
一、项目背景
2017年,vivo互联网研发团队认为调用链系统对实际业务具有较大的价值,于是开始了研发工作。3年的时间,调用链系统整体框架不断演进……本文将介绍vivo调用链系统 Agent 技术原理及实践经验。
vivo调用链系统的研发,始于对 Google的《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》这篇经典文章的学习,我们调研了行业内相关的系统:鹰眼(EagleEye)、分布式服务跟踪系统(SGM)、实时应用监控平台(CAT)、Zipkin、PinPoint、SkyWalking 、博睿等。通过研究分析,我们重点参考学习了 SkyWalking 的埋点方式。接下来我将逐步介绍Agent中用到的一些重点技术。
二、调用链入门
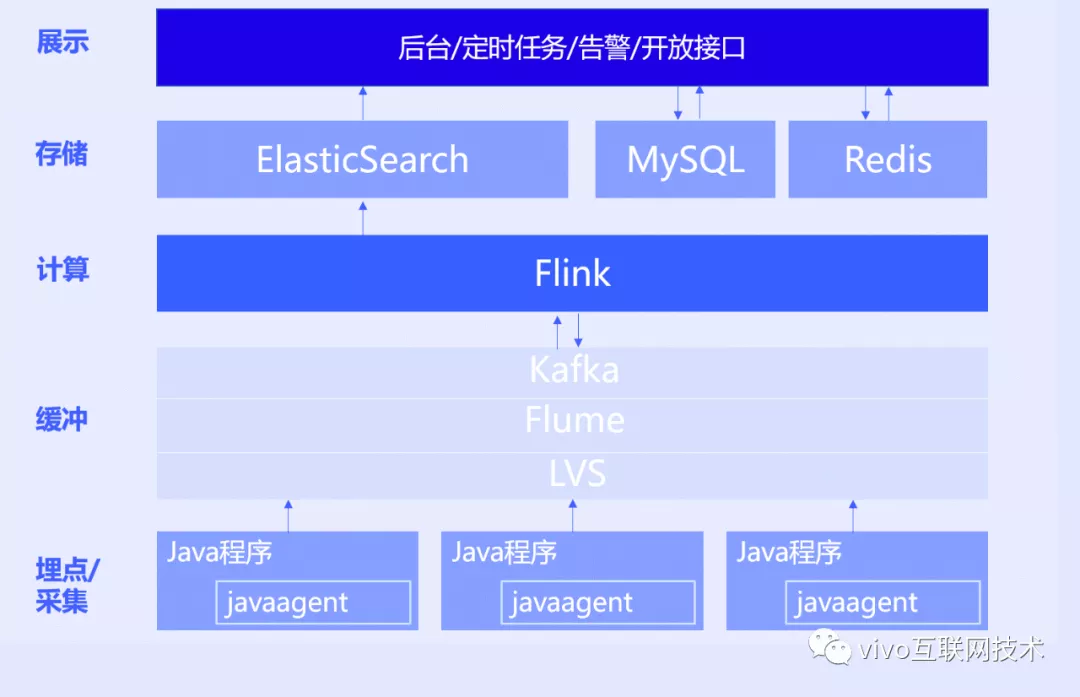
1、整体架构
为了方便读者先有个整体的认知,我们先看下图vivo当前调用链系统整体的架构,Agent 承担了调用链数据的埋点及采集工作,当然这个是当前最新架构,相比项目之初有一些变化。
2、核心领域概念
调用链内部有两个非常核心的概念,分别是trace和span,都源自最初google介绍dapper的文章,无论是国内大厂的调用链产品还是开源调用链的实现,领域模型一般都借鉴了这两个概念,因此如果想很好理解调用链,这两个概念首先需要有清晰的理解。
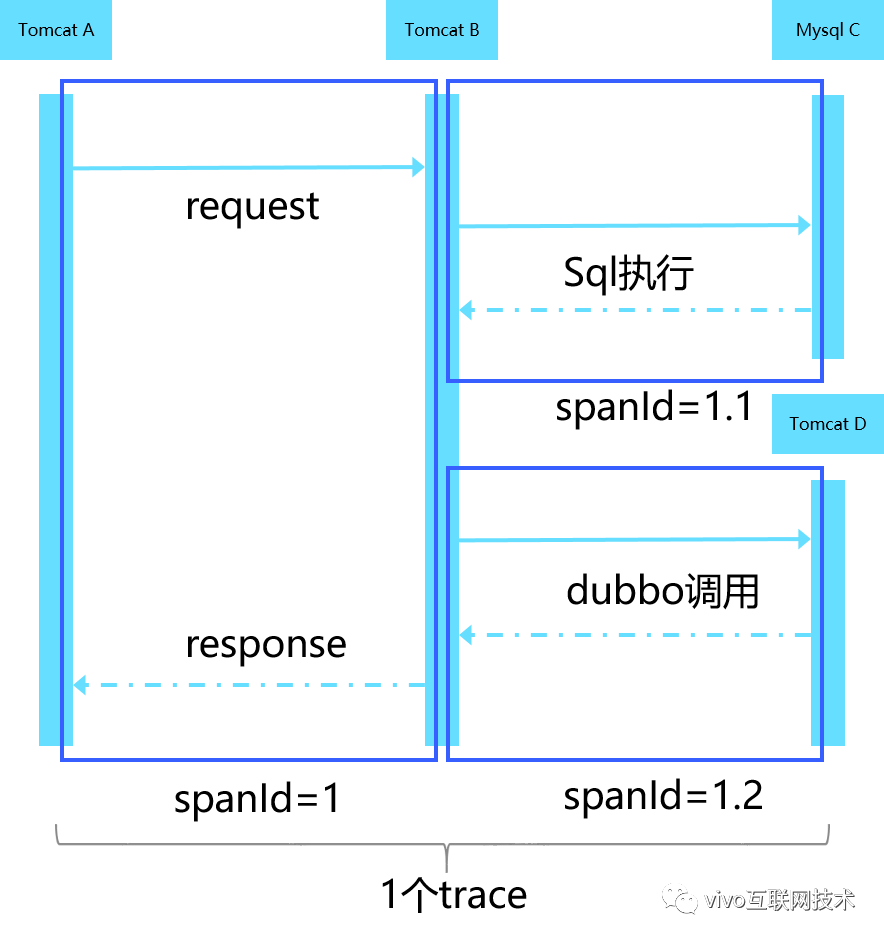
上图模拟了一个简单的场景:
一次请求从手机端发起,路由到后端后首先由nginx转发给服务A来处理,服务A先从数据库里查询数据,简单处理后继续向服务B发起请求,服务B处理完成将结果返回给A,最终手机端成功接收到响应,整个过程是同步处理的。
结合上面模拟的场景,我给出定义:
Trace:相同业务逻辑的调用请求经过的分布式系统完整链路。
我们用traceId标志具体某一次请求调用,当然traceId是分布式唯一的,它串联了整个链路,后文中会介绍traceId的生成规则。注意,相同业务逻辑的请求调用,可以理解为发起调用的入口是同一个接口。由于程序逻辑中存在if/else等分支结构,某一次调用不能完整反映出一个trace链路,只有相同业务逻辑的多次请求调用触达的链路,合成后才算是一个完整的trace链路。
Span:某一次局部请求调用。
一次调用会产生多个span,这些span组成一个不完整的trace;span需要标注本次调用所在调用链路(即span数据中要有traceId信息),以及其所在链路中的层级;spanId同一层级原子自增,跨层级将拼接“.”以及子序列;例如上图中span 1.1和1.2属同一层级,span 1与1.1或者1.2是跨层级;B与D之间的通信是rpc调用,这个过程有4个步骤:B发起调用,接着D接收到请求,然后D将结果返回给B,然后B接收到D的响应。这4个步骤组成一个完整的span,所以B和D各只有这个span的一半,因此spanId需要跨进程传递,后面将介绍如何传递。
3、调用链中数据采集基本逻辑
vivo调用链系统的定位是服务层监控,是vivo互联网监控体系中的重要一环。像服务异常、rpc调用耗时、慢sql等都是基本的监控点。如果埋点采集的数据需要满足调用耗时监控,那么至少在rpc调用及慢sql监控场景下,将以AOP的形式来实现埋点数据采集。vivo调用链Agent除了JVM的指标采集直接使用了java.lang.management.ManagementFactory外,其他都是以类似AOP的形式来实现的。以下为伪代码:
beginDataCollection(BizRequest req);
try{
runBusiness();// 业务代码执行
}catch(Throwable t){
recordBizRunError(Throwable t);
