水龙头在往水桶中放水,然后不断地有水瓢到这个水桶中打水去浇花,如果水桶的水满了,那么 水就从水桶中溢出了。
在我们的问题领域,要将流量换成一个请求。当一个请求到达服务器的时候,首先需要根据请求的各种信息,确定其需要获取哪个 bucket 的 Token,因为服务器一般会有多种限制流量的策略进行组合。
举一些例子:
对于每个登录过的用户,服务器规定 10 秒内,用户的请求次数不能超过 200 次;而且,1 小时内,用户的请求次数不能超过 5000 次;并且,1 天内, 用户的请求次数不能超过 20000 次。这样,对于每个用户都需要设置三个 bucket。
另外服务器还规定服务器所有的接口在 10 秒内,请求次数不能超过 100000 次,这种情况下,所有用户会共享一个全服务器的 token bucket。
还有可能根据 IP 进行限制,这样 bucket 就需要根据 IP 地址进行创建。
接着,这个请求去对应的 token bucket 获取允许通行的 token,如果没有获取到 token,服务器最好的做法是直接返回流量超过限制的响应(429)。 如果获取到相应的 token,那么就对于请求给予放行。
初步的实现的想法
初步实现的想法很简单,首先,对于每个 Bucket 设置一个定时器,每过一个间隔,就往这个 Bucket 当中加入一些 Token,然后用户 获取一个 Token 之后,就将 Bucket 中的 Token 数量减一。这个实现,是在看到这个算法的时候,比较容易想到的一个方法。然而, 稍微仔细地考虑一下,就知道这个实现手段在现实当中基本上是属于没法用的实现。原因在于,这种实现算法需要给每个 Bucket 添加 一个定时器,而一个定时器就是一条线程。那么在你的服务器上,光是分配给定时器的线程就需要和你的用户数量是一个量级的, 几万几十万条线程在服务器上运行,是完全是脱离了实际情况的。
所以这个简单的实现方法,在稍微考虑之后,就可以排除了。
另一种的实现的办法
于是又开始寻找另外的实现方法,搜索资料的时候,发现 Guava 库当中也有一个 RateLimiter,其作用也是 用来进行限流,于是阅读了 RateLimiter 的源代码,查看一些 Google 的人是如何实现 Token Bucket 算法的。
RateLimiter 和 SmoothRateLimiter
// com.google.common.util.concurrent.SmoothRateLimiter private void resync(long nowMicros) { // if nextFreeTicket is in the past, resync to now if (nowMicros > nextFreeTicketMicros) { storedPermits = min(maxPermits, storedPermits + (nowMicros - nextFreeTicketMicros) / stableIntervalMicros); nextFreeTicketMicros = nowMicros; } }在 resync 方法中的这句代码 storedPermits = min(maxPermits, storedPermits+ (nowMicros - nextFreeTicketMicros)/stableIntervalMicros); 就是 RateLimiter 中计算 Token 数量的方法。没有使用计时器,而是使用时间戳的方式计算。这个做法给足了 信息。我们可以在 Bucket 中存放现在的 Token 数量,然后存储上一次补充 Token 的时间戳,当用户下一次请求获取一个 Token 的时候, 根据此时的时间戳,计算从上一个时间戳开始,到现在的这个时间点所补充的所有 Token 数量,加入到 Bucket 当中。
这种实现方法有几个优势:
- 首先, 避免了给每一个 Bucket 设置一个定时器这种笨办法,
- 第二,数据结构需要的内存量很小,只需要储存 Bucket 中剩余的 Token 量以及上次补充 Token 的时间戳就可以了;
- 第三,只有在用户访问的时候,才会计算 Token 补充量,对于系统的计算资源占用量也较小。
确定和实现方法之后,就可以开始实现这个算法了。首先要考虑的是 Bucket 存放在哪里?虽然 Bucket 占用内存的数量 很小,假设一个 Bucket 的大小为 20 个字节,如果需要储存一百万个 Bucket 就需要使用 20M 的内存。而且,Bucket 从 一定意义上属于缓存数据,因为如果用户长期不使用这个 Bucket 的话,应该能够自动失效。从上面的分析,自然地,我想到 将 Bucket 放在 Redis 当中,每个 Bucket 使用一个 Hash 存放(HSET), 并且支持在一段时间之后,使 Bucket 失效(TTL)。
