
More Effective C++
35个改善编程与设计的有效方法
- 只有深入了解C++编译器如何解释代码, 才有可能用C++语言写出健壮的软件.
- C++的难学, 不仅在其广博的语法, 语法背后的语义, 语义背后的深层思维, 深层思维背后的对象模型;
- C++4种不同的编程思维模型:
- 基于过程的程序设计(procedural-based);
- 基于对象的编程思想(object-based);
- 面向对象的编程思想(object-based);
- 范式模板的编程思想(generic paradigm).
- 要有效率, 又要有弹性, 又要有前瞻望远, 又要回溯相容, 又要能治大国, 又要能烹小鲜, 学习起来不可能太简单.
- C++4种不同的编程思维模型:
- 继承(Inheritance)机制会引发指针或引用拥有两个不同的类型: 静态类型和动态类型.
- 指针或引用的静态类型是指其声明时的类型;
- 动态类型则由他们实际所指的对象来决定.
- 当分配了内存而没有释放它, 就存在内存泄漏问题(memory leak).
- 如果构造函数还申请了其他资源(文件描述符, 互斥量, 句柄, 数据锁), 析构函数没有释放的话, 这些资源也会被泄漏掉(resource leaks).
基础议题
- 指针(pointers), 引用(references), 类型转换(casts), 数组(arrays), 构造函数(constructors).
仔细区别pointers和references
- 指针使用'*'和'->'操作符, 引用使用'.'操作符.
- 没有所谓的空引用(null reference).
- 一个引用必须总代表某个对象.
- 未初始化的指针, 虽然有效, 但风险很高.
- 引用可能回避使用指针更具有效率.
- 指针可以被重新赋值, 指向另一个对象, 但引用却总是指向它最初获得的那个对象.
- 在不同时间指向不同对象的时候, 应该使用指针.
- operator[]一般需要使用引用.
最好使用C++转型操作符
- 改变对象的常量性;
- 改变对象的类型;
- C++具有4个新的转型操作符(cast operators):
- static_cast; --- 拥有与C旧式转型相同的威力与意义.
- const_cast; --- 用来改变表达式中的常量性或变异性(volatileness).
- dynamic_cast; --- 用于继承体系中, 将基类的引用或指针转换为派生类的引用或指针.
- reinterpret_cast; --- 与编译平台相关, 不具有移植性, 用于转换函数指针类型. --- 函数指针转换.
绝对不要以多态(polymorphically)方式处理数组
- 继承的重要性质之一是: 用指向基类的指针或引用操作派生类对象.
- 多态是多重类型的意思.
- 通过基类指针删除一个由派生类对象构成的数组, 其结构是未定义的.
- 多态和指针算术不能混用.
- 一个具体类最好不要继承另一个具体类.
非必要不提供默认构造函数(default constructor)
- 默认构造函数的意义是在没有任何外来信息的情况下将对象初始化.
- 一个类缺乏一个默认的构造函数, 当使用这个class时便会有些限制.
- 数组对象应该以相反顺序析构掉.
- 对模板(template)而言, 被实例化的目标类型(instantiated)的目标类型必须得有一个默认构造函数.
- 添加无意义的默认构造函数(default constructors)会影响class的效率.
操作符
- 操作符(overloadable operators) 是可以被重载的.
对定制的"类型转换函数"保持警觉
- C++允许编译器在不同类型之间执行隐式转换(implicit conversions).
- 默认把char 转换为 int, 将short 转换为 double.
- 单自变量构造函数和隐式类型转换操作符.
- 隐式类型转换是一个拥有奇怪名称的成员函数, 关键词operator之后加上一个类型名称.
- 隐式类型转换操作符的缺点: 它们的出现可能导致非预期的错误, 或非预期的函数调用, 却很难发现.
- 以一个功能对等的另一个函数取代类型转换操作符.
- string对象没有到char* 隐式转换的函数. 但提供一个c_str()显示转换函数.
- 单变量的构造函数很可能发生不容易发觉的隐式转换.
- 使用关键字explicit, 编译器就不能因隐式类型转换的需要而调用它们.
- 编译器不能转换一个以上的用户自定义类型隐式转换行为.
- 代理类技术(proxy classes) --- 将基本类型重新简单封装为一个类.