throw t;
}finally{
endDataCollection(BizResponse resp);
}
三、基础技术原理
调用链 Agent开发,涉及到了大量的技术点,以下挑一些关键的来简单介绍。
1、分布式ID(traceId)的生成规则
调用链中的traceId扮演着非常重要的角色,在上面的章节中提到了它用于串联多个进程间分散生成的span,除此之外,Agent端采样控制、入口服务识别、后端flink关键指标计算、用户查询完整调用链路、全局业务日志串联以及 Kafka、HBase和ES数据散列等都依赖于它。vivo 调用链系统traceId是长度为30的字符串,下图中我对有特殊含义的分段进行了着色。

- 0e34:
16进制表示的Linux系统PID,用于单机多进程的区分,做到同一个机器不同的进程traceId不可能重复。
- c0a80001:
16进制的ipv4的表示,可以识别生成这个traceId的机器ip,比如127.0.0.1的16进制表示过程为127.0.0.1->127 0 0 1->7f 00 00 01。
- d:
代表着 vivo 内部的业务运行环境。一般我们会区分线下和线上环境,线下又可分开发、测试、压测等等环境,而这个 d 代表着某个线上的环境。
- 1603075418361:
毫秒时间戳。用于增加唯一性,可通过此读取入口请求发生的时间。
- 0001:
原子自增的ID,主要用于分布式ID增加唯一性,当前的设计可容忍单机每秒10000*1000=1千万的并发。
2、全链路数据传递能力
全链路数据传递能力是 vivo 调用链系统功能完整性的基石,也是Agent最重要的基础设施,前面提到过的spanId、traceId及链路标志等很多数据传递都依赖于全链路数据传递能力,系统开发中途由于调用链系统定位更加具体,当前无实际功能依赖于链路标志,本文将不做介绍。项目之初全链路数据传递能力,仅用于Agent内部数据跨线程及跨进程传递,当前已开放给业务方来使用了。
一般 Java 研发同学都知道 JDK 中的ThreadLocal工具类用于多线程场景下的数据安全隔离,并且使用较为频繁,但是鲜有人使用过JDK 1.2即存在的InheritableThreadLocal,我也是从未使用过。
InheritableThreadLocal用于在通过new Thread()创建线程时将ThreadLocalMap中的数据拷贝到子线程中,但是我们一般较少直接使用new Thread()方法创建线程,取而代之的是JDK1.5提供的线程池ThreadPoolExecutor,而InheritableThreadLocal在线程池场景下就无能为力了。你可以想象下,一旦跨线程或者跨线程池了,traceId及spanId等等重要的数据就丢失不能往后传递,导致一次请求调用的链路断开,不能通过traceId连起来,对调用链系统来说是多么沉重的打击。因此这个问题必须解决。
其实跨进程的数据传递是容易的,比如http请求我们可以将数据放到http请求的header中,Dubbo 调用可以放到RpcContext中往后传递,MQ场景可以放到消息头中。而跨线程池的数据传递是无法做到对业务代码无侵入的,vivo调用链Agent是通过拦截ThreadPoolExecutor的加载,通过字节码工具修改线程池ThreadPoolExecutor的字节码来实现的,这个也是一般开源的调用链系统不具备的能力。
3、javaagent 介绍
在今年初,调用链在 vivo 互联网业务中的接入率达94%之高,这个数据是值得自豪的,因为项目之初自我安慰的错误认知是调用链这种大数据系统无需服务于全部互联网业务,或者当初认为服务于一些核心的业务系统即可。
个人认为能达到这么高的接入率,至少有两个核心的底层逻辑:
之一是 Agent使用了javaagent技术,做到业务方无侵入无感知的接入;