于是有了第一版的代码, RateLimiter
public boolean access(String userId) { String key = genKey(userId); try (Jedis jedis = jedisPool.getResource()) { Map<String, String> counter = jedis.hgetAll(key); if (counter.size() == 0) { TokenBucket tokenBucket = new TokenBucket(System.currentTimeMillis(), limit - 1); jedis.hmset(key, tokenBucket.toHash()); return true; } else { TokenBucket tokenBucket = TokenBucket.fromHash(counter); long lastRefillTime = tokenBucket.getLastRefillTime(); long refillTime = System.currentTimeMillis(); long intervalSinceLast = refillTime - lastRefillTime; long currentTokensRemaining; if (intervalSinceLast > intervalInMills) { currentTokensRemaining = limit; } else { long grantedTokens = (long) (intervalSinceLast / intervalPerPermit); System.out.println(grantedTokens); currentTokensRemaining = Math.min(grantedTokens + tokenBucket.getTokensRemaining(), limit); } tokenBucket.setLastRefillTime(refillTime); assert currentTokensRemaining >= 0; if (currentTokensRemaining == 0) { tokenBucket.setTokensRemaining(currentTokensRemaining); jedis.hmset(key, tokenBucket.toHash()); return false; } else { tokenBucket.setTokensRemaining(currentTokensRemaining - 1); jedis.hmset(key, tokenBucket.toHash()); return true; } } } }上面的方法是最初的实现方法,对于每一个 Token Bucket,在 Redis 上面,使用一个 Hash 进行表示,一个 Token Bucket 有 lastRefillTime 表示最后一次补充 Token 的时间,tokensRemaining 则表示 Bucket 中的剩余 Token 数量,access() 方法大致的步骤为:
- 当一个请求 Token进入 access() 方法后,先计算计算该请求的 Token Bucket 的 key;
- 如果这个 Token Bucket 在 Redis 中不存在,那么就新建一个 Token Bucket,然后设置该 Bucket 的 Token 数量为最大值减一(去掉了这次请求获取的 Token)。 在初始化 Token Bucket 的时候将 Token 数量设置为最大值这一点在后面还有讨论;
- 如果这个 Token Bucket 在 Redis 中存在,而且其上一次加入 Token 的时间到现在时间的时间间隔大于 Token Bucket 的 interval,那么也将 Bucket 的 Token 值重置为最大值减一;
- 如果 Token Bucket 上次加入 Token 的时间到现在时间的时间间隔没有大于 interval,那么就计算这次需要补充的 Token 数量,将补充过后的 Token 数量更新到 Token Bucket 中。
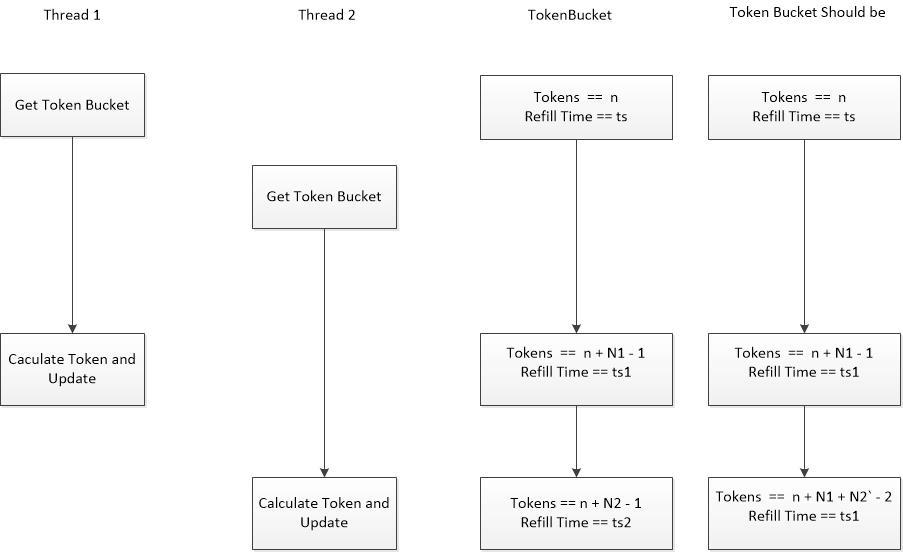
这个方法在单线程的条件下面,可以比较好地满足需求,但是在多线程的条件下面,是会出现 race condition,如下面的图所示。
更好一点的实现方法
上面的 race condition 出现的原因是多个线程对于 Token Bucket 进行写操作,当遇到 race condition 的时候, 我们通常使用锁的方式解决这个冲突。