- 允许编译器执行隐式转换, 害处多过好处.
区别自加(increment)/自减(decrement)操作符的前置和后置形式
后置有一个int的自变量, 默认为0.
后置函数一般都会产生一个临时对象, 效率可能没有前置函数效率高.
// 前置 UPint& UPint::operator++() { *this += 1; return *this; } // 后置 const UPint UPint::operator++(int) { UPint oldValue = *this; // 临时变量 ++(*this); return oldValue; // 先取出在加. }
千万不要重载&&, ||和逗号,操作符
一般表达式真假的确定以"骤死式"进行, 如果一旦该表达式的真假值确定, 即使表达式中还有部分尚未校验, 整个评估工作仍然结束.
可以在全局或是每个类中重载&&和||操作符; 但函数调用语义将取代骤死式语义.
C++语言规范并没有明确定义函数调用动作中各参数的评估顺序.
表达式如果含有逗号, 那么逗号左侧先被评估, 逗号右侧后背评估.
. .* :: ?: new delete sizeof typeid static_cast dynamic_cast const_cast reinterpret_cast // 以上操作符不能被重载
操作符重载的目的是要让程序更容易被阅读, 被撰写和被理解.
了解各种不同意义的new和delete
new操作符:
- 分配足够的内存, 用来放置某类型的对象;
- 调用一个构造函数(constructor), 为分配的内存中的那个对象设定初值.
placement new(放置new操作符):
针对一个已存在的对象调用其构造函数并无意义.
placement new 允许在已经分配好的内存上进行对象的构造.
当程序运行在共享内存或(memory-mapped I/O), placement new函数将很有用.
new (buffer) Widget(widgetSize).void * operator new(size_t, void *location) { return location; }
placement new是C++标准程序库的一部分, 如果使用placement new, 就必须用
#include <new>头文件.如果将对象产生于堆上(heap), 应使用new operator.
如果只分配内存就使用operator new.
如果在已分配(并拥有指针)的内存中构造对象, 应该使用placement new.
为了避免资源泄漏(resource leaks), 每个动态分配行为都必须匹配一个相应的释放动作.
operator new[]负责分配一个数组对象的空间, 通常称为array new, 进行动态分配内存.
- 数组版的new operator必须为数组中的每个对象调用一个构造函数.
- new operator和delete operator都是内建操作符.
异常
- C语言中的setjmp和longjmp可能有异常捕获的功能, 异常安全程序比较重要(exceptions-safe).
利用destructor(析构函数)避免资源泄漏
- 局部对象总是会在函数结束时被正确地析构. --- 在这种类的析构函数中调用delete操作符.
- 行为类似指针的对象被称为智能指针(smart pointers).
- auto_ptr; --- 基本被弃用.
- shared_ptr; --- 共享指针, 引用计数为零就销毁对象空间.
- weak_ptr; --- weak_ptr是用来解决shared_ptr相互引用时的死锁问题. 弱引用不会增加引用计数.
- unique_ptr; --- unique_ptr 是一个独享所有权的智能指针,它提供了严格意义上的所有权.
在构造函数(constructors)内阻止资源泄漏
- C++保证删除null指针是安全的.
- 面对尚未完全构造好的对象, C++拒绝调用其对应的析构函数.
- C++不自动清理那些构造期间抛出异常(exceptions)的对象, 需要在构造函数中捕获可能存在的异常.
- 最好把共享代码抽出放进一个private的辅助函数内, 然后让析构或构造函数都调用它.
- 智能指针shared_ptr可以帮助构造函数处理构造过程中出现的异常.
禁止异常(exceptions)流出destructors(析构)之外
- 两种情况下析构函数会被调用:
- 对象正常状态下被销毁, 离开了其生存空间(scope)或是被明确删除.
- 当对象被异常处理机制销毁.
- 异常传播过程中的栈展开机制(stack-unwinding).
- C++可能调用terminate函数, 结束掉程序.
- 全力阻止exceptions传出析构函数之外:
- 它可以避免terminate函数在异常传播过程的栈展开机制中被调用;
- 确保析构函数完成其应该完成的每一件事情.
了解抛出一个异常与传递一个参数或调用一个虚函数之间的差异
- 函数和异常的传递方式有三种:
- 值传递(by value);
- 引用传递(by conference);
- 指针传递(by pointers).