之二是 Agent的稳定性得到了互联网业务线的认可,从17年项目伊始到19年底只有过一次与之相关的业务端故障复盘。
然而一切并不是一开始就如此顺利的,一开始 Agent 埋点模块需要侵入业务逻辑,第一个版本对 SpringMVC 和 Dubbo进行了埋点,需要用户在代码中配置mvc filter和dubbo filter,效率极其低,对那个极力配合第一版试用的业务线的兄弟,现在依旧心怀感恩。后面我们就毅然决然换了javaagent方案,下面我介绍下javaagent技术。
javaagent是一个JVM参数,调用链通过这个参数实现类加载的拦截,修改对应类的字节码,插入数据采集逻辑代码。
开发javaagent应用需要掌握以下知识点:
javaagent参数使用;
了解JDK的Instrumentation机制( premain方法、 ClassFileTransformer接口)及MANIFEST.MF文件中关于Premain-Class参数配置;
字节码工具的使用;
类加载隔离技术原理及应用。
下面我逐个说明:
(1)javaagent配置示例如下:
java -javaagent:/test/path/my-agent.jar myApp.jar
此处javaagent参数配置的jar(这里是my-agent.jar)是由AppClassLoader来加载的,后续章节有介绍。
(2)所谓Instrumentation机制指的是通过jdk中java.lang.instrument.Instrumentation与java.lang.instrument.ClassFileTransformer这两个接口协同进行类的字节码替换,当然替换逻辑的入口在于拦截类的加载。Java的jar中有一个标准的配置文件META-INF/MANIFEST.MF,可以在文件中添加k-v配置。这里我们需要配置的k是Premain-Class,v是一个全限定名的Java类,这个Java类必须有一个方法是public static void premain(String agentOps,Instrumention instr)。这样当你使用 Java命令启动可执行jar时,就会执行到这个方法,我们需要在这个方法里完成字节码转换逻辑的注册,当匹配到特定的类时,就会执行字节码转换逻辑,注入你的埋点逻辑。
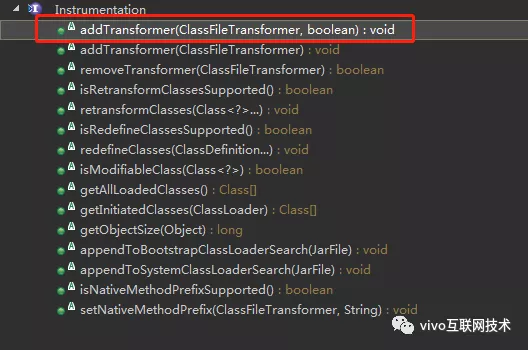

(3)MANIFEST.M文件 中的配置
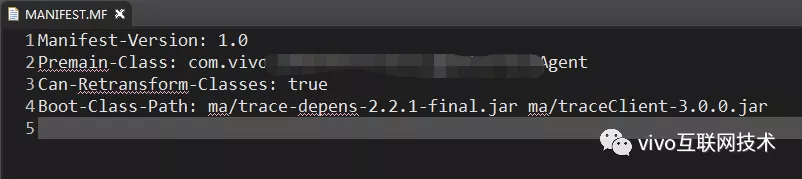
图中Can-Retransform-Classes参数意为是否允许jvm执行转换逻辑,可以阅读Instrumentation这个类中的JavaDoc加深理解。Boot-Class-Path参数用于指定后面的jar中的类由BootstapClassLoader来加载。
(4)关于字节码工具的使用,vivo调用链 Agent用到了以下操作:
修改指定方法的逻辑(嵌入类似AOP的逻辑);
给类增加实例字段;
让类实现某个特定接口;
获取类实例字段与静态字段值、读取父类与接口等等读操作。
4、核心模型数据结构
在上文中我们讲到span含义为一次局部调用,这次调用将分别在服务调用双方产生半个span的数据,在内存中半个span的定义(17年底的定义)如下:
public class Span {
final transient AtomicInteger nextId = new AtomicInteger(0);//用于同一层级的spanId自增
String traceId;
String spanId;
long start;
long end;
SpanKind type;//Client,Server,Consumer,Producer
Component component;//DUBBO,HTTP,REDIS......