对于上面这个情况,我们需要使用锁保护的资源就是相应的 Token Bucket。如果使用锁的方式实现,需要对每一个 Token Bucket 附加一个锁,当多个线程并发地读写 Token Bucket 的时候,需要先获取这个锁的控制权,然后 对于 Token Bucket 进行修改,然后更新到 Redis 中。
虽然使用在业务代码当中可以实现这个逻辑,但 Redis 提供了一种我个人感觉更好的方法来实现同样的上锁机制。 EVAL 和 EVALSHA, 使用 lua 脚本的方式执行命令,这个脚本整个的操作会被当成一个原子操作在 Redis 上面执行
我们可以将原本的 Java 实现转写成 lua 脚本,将要本要做的 Token Bucket 的读写操作放在这个脚本当中, 让 Redis 去保证这个操作的原子性。 大致的实现放在这里rate_limiter.lua 和LuaRateLimiter.java。
查漏补缺
在上面一个版本的 LuaRateLimiter 当中,我自己发现的问题有两个:
当用户首次请求 Token 或者长时间没有请求 Token 的情况下,首次进行 Token 请求,Bucket 此时所持有的 Token 数量应该是可以设置的,而不是一个简单的 Token Bucket 的容量最大值。因为我们的算法在 Token Bucket 被激活(第一次使用,或者间隔时间很长后使用)之后,会不断地往里面继续添加 Token(在用户请求的时候), 这样在一个 interval 之内,用户所能够使用最大 Token 数量 M 等于初始的 Token 数量 I 加上 Bucket 的 Token 容量最大值 C。
LuaRateLimiter 承担了两个任务,第一,控制请求从 Token Bucket 中获取 Token;第二,指定 Token Bucket 的 限制规则。在 OOP 编程中,我们一般遵循 Single Responsibility Principle, 而且希望对于一个类来说是高内聚,低耦合的。 在这里,LuaRateLimiter 的两个责任,没有很明显的相互依赖关系,Token Bucket 的限制规则可以独立于控制请求的过程而存在, 而请求控制过程依赖到的是使用 Token Bucket 的限制规则和请求的身份生成 Token Bucket 的 key。在我看来,这构成了很好的理由 将 LuaRateLimiter 拆分成两个类 RateLimitPolicy 和 LuaRateLimiter,来分别承担这两个任务。
经过改版之后的代码在这里
对于第一个问题,我现在做的改动比较有限,在 RateLimitPolicy 当中添加一个 maxBurstTime,然后计算 Bucket 激活的时候 初始的 Token 容量。程序创建一个 RateLimitPolicy 的时候,需要指定这个 maxBurstTime。关于这个初始容量的设置与计算 可以进一步参考 Guava 的 SmoothRateLimiter 中的文档和代码。
第二问题就是比较简单的重构,在实现当中,RateLimitPolicy 是一个抽象类,有一个 PerUserRateLimitPolicy,这个 规则通过 genBucketKey() 方法,对于每个用户都返回一个不同的 bucket key,从而使不同的用户使用不同的 Token Bucket。 另外,如果有别的限制策略,可以通过实现不同的 RateLimitPolicy 来完成(genBucketKey() 方法的定义还可以进一步地优化)。
现在这个版本的实现,不算特别成熟,但如果要求不是特别高的话,也是一个可用的实现方案,所以暂时就先写成这样, 如果实际应用中发现问题,可以进一步地优化。
测试
测试的代码放在LuaRateLimiterTest 中,暂时只是简单地进行了功能上面的测试。
另外可选的实现
除了文章介绍的方法,还有另外一些其他的方法可以实现,阅读参考资料中的 第 2,4,5 篇的文章中介绍的实现方法来完成。
参考资料
- Token Bucket
- Redis Incr
- Redis Eval
- Better Rate Limiting With Redis Sorted Sets
- Intro to rate limiting with Redis part1 and part2
- Guava RateLimiter and Guava SmoothRateLimiter, 特别推荐 SmoothRateLimiter 中的文档部分
- Lua Reference,redis 中使用 lua 5.1
- Single Responsibility Principle
- High Cohesion, Loose Coupling
关于我
API 调用次数限制实现

Wesley13
• 阅读
1276



点赞
收藏











