
一、Spark Streaming连Kafka(重点)
方式一:Receiver方式连:走磁盘
使用High Level API(高阶API)实现Offset自动管理,灵活性差,处理数据时,如果某一时刻数据量过大就会磁盘溢写,通过WALS(Write Ahead Logs)进行磁盘写入,0.10版本之后被舍弃,
相当于一个人拿着一个水杯去接水,水龙头的速度不定,水杯撑不下就会往盆(磁盘)中接。
zookeeper自动管理偏移量
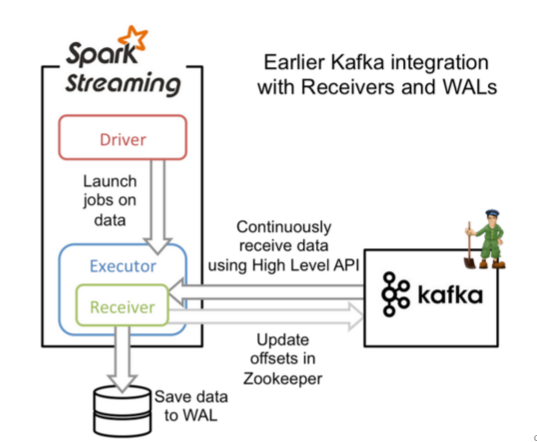
Receiver方式说明:Receiver会以固定的时间向kafka中通过zookeeper自动管理偏移量拉取数据,当拉取的数据过多Executor处理不完就会落入磁盘中,
方式二:Direct方式直连:不走磁盘
使用Direct API(底层API)实现Offset偏移量自定义管理,灵活性极高,保证了数据的安全性,不用担心数据量过大,因为它有预处理机制,进行提前处理,之后批次提交任务。
相当于将水管直接拉到了需要用的地方,中间有预处理机制。不经过磁盘
实现自己维护偏移量(偏移量可以保存到MySQL,Redis,zookeeper)中
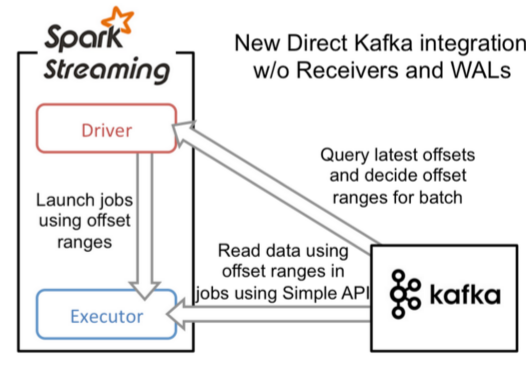
SparkStreaming的Receiver方式和Direct直连方式有什么区别?
Receiver接收固定时间间隔的数据(放在内存中的),使用Kafka高级到API,自动维护偏移量,达到固定的时间才进行处理,效率低并且容易丢失数据
Direct直连方式,相当于连接到Kafka的分区上,使用Kafka底层的API,效率高,需要自己维护偏移量。