ResponseStatus status = ResponseStatus.SUCCESS;
int size;//调用结果大小
Endpoint endpoint;//记录ip、port、http接口、redis命令
List<Annotation> annotations;//记录事件,比如sql、未捕获异常、异常日志
Map<String, String> tags;//记录标签tag
}
看了上面的定义你就能大致知道调用链的各个功能是如何计算出来的了。
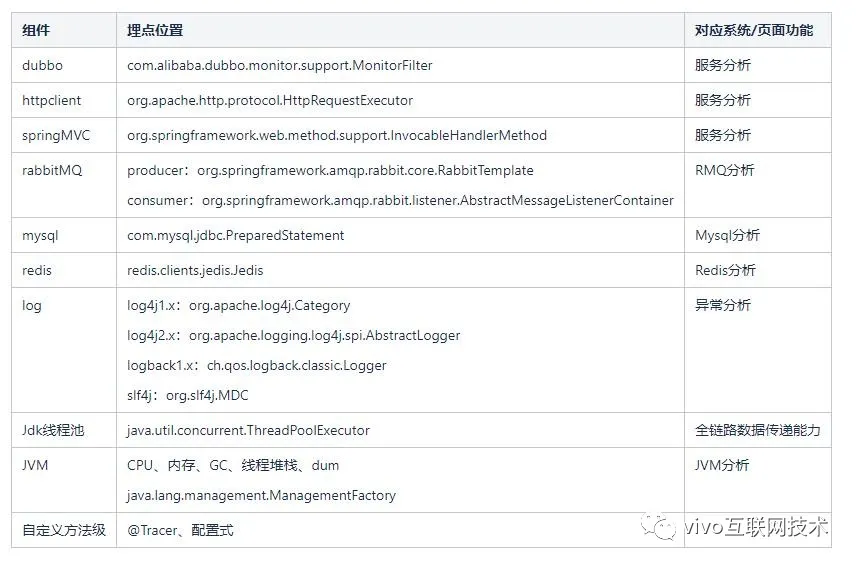
5、各组件埋点详情
这里我罗列了截止2019年底vivo调用链 Agent埋点覆盖的组件,及埋点的具体位置。据了解,今年vivo调用链系统进入3.0版本后,新增了超过8个埋点组件,采集到的数据越来越丰富了。
6、半自动化埋点能力介绍
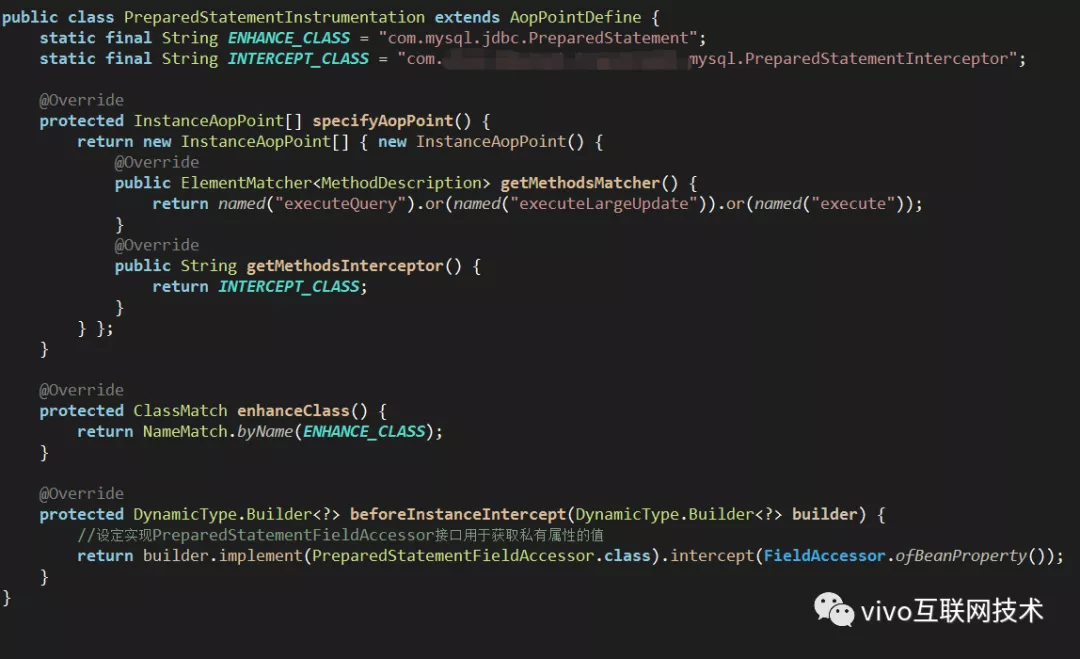
经过对埋点能力较深的封装后,Agent中新增加一个组件的埋点是非常高效的,一般情况步骤如下,可以结合上图来了解:
对需要埋点的第三方框架/组件核心逻辑执行流程进行debug,了解其执行过程,选定合适的aop逻辑切入点,切入点的选取要易于拿到span中各个字段的数据;
创建埋点切面类,继承特定的父类,实现抽象方法,在方法中标注要切入埋点的方法,以及用于实现aop逻辑的interceptor;
实现interceptor逻辑,在openSpan方法中获取部分数据,在closeSpan中完成剩余数据的获取;
设置/控制interceptor逻辑所在类可以被Thread.currentThread().getContextClassLoader()这个类加载器加载到,然后打开此组件埋点逻辑生效的开关。
可见,当前新增一个组件的埋点是非常容易的,2018年2.0版本项目中期的目标是全自动化,期望通过配置即可实现部分类的自动生成,尽可能少的代码,新增埋点更加高效,但是由于个人精力不足的原因,未能持续优化来实现。
7、span数据流图
我们再来看下span从产生到发送到kafka的完整生命周期。
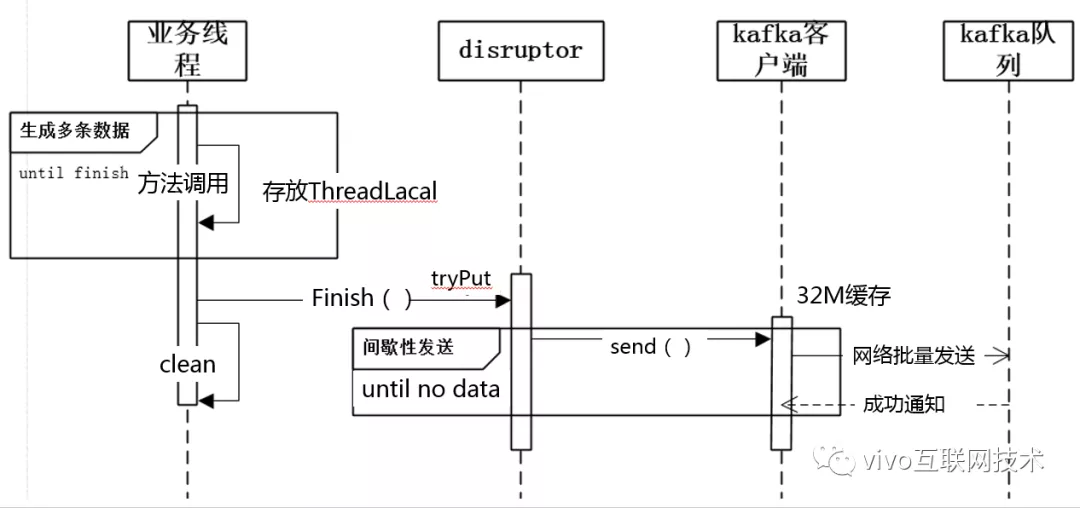
图中可以看出,在生成完整的(closeSpan()完成调用)半个(参考调用链入门之核心领域概念小节)span后,会首先缓存在ThreadLocal空间。在完成本线程全部逻辑处理后,执行finish()转储到disruptor,再由disruptor的消费者线程定时刷到kafka的客户端缓存,最终发送到kafka队列。
