
写在前面
许久不见,各位读者,上次更文已经是去年了,快两个月没发文章了,谢谢大家没有取关。没有加我微信的朋友,可能不知道我于去年12月当上了爸爸,算是我人生的一个重大变化。工作还未满两年,在25岁成为了父亲,还是挺有压力的,会有紧张感,所以也停更了一段时间,好好整理自己。现在我回来啦!今年还是会好好写文章,分享有价值的文章给读者。希望能提高自己的输出频率,多多输出,一起进步!
这次给大家分享的是Kafka的10道面试题,就难度我觉得是比较基础的,但考的知识点还比较全面,可以用来考察自己掌握Kafka基础的程度。
1. Kafka是什么?
Kafka起初是一个多分区、多副本且基于ZooKeeper协调的分布式消息系统,现已被定位为一个分布式流式处理平台。
2. Kafka的架构了解吗?
建议按以下顺序讲述:
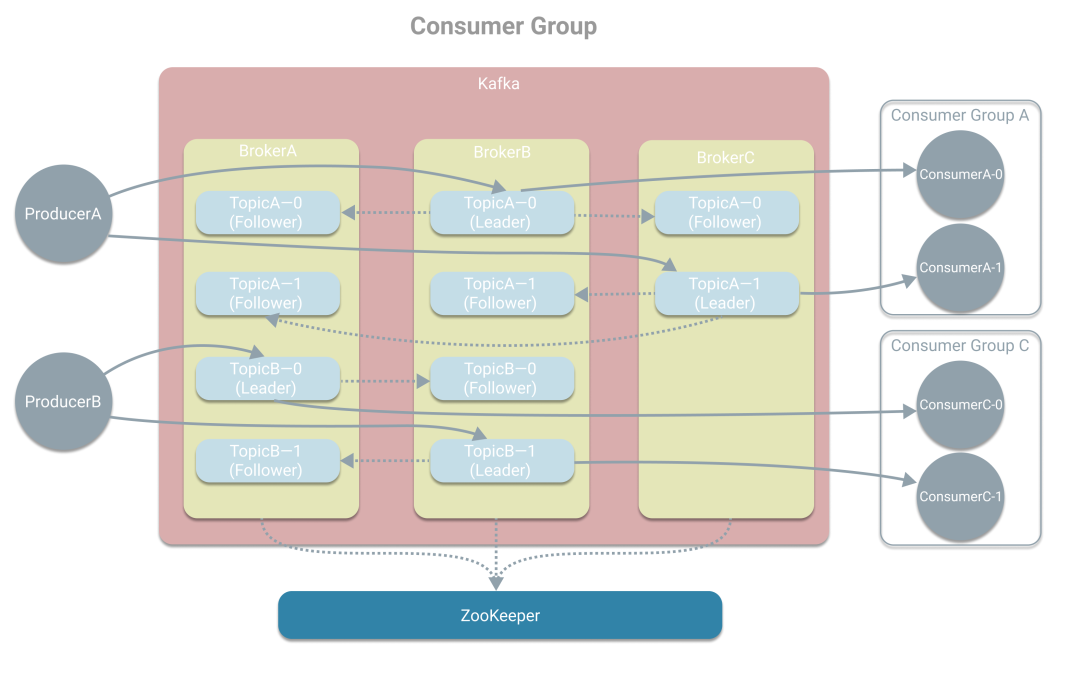
Kafka是基于发布/订阅的消息系统(引出Producer、Consumer和Broker),所以存在三个角色 Producer(生产消息)、 Broker(Kafka实例)和 Consumer(消费消息)。
生产者会将消息推送到Kafka的某个 Topic上,以此 区分消息。
为了高可用性,通过在集群上部署多个Broker,一个Topic将以 多副本的形式分布在多个Broker上,基于ZK选出一个Leader副本,而其他Follower副本则负责同步Leader副本,避免单点问题。
为了高吞吐量,再将Topic划分成多个 分区,可让Topic的吞吐量不受单机限制。
为了高吞吐量,对于多个分区,单个消费者也可变成多个,形成 消费组,一个分区由一个消费者负责。
最后可画出下图,如想看逐步的画图过程,可看下《图解Kafka中的基本概念》。
3. 了解其他MQ吗?有什么不同?
有了解RadbbitMQ,RabbitMQ由于有消息确认机制,所以数据丢失的可能性更小,适合严格的金融场景。
而Kafka的优势则在于其吞吐量更大,适合处理活跃的流式数据。
4. 如何保证消息的有序性?