- 函数调用, 控制权最终会回到调用端, 当抛出一个异常, 控制权不会再回到抛出端.
- 捕获异常不论其是以值或引用传递异常, 都会把异常进行一次拷贝, 交给catch子句手上的是一个异常副本.
- 一个对象被抛出作为异常, 总是会发生复制(copy). 即使是一个static对象, 也会发生拷贝.
- 所以异常传递是比较慢的.
- 复制行为由对象的赋值构造(copy constructor)函数完成, 而且赋值构造函数只针对静态类型进行copy.
- 复制动作永远是以对象的静态类型为本.
- 函数调用将一个临时对象传递给一个非const引用参数是不允许的, 但对异常却是合法的.
- 不要抛出一个指向局部对象的指针.
- 隐式转换一般不会发生在exceptions与catch子句中.
- 继承体系中的类转换
- 有型指针转换为无型指针.
- 当调用一个虚函数, 虚函数采用best fit(最佳吻合)策略, 而异常处理机制采用first fit(最先吻合)策略.
- 绝不要将针对基类而设计的catch子句放在针对派生类设计的catch子句之前.
以by reference方式捕捉异常(exceptions)
- 如果异常对象被分配于heap(堆), 他们必须删除, 否则便会泄漏资源.
- 4个标准的异常:
- bad_alloc --- 当无法满足内存需求时会发出.
- bad_cast --- 当对一个引用施行dynamic_cast失败时发出.
- bad_typeid --- 当dynamic_cast被实施于一个null指针时发出.
- bad_excepttion --- 适用于未预期的异常情况.
- 如果catch by reference(引用)可以避开对象删除问题.
明智运用exception specifications(异常具现化)
- 编译器只会对exception specifications(异常具现化)做局部性检验.
- 避免将exception specifications(异常具现化)放在需要类型自变量的template身上.
- 不应该将template和exception specifications(异常具现化)混合使用.
- 在函数传递之际检验exception specifications(异常具现化).
- 处理系统可能抛出的异常.
了解异常处理的成本
- 针对每个try语句块, 都必须记录对应的catch子句及能够处理的异常类型.
- 异常使程序速度要慢3个数量级.
- 效率分析工具(profiler)可以分析程序效率.
效率
- 高性能算法和数据结构, 语言本身的效率.
谨记 80-20法则
- 一个程序80%的资源用在20%的代码身上.
- 软件中整体性能几乎总是由其构成要素(代码)的一小部分决定的.
- 遇到瓶颈, 用经验, 用直觉猜往往是错误的做法. 程序的性能特质倾向高度的非直觉.
- 需要根据观察或实验识别造成痛心的那20%的代码.
- 尽可能地以最多的数据来分析软件.
考虑使用lazy evaluation(缓式评估)
- 拖延战术的思想.
- 引用计数(reference count):
- 数据共享引起的唯一危机仅在某个字符串被修改时才发生.
- 在真正需要数据之前, 不必着急为某物拷贝一个副本, 在对某物进行写操作时才进行拷贝副本.
- 区分读和写.
- lazy fetching(缓式取出):
- 只产生对象的一个外壳, 当对象内的某个字段被需要了, 程序才从数据库中取回对应的数据.
- mutable关键字, 允许对const对象进行修改, 由编译器支持.
- lazy expression evalution(表达式缓评估)
- 数值应用.
分期摊还预期的计算成本
- over-eager evaluation, 如果程序常常用到某个计算, 设计一份数据结构以便能够及有效率地处理需求.(caching).
- 利用告诉缓存暂存使用频率高的内容.
- caching是分期摊还预期计算成本的一种做法. 预先取出是另一种做法.
- 系统调用往往比进程内的函数调用慢.
- 较快的速度往往导致较大的内存, 空间交换时间.
- 较大对象比较不容易塞入虚内存分页(virtual memory page)或缓存分页(cache page).
- 对象变大可能会降低性能, 因为换页活动会增加, 缓存命中率(cache hit rate)会降低.
了解临时对象的来源
- C++中真正的所谓的临时对象是不可见的, 并不会在源码中出现.
- 当隐式类型转换(implicit type conversions);
- 函数返回对象的时候.
- 如果对象传递给非const的引用参数, 隐式转换是不会发生的.