在做内部分享的时候,这里有两个问题有被问到,一是kafka客户端自身有缓存,为啥中间还要有个disruptor,第二个是执行finish的时机。这里原因也很简单,首先因为disruptor是无锁不阻塞并且队列容量可限定的,jdk中的线程安全的要么是阻塞的要么是无法限制初始容量的,kafka客户端的缓冲区显然也不满足这个条件,我们决不可阻塞业务线程的执行。第二个问题用栈(LinkedList)这种数据结构来解决即可,线程执行到第一个埋点切点处执行openSpan时进行压栈,执行closeSpan时执行弹栈,当栈中无数据时即应当执行finish。
8、丰富的内部治理策略
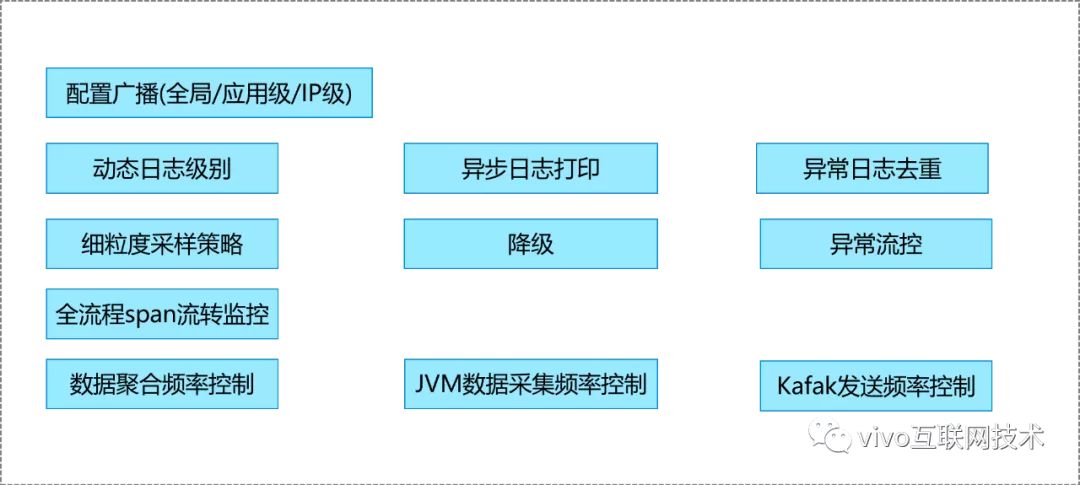
项目之初的主要目标是业务的接入量及产品能力的适用性,不会太多考虑内部治理,但是数据量大了后必然要更多的考虑自身的可治理性了,上图中展示了截止2018年底Agent中的主要的内部治理能力。下面我逐个介绍下各项治理能力的背景。
(1)****配置广播:
置下发能力是其他各项治理能力的基石,Agent在premain方法执行时会去vivo配置中心主动拉取配置,如果配置中心配置有变动,也会主动将配置推送下来。另外,Agent内部依赖配置的地方众多,内部配置的生效也是基于 JDK 中的Observer监听机制实现配置分发的。
(2)****日志策略:
在2017年的时候,vivo互联网业务方兴未艾,统一日志中心的能力较弱,大量的异常日志会对日志中心造成冲击,因此需要做异常流控。在异常情况下减少异常堆栈的打印,并且Agent还要能响应业务的需求采集指定级别的业务日志,比如由于日志打印规范不明,日志打印混乱的原因,有业务希望将warn或者某个类的info级别的日志,采集到调用链系统中供问题排查。另外,Agent自身是需要打印日志的,这个日志打印的代码在字节码增强后是嵌入到三方框架中的,也就是说业务逻辑执行到三方框架中时可能造成执行变慢,影响业务性能,因此需要异步输出日志。最后需要提到的一点是,日志的打印在Agent中是自己实现的,为了避免与业务方使用的日志框架造成类冲突,是不能使用第三方日志框架的。
(3)****采样策略:
在2018年初,接入不到200个服务时,采集的span数据已经占据了10台 Kafka 物理机的容量了,必须进行流量控制,采样是重点。但是当初的采样逻辑会带来新的问题,就是导致业务tps不精准,因此后面将tps等数据独立进行采集了。
(4)****降级:
这个容易理解,就是要支持动态控制不采集某个服务的数据,或者不采集某个组件的数据,或者业务方希望在活动的时候关闭调用链。
(5)****异常流控:
调用链对日志组件进行了埋点,也能拦截到业务方未捕获的异常,会将这些数据采集并存储到调用链系统中,如果太多异常了,系统自身也撑不住,因此这里的异常流控指以一定频率控制相同异常不传递到后端。
(6)****全流程span流转监控:
Agent中会监控span的流转过程进行计数(产生、入队、出队、入Kafka成功/失败、数据丢失),当发现数据丢失时,可选择调大内存无锁队列的容量或者调小Kafka发送间隔,当发现发送 Kafka失败时,意味着网络或者kafka队列出了问题。
(7)****数据聚合频率控制:
在18年中,据评估span原始数据后期将会增长到每天1500亿条,调用链系统无足够资源处理这么大规模数据量,因此我们很快在Agent端实现了端的数据聚合能力,将初步聚合后的数据丢给flink做最终的计算,减少Kafka和大数据集群的压力。
(8)****JVM采样和kafka发送频率控制:
Agent会定时采集JVM指标,比如gc、cpu、JVM 使用内存、各状态线程数等等,在经过flink计算后会在页面显示出折线图,这个采集间隔是严格的5s,为了控制数据量,需要做到动态调控采集间隔。另外Agent端生成span数据首先缓存到了内存无锁队列,然后定时批量发送Kafka,为了兼顾告警的实时性及Agent端的cpu的损耗,这个频率默认是200ms,同时也支持远程调控。
四、Agent稳定性保障
上文提到过,当前Agent在几千个应用中接入率达94%之高,个人认为有一个重要原因是其稳定性被业务方认可。那么如果要保障自身的稳定性,不对业务造成影响,对于调用链Agent来说,首先一定要尽可能的减少对业务线程执行的干扰,其次要尽可能多的考虑到边界问题
1、全程不阻塞业务流程
减少对业务线程执行干扰的出发点在于不阻塞业务线程,我们来梳理下对业务线程的阻塞点,然后逐个介绍下处理办法。
(1)****线程阻塞点1——日志打印:
disruptor处理。使用disruptor对日志进行无阻塞缓存,同时坚持令可直接丢弃日志也不要阻塞的原则。
(2)****线程阻塞点2——埋点逻辑:
措施1:span生成时缓存到ThreadLocal中,高效批量转储到disruptor,避免多次的disruptor生产者屏障的竞争;
措施2:埋点过程中必不可少的会使用到反射,但是反射是有坑的(点击此处了解),分析反射逻辑的源码,矫正反射使用的姿势;
措施3:可能的话不要使用反射,而是通过字节码技术让埋点类实现自定义特定接口,通过执行正常的方法调用来获取对象实例数据。
措施4:在ThreadLocal与disruptor,及disruptor与Kafka的数据转储过程中,池化大的集合对象,避免过多的大内存的消耗。
(3)****线程阻塞点3——span数据发送 :
同样,使用disruptor来解决线程阻塞的问题。
2、健壮性
边界问题的考虑及解决是极大依赖开发人员的个人经验及技术能力的,下面我列了几个重点的问题,也是业务方担忧较多的问题。
(1)如果Agent自身逻辑有问题怎么办?
全程try-catch、自身异常的话相同异常日志2分钟内只打印一条。
(2)如果无法及时避免阻塞业务线程怎么办?
降级,直接退出单次埋点流程。
(3)如果业务太繁忙cpu消耗大怎么办?
采样控制+频率控制+降级;
直接丢弃数据;
自定义disruptor的消费者等待策略,在高性能与高消耗之间做平衡。
(4)如果消耗过多内存怎么办?