- 因为临时对象被修改不是程序所想看到的.
- 临时对象可能很耗成本, 应尽可能地消除它们.
协助完成"返回值优化(RVO)"
- 以传值(by value)方式返回对象, 背后隐藏的构造和析构将无法消除.
- C++允许编译器将临时对象优化, 使它们不存在.
- return value optimization, 返回值优化(返回的临时对象将不会被马上析构掉).
利用重载技术(overload)避免隐式类型转换(implicit type conversions)
- 每个重载操作符必须获得至少一个用户定制类型的自变量.
- 重载int和自定义类型的函数, 避免int隐式转换为自定义的类型.
考虑以操作符复合形式(op=)取代其独身形式(op)
- 已复合形式实现单独形式的操作符.
- 当面临命名对象或临时对象的抉择时, 最好选择临时对象.
考虑使用其他程序库
- 理想的程序库应该小, 快速, 威力强大, 富有弹性, 有扩展性, 直观, 可广泛运用, 有良好支持, 使用时没有束缚, 而且没有bug.
- iostream程序库比stdio程序库具有类型安全特性(type-safe), 并且可扩充, 但效率没有后者高.
了解虚函数, 多继承, 虚基类, 运行时类型识别的成本
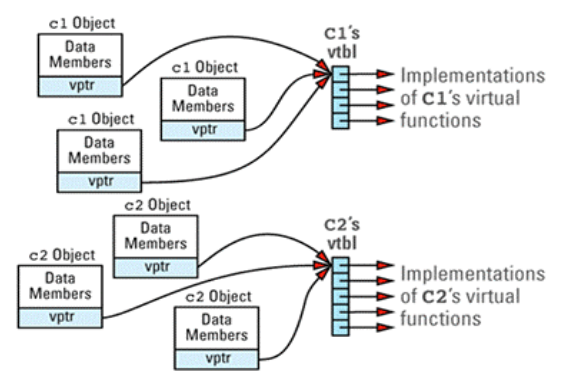
- 大部分编译器使用虚表(virtual tables, vtbls)和虚表指针(virtual table pointers, vptrs)来处理对象动态类型的指针或引用.
- 虚表(vptl)通常是一个由函数指针构成的数组, 某些编译器会以链表取代数组.
- 程序中的每个类声明或继承了虚函数, 都会存在一个虚表, 表中的每一项(条目)就是该类的各个虚函数实现的函数指针.
- 必须为每个拥有虚函数的类消耗一个虚表(vtbl)空间, 其大小视函数的个数而定, 每个类应该最多只有一个vbtl.
- 在每个需要vbtl的目标文件中产生䘝vbtl副本. --- 链接器剔除重复副本, 只留每个vbtl的单一实体.
- 更常见的做法是探勘式做法, vtbl被产于第一个非内联, 非纯虚函数定义式的目标文件中. 如果虚函数被声明为inline, 这种方法行不通.
- 避免将虚函数声明为inline.
- 虚表指针(vptr)指示每个对象相对于哪一个虚表(vtbl).
- 每个声明有虚函数的对象内都隐藏着一个虚表指针, 被编译器加入到编译器才知道的位置.
- 每个拥有虚表指针的对象都会将付出一个额外的指针代价.
- 较大的对象意味着难以放入缓存分页或虚内存分页中, 可能会增加换页活动.
- 较大的对象意味着难以放入缓存分页或虚内存分页中, 可能会增加换页活动.
- 虚函数真正的运行时期成本发生在和inlining互动的时候. 虚函数不应该inline.
- 因为inline函数需要在编译器将函数本体拷贝, 而virtual意味着等待, 直到运行期才知道运行谁.
- 多重继承往往导致虚基类的需求(virtual base class), 会形成更复杂和特殊的虚表.
- 一个类只需一份RTTI信息(运行时类型识别), 当某种类型至少拥有一个虚函数, 才能保证检验该对象的动态类型.
- RTTI的设计理念根据类的虚表(vtbl)来实现的.
- RTTI的空间成本只需在每个类的虚表(vtbl)内增加一个条目, 即一个类型信息(type_info)对象空间.
技术
- 惯用手法(idioms)和模式(patterns).
将构造函数和非成员函数虚化
- 虚函数(virtual function)会造成因类型而异的行为.