严格对内存数据对象进行计数限制;
数据流转过程中难以控制的大内存消耗点使用SoftReference。
(5)如果Kafka连不上/断连怎么办?
支持降级的同时,可选启动连不上直接退出Agent阻止程序启动,运行时断连直接丢弃数据。
五、难点技术及关键实现简介
下面会简单介绍下Agent中的一些关键的难点技术。其中最为难以掌控的是Agent中的类需要控制被哪个类加载器来加载,不然你一定会痛苦的面对各种ClassNotFoundException的。
1、启动流程
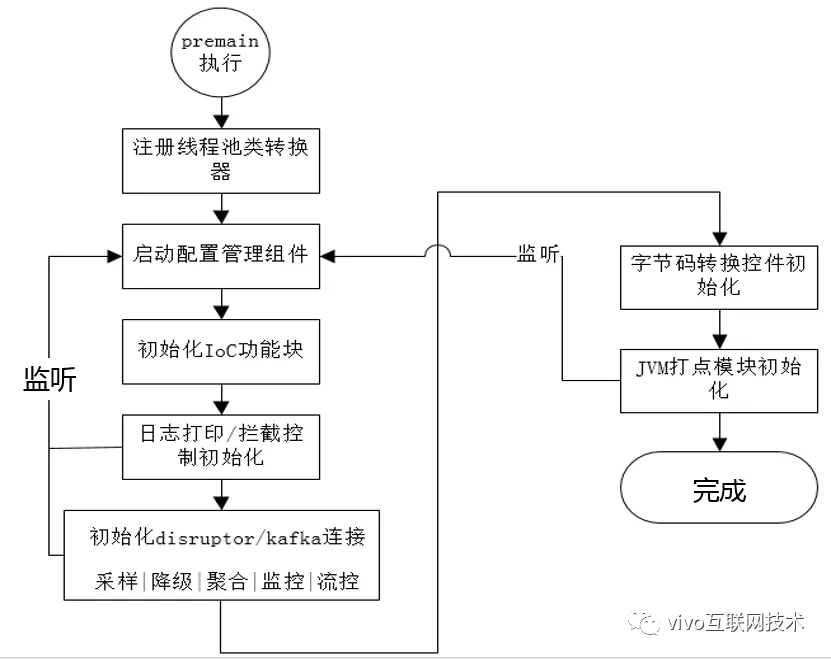
Agent启动流程看起来是简单的,这里贴出来可以方便内部的同学阅读源码。需要注意的是启动伊始是以premain方法作为入口,这个方法所在类由AppClasssLoader来加载。启动流程中需要控制好Agent中的哪些类或者模块由哪个类加载器来加载,并且部分类是通过自定义类加载器来主动加载的,不同的类加载器逻辑执行空间的衔接,是通过jdk中的代理模式(InvocationHandler)来解决的,后面会做介绍。
2、微内核应用架构
Agent的主要职责是埋点和数据采集,埋点理当是整个Agent中最为核心的逻辑,以下简单介绍下围绕核心的各个功能块功能,图中除了类隔离功能外,其他功能块都是可以直接去掉而不影响其他模块的功能,遵循了微内核应用架构模式。

日志:自定义实现
适配环境,不同环境不同行为;
适配slf4j;
日志级别动态可控;
自动识别相同error日志,避免冲击日志中心。
监控:可靠性的基石
监控埋点数据完整的生命周期(产生、入队、出队、入kafka成功/失败、内存队列消耗状况、数据丢失情况);
监控jvm采样延时状况。
策略控制功能块:
基于观察者模式广播配置变更事件;
控制着采样、日志级别、业务日志拦截级别、降级、异常流控、监控频率、jvm打点频率、数据聚合。
字节码转换控制功能块:
组件增强插件化(可配置);
增强逻辑之间相互隔离;
增强逻辑高度封装,实现配置化;
核心流程模仿spring类的继承体系,具备强可扩展性。
流程控制功能块:
应用内部高度模块化;
SPI机制高可扩展。
类隔离控制单元:
自定义多个类加载器,加载不同位置及jar中的类;
兼容 Tomcat 和 JDK 的类加载器的继承关系,主动让 Tomcat或者 JDK 中特定类加载器显式加载类;
干扰类的双亲委派模型,控制特定类的父类或者接口的加载。
3、核心技术栈

图中箭头的方向,意为由上而下的技术使用难度的增大,同时需要用来研究及调优的时间消耗也增加。其中 Java 探针技术即是上文中介绍的javaagent,ByteBuddy的选型报告及背景在下文中有介绍,disruptor主要是需要花费较多时间进行技术背景理解、源码阅读及调优,后文也有介绍,而类加载控制的应用,是项目之初最为头疼的难点,犹记得17年底处理ClassNotFoundException时的绝望,远远不是了解如何自定义类加载器及双亲委派这些知识能解决的。当初买了好几本有相关知识介绍的书籍来研究,哪怕是在这本书的目录中仅仅发现了可能不到1页的并且也只是可能相关的篇幅,买书投入都花了好几百块。
4、类加载及隔离控制
需要注意的是,类加载隔离的控制目标是自己用到的三方包不与业务方的三方包因版本产生冲突,并且保证Agent中逻辑执行时不出现找不到类的问题,这里简单画了Agent中的类加载隔离情况,可以结合上面的小节来简单理解。
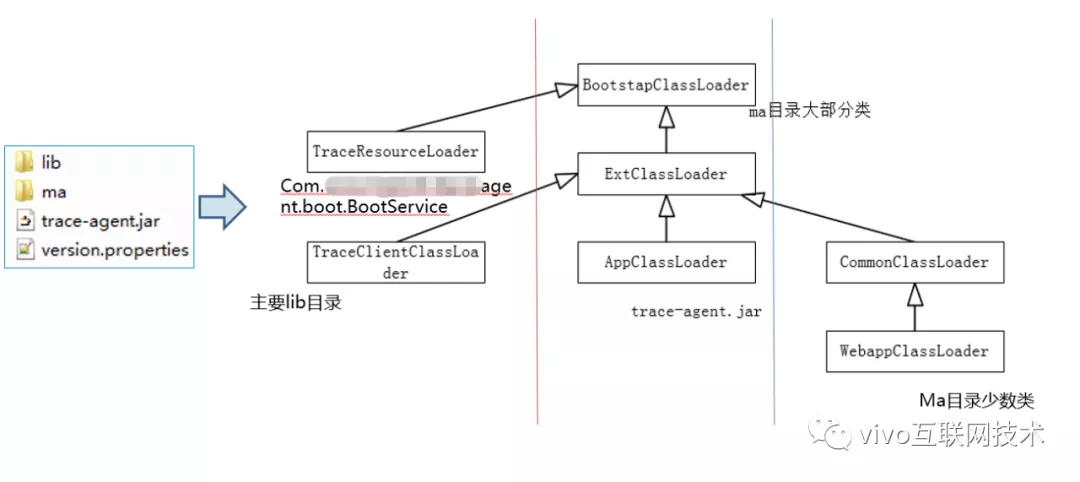
这里我尝试罗列需要掌握的知识点:
类加载的4大时机;
premain所在类的加载及执行逻辑;
JDK 的双亲委派模型,及如何实现自定义加载器,如何更改加载顺序;
JDK 中的全部类加载器的研究。当初误入歧途,恨不得去研究 JVM 部分看不懂的C++源码;
Tomcat类加载架构,相应部分源码阅读;
类加载器执行空间的跳转。
六、部分选型报告
整个调用链系统在开发时涉及到了非常多的关键技术的选型,这里仅给出Agent相关的两个关键技术。
1、字节码操控工具ByteBuddy
字节码编程对于普通的 Java程序员来说,算是能玩的最牛的黑科技了。什么是字节码编程呢?相信你一定多多少少了解过 javassist、asm等字节码编辑库,我们在进行字节码编程时,一般会借助这些库动态的修改或者生成 Java字节码。例如Dubbo就借助了javassist来动态生成部分类的字节码。选择 ByteBuddy的原因主要是项目之初参考了SkyWalking的埋点逻辑,而那时SkyWalking就是使用的ByteBuddy。如果现在来选择,我会优先Javassist,下面罗列了几个框架个人理解的优缺点。
(1)ByteBuddy
基于ASM做的封装,使用到的开源项目:Hibernate、Jackson。
优点:
在特定场景下使用非常方便;
17年框架的作者非常活跃,支持最新jdk几乎全部新特性;
容易定制扩展。
缺点:
- 领域模型定义混乱,类图设计复杂,内部类可以深达8层,eclipse都无法反编译若干类,源码难以调试及阅读,对深度使用者极度不友好,我们一般开发使用的内部类极少会超过3层,想象下8层深的内部类是怎么样的!
(2)ASM
开源项目:Groovy/Kotlin编译器、CGLIB、Spring。
优点:
写出来的代码很显野蛮牛逼的气息,面向字节码编程是 Java语言级别的黑科技;
愿景致力于性能和精小,全部代码只有28个类。
缺点:
使用起来比较复杂,编码效率低下;
需要比较了解 Java语言字节码指令集,需要比较清楚class文件内容布局。
(3)Javassist
开源项目:Dubbo、MyBatis。
优点:
使用简单快速易上手;
先生成字符串再编译成字节码的使用方式,对程序员来说很容易理解;
官方文档示例易理解,且很丰富。
缺点:
- 自带的编译器与 Javac有一定差距,难以实现复杂功能和新版jdk新特性。
2、环形无锁队列Disruptor
使用Disruptor的原因,主要是其高性能的同时,能做到限制容量也不阻塞,这简直太让人满意了,而 JDK 中的线程安全相关集合皆无法满足。
(1)主要特点:无阻塞、低延迟、高消耗。
(2)使用场景:
高并发无阻塞低延迟系统;
分段式事件驱动架构。
(3)为何这么快?
使用了volatile和cas无锁操作;
使用了缓存行填充手段避免伪共享;
数组实现预先分配内存,减少了内存申请和垃圾收集带来延迟影响;
快速指针操作,将模运算转换成与运算(m % 2^n = m & ( 2^n - 1 ))。
(4)使用注意事项:
消费者等待策略:综合业务线程阻塞、cpu损耗、数据丢失情况做的综合考虑。
七、总结
要做好调用链系统的研发,显然是一个困难的工作,难点不仅仅在于 Agent 技术难点解决,也在于产品能力的决策与挖掘,在于怎样用最少的资源满足产品需求,更在于当初不懂大数据的 Java开发在有限资源前提下来做海量数据计算。
希望本文能给正在从事以及将会从事调用链系统研发的公司及团队一点参考。感谢阅读。
作者:Shi Zhengxing