- 虚构造函数(virtual constructors)很有用.
- 根据不同的输入可能产生不同的对象.
- 虚copy构造函数(virtual copy constructor)会返回一个指针, 指向其调用者的一个新副本.
- 引用计数(reference count);
- copy-on-write(写时才复制).
- 当派生类重新定义基类的一个虚函数时, 不再需要一定声明与原本相同的返回类型.
- 将非成员函数的行为虚化
- 非成员函数(non-member functions)的行为视其参数的动态类型而不同.
限制某个类所能产生的对象数量
- 有时候资源有限, 必须限制能同时产生对象的数量.
- 允许零个或一个对象:
- 阻止对象创建的最简单的方法是将其构造函数声明为私有函数(private).
- 命名空间(namespace)可以阻止名称冲突.
- 类中拥有的一个static对象的意思是: 即使从未被用到, 它也会被构造及析构.
- 函数拥有一个static对象时, 此对象在函数第一次调用的时候才产生, 函数没有被调用的话, 就不会产生该对象.
- 函数每次调用时会检查该对象是否已经被创建.
- 函数拥有一个static对象时, 此对象在函数第一次调用的时候才产生, 函数没有被调用的话, 就不会产生该对象.
- C++中同一编译单元中的static对象初始化顺序有保证, 但不同编译单元内的初始化顺序没有任何说明.
- 将一个对象声明为static, 意味着只需要一份对象.
- 对于非成员函数声明inlining内联函数的话, 该函数会进行内部链接, 内部连接意味着目标代码的copy.
- 所以千万不要产生内含局部static对象的inline非成员函数.
- 不同对象的构造状态
- 避免具体类继承其他的具体类.
- 带有私有构造函数的类不能被用来当作基类, 也不能被用来内嵌于其他对象内.
- 允许对象生生灭灭:
- 将引用计数与伪构造函数相结合起来.
- 这种技术可以用于任意指定个数对象的创建.
- 类的静态成员必须进行义务性定义.
- 在类定义区内为静态常量成员指定初值.
- 一个用来计算对象个数的基类(base class):
- 声明一个基类作为对象计数所用 --- 引用计数技术(reference count).
- 模板类(class template).
- 私有继承后, 基类成员都变成了私有成员.
- 为了恢复public访问层, 可以使用using declaration(using声明).
- 声明一个基类作为对象计数所用 --- 引用计数技术(reference count).
要求(或禁止)对象产生于heap之中
- 要求对象产生与heap之中(Heap-Based Objects):
- 构造函数声明为public, 析构函数声明为private, 并且声明伪析构函数.
- 一个类只有一个析构函数.
- 判断某个对象是否位于Heap内:
new UPNumber(*new UPNumber)会先new空间, 再调用构造函数.
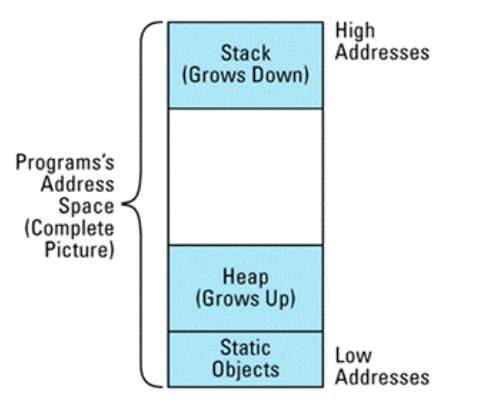
- 程序的地址空间以线性序列组织而成, 其中stack(栈)高地址往低地址成长, heap(堆)由低地址往高地址成长.
- 利用局部变量在栈上的思想判定一个new的对象地址的关系.
- static对象, 全局变量, 命名空间内的对象, 即不放在stack中, 也不放在heap中, 他们被置于heap之下.
- 抽象混合式基类(abstract mixin base class), 是一个不能够被实例化的基类.
- 多重或虚拟基类的对象可能拥有多个地址.
- 禁止对象产生于heap中:
- 对象被直接实例化;
- 对象被实例化为派生类内的基类成分.
- 对象被内嵌于其他对象之中.
- new operator总是调用operator new(可以自行声明).
智能指针(smart pointer)
- 智能指针是一个看起来, 用起来, 感觉起来都像内建指针, 但是提供了更多机能的一种对象.
- 资源管理;
- 自动的重复写码工作.
- 以智能指针取代C++内建指针:
- 构造和析构: 何时被产生以及何时被销毁.
- 赋值和复制(Assignment and Copying), 复制和赋值其所指对象, 执行所谓的深拷贝(deep copy).
- 解引用(Dereferencing): 智能指针有权决定所指之物发生了什么事情.
- 采用lazy fetching方法.
- 远程过程调用(remote procedure calls, RPC).
- 只能指针的构造, 赋值和析构
- 只有当确定要将对象所有权传递给函数的某个参数时, 才应该以by value方式传递auto_ptrs.
- 实现解引操作符(Dereferencing Operators):
- 返回引用值.
- 测试智能指针是否为null:
- 提供一个隐式类型转换操作符来进行测试.
- 将智能指针(smart pointers) 转换为内建指针(Dumb Pointers).
- 不要提供对内建指针的隐式转换操作符, 除非不得已.
- 智能指针(Smart Pointers)和继承有关的类型转换
- 每个只能指针有个隐式类型转换操作符, 用来转换至另一个只能指针类.
- 函数调用的自变量匹配规则;
- 隐式类型转换函数;
- template函数的暗自实例化;
- 成员函数模板(member function templates)等技术.
- 智能指针与const:
- const用来修饰被指之物, 或是指针本身, 或是两者都可以. 智能指针也具有同样的弹性.
- 对于智能指针只有一个地方可以放置const: 只能放置与指针身上, 不能置于所指的对象.
- non-const转换至const是安全的, 从const转换至non-const则不安全.
- 自己实现的智能指针不容易实现, 了解和维护.
引用计数(Reference Counting)
- 引用计数(Reference counting)允许多个等值对象共享同一实值.
- 引用计数可以消除记录对象拥有权的负荷, 因为当对象运用引用计数, 它便拥有自己, 一旦不在有任何人使用它, 它便自动销毁自己.
- 许多对象有相同的值, 如果这些值重复出现肯定不够高效. 让所有等值对象共享一份实值.
- 引用计数(Reference counting)的实现:
- 保存一个引用计数值.
- 写时才复制(Copy-on-Write):
- 各个进程之间往往允许共享某些内存分页(memory pages), 直到它们打算修改自己的那一页.
- 一个引用计数(reference counter)基类:
- 任何类如果不同的对象可能拥有相同的值, 都可以使用引用计数的技术.
- 让一个嵌套类继承另一个类, 而后者与外围类完全无关.
- 将引用计数加到已有的类身上.
- 加上一层间接的封装 --- 计算机科学领域大部分问题得以解决.
- 引用计数是一个优化技术, 其使用前提是: 对象常常共享实值.
替身类, 代理类(Proxy classes)
- 凡是用来代表(象征)其他对象的对象, 常被称为proxy object(替身对象), 替身对象的类称为代理类.
- 二维数组是观念上并不存在的一维数组.
- 读取动作是所谓的右值运用(rvalue usage); 写动作是所谓的左值运用(lvalue usages).
- 返回字符串中字符的proxy, 而不返回字符本身.
- 对于一个proxy, 只有3间事情可做:
- 产生它;
- 以它作为赋值动作的目标(接收端).
- 以其他方式使用它.
- Proxy 类很适合用来区分operator[]的左值运用和右值运用.
- 对proxy取址所获得的指针类型和对真是对象取址所获得的指针类型不同.
- 用户将proxy传递给接受引用到非const对象的函数.
- ploxies难以完全取代真正对象的最后一个原因在于隐式类型转换.
- proxy 对象是一种临时对象, 需要被产生和被销毁.
- 类的身份从与真实对象合作转移到与替身对象(proxies)合作, 往往会造成类语义的改变, 因为proxy 对象所展现的行为常常和真正的行为有些隐微差异.
让函数根据一个以上的对象类型来决定如何变化
- 面向对象函数调用机制(mutil-method): 根据所希望的多个参数而虚化的函数; --- C++暂时不支持.
- 消息派分(message dispatch): 虚函数调用动作.
- 虚函数+RTTI(运行时期类型辨识):
- 虚函数可以实现single dispatch, 利用typeid操作符来获取一个类的类型参数值.
- 虚函数被发明的主要原因:
- 把生产及维护"以类型为行事基准的函数"的负荷, 从程序员转移给编译器.
- 只用虚函数:
- 将double dispatching以两个single dispatches(两个分离的虚函数调用)实现出来:
- 一个用来决定第一对象的动态类型.
- 另一个用来决定第二对象的动态类型.
- 编译器必须根据此函数所获得的自变量的静态类型(被声明时的类型), 才能解析出哪一组函数被调用.
- 将double dispatching以两个single dispatches(两个分离的虚函数调用)实现出来:
自行仿真虚函数表格(virtual function tables):
编译器通常通过函数指针数组(虚表, vbtl)来实现虚函数:
- 决定正确的vbtl索引;
- 调用vbtl中的索引位置内所指的函数.
定义一个函数指针来处理不同类型的对象.
typedef void (SpaceShape::*HitFunctionPtr)(GameObject&);.一定要预先把自行仿真的虚函数表格(virtual function table)进行初始化.
多重继承中的A-B-C-D菱形继承体系应该尽量避免.
使用非成员(non-member)函数的碰撞处理函数
- 匿名命名空间(namespace)内的每样东西对其所驻在的编译单元(文件)而言都是私有的, 其效果就好像在文件里头将函数声明为static一样.
继承 + 自行仿真的虚函数表格
- 扩大继承体系时, 必须要求每个人重新编译.
产生一个注册类, 处理不同的情况.
杂项讨论
在未来时下发展程序
- 好的软件对于变化有很好的适应能力.
- 为每个类处理assignment和copy constructor动作.
- 努力写出可移植性的代码.
- 只要有人删除B*, 而它实际上指向D, 便表示需要定义一个虚析构函数(virtual destructor).
- 如果多继承体系中有任何析构函数, 就应该为基类声明一个虚析构函数.
- 未来思维模式:
- 提供完整的classes;
- 设计接口, 是有利于共同的操作行为, 阻止共同的错误;
- 尽量使代码一般化(泛化), 除非有不良的巨大后果.
- 增加代码的重用性, 可维护性, 健壮性.
将尾端类(non-leaf classes)设计为抽象类(abstract classes)
- 声明函数为纯虚函数, 并非暗示它没有实现码, 而是意味着:
- 目前这个类是抽象的;
- 任何继承此类的具体类, 都必须将该纯虚函数重新声明为一个正常的虚函数.
- 面向对象设计的目标是辨识出一些有用的抽象性, 并强迫他们称为抽象类.
同一程序中结合C++和C
- 结合C++和C程序需要考虑的问题:
- 名称重整(name mangling):
- 名称重整(name mangling)是C++中的一种程序, 为每个函数编出独一无二的名称.
- 绝不要重整其他语言编写函数的名称.
- 压制名称重整(name mangling), 必须在C++中使用
extern "C" { ... }指令. --- 进行C连接. - 不同编译器以不同的方法进行重整名称.
- static的初始化:
- 在main之前执行的代码: static class对象, 全局对象, namespace内的对象, 文件范围(file scope)内的对象, 其构造函数都在main函数之前执行.
- 动态内存分配:
- C++中使用new和delete, C中使用malloc和free.
- 数据结构的兼容性:
- structs可以安全地在C++和C之间往返.
- 名称重整(name mangling):
- 在同一程序中混用C++和C, 应该记住以下几个简单规则:
- 确定C++和C编译器产出兼容的目标文件(object file).
- 将双方都使用的函数声明为extern "C".
- 如果可能, 尽量在C++中撰写main.
- 总是以delete删除new返回的内存, 总是以free释放malloc返回的内存.
- 将两个语言间的数据结构传递限制于C所能了解的形式; C++structs如果内涵非虚函数, 倒是不受此限制.
让自己习惯于标准C++语言
- 新的语言特性:
- RTTI, 命名空间(namespace), bool, 关键字mutable, 关键字explicit, enums作为重载函数的自变量所引发的类型晋升转换, 在类中为const static成员变量设定初值.
- STL(standard template library) --- C++标准程序库中最大的组成部分.
- 迭代器(iterators)是一种行为类似指针的对象, 针对STL 容器而定义.