Kafka只能保证局部有序,即只能保证一个分区里的消息有序。而其具体实现是通过生产者为每个分区的消息维护一个发送队列,我们需要将保证顺序的消息都发送到同一个分区中。并且由于Kafka会同时发送多个消息,所以还需指定max.in.flight.requests.per.connection为1,保证前一个消息发送成功,后一个消息才开始发送。
max.in.flight>1 时能保证有序性吗?
可以,设置幂等能保证。不过max.in.flight不能大于5。这是因为Broker端只会缓存最近5个Batch的SequenceNumber,例如我们发送1到6的报文,其中1发送失败,2-5发送成功,Broker缓存下来,当1重试时,Broker检查到1小于缓存中的最小序号,会抛出异常,而Producer将重试发送1超过最多次数或超时,影响性能。
幂等如何保证有序性?
通过引入ProduceID(PID)和SequenceNumber的概念,每个Producer在初始化时被分配唯一的PID,而<Topic,Partition>的每条有一个从0单调递增的SequenceNumber。在发送消息时,由以下三点保证:
验证序号连续:Broker会验证Batch的SequenceNumber是否连续,若不连续,抛出异常;
重试时,batch放置正确位置:Producer请求重试时,会根据SequenceNumber将Batch放在队列中的合适位置;
重试时,max.in.flight调为1:当请求重试时,会把max.in.flight动态调整为1,保证请求序号小的先发送成功。
5. 如何保证幂等?
Kafka具有幂等机制,但默认不开启,需要设置enable.idempotence为true开启。但只能实现单会话、单分区上的幂等。
为什么只能实现单会话上的幂等?
在Producer初始化时,Kafka会为其重新分配一个新的PID,而Broker端在维护SequenceNumber时是以<ProducerID, Topic, Partition>作为维度,因此当PID变化时Broker将无法获得之前的状态信息,无法做到单会话上的不丢不冲。
如何实现跨会话幂等?
事务机制,通过引入TransactionID和Epoch。不同于PID是由内部进行分配,TrasactionID是由用户提供。而TransactionID与PID会一一对应,这样当Producer宕机时,集群启动一个新的Producer,在初始化时可以通过TransactionID获得PID,便能继续工作。同时会被分配一个单调递增的Epoch,来保证当旧Producer恢复后可能生产出重复消息,Broker段会拒绝旧Epoch的消息。
6. 支持什么语义?
三种语义:
最多一次(At Most Once):不会重复发送,可能消息丢失
最少一次(At Least Once):会重复发送,消息不会丢失(默认)
只有一次(Exactly Once):不会重复发送,消息不会丢失
7. 如何保证Exactly Once语义?
Producer幂等 + At Least Once = Exactly Once(单分区、单会话)
事务可实现跨分区、跨会话的Exactly Once语义
8. 消息重复的场景有哪些?如何解决?
Broker在写入消息后,Producer没有收到成功的响应。
解决方法:
启动幂等;
acks = 0,不重试,但会丢失消息。
9. 消息丢失的场景有哪些?如何解决?
(一)Producer端丢失消息
在调用send方法时,由于网络原因发送失败。
解决办法:设置retries为一个合适的值,一般为3,此外重试的间隔不能太小,避免网络一次波动的区间就把三次重试用完了。
(二)Consumer端丢失消息
自动提交offset时,可能未来得及处理消息,但offset已被提交。
解决办法:关闭自动提交,消费完后手动提交offset。
(三)Broker端丢失消息
Leader副本所在的Broker宕机,而Follower副本还没有完全通过Leader
解决办法:
设置acks =-1或ALL,保证Follower副本写入消息;
replication.factor > 3,保证分区至少有3个副本,冗余消息;
min.insync.replicas >1,消息至少被写入2个副本才认为成功;
unclean.leader.election.enable=false,避免从非ISR中选举Leader。
10. Kafka吞吐量高的原因
顺序写:写读数据时,数据直接追加在文件的末尾;
MMAP:数据不实时写入硬盘,以此提高IO效率;
零拷贝:读数据时,使用了sendfile,磁盘文件读到OS内核缓冲区后,直接转到socket buffer进行网络发送;
批量压缩:消耗少量的CPU资源,提高IO效率;
一句话贯穿:Kafka把所有的消息都变成一个个批量的文件,并且进行合理的批量压缩,减少网络IO的损耗,写入是通过MMAP提高IO效率,同时由于单个分区是顺序写文件,所以速度最优;读取数据的时候配合sendfile直接暴力输出。
以上就是本次分享的10道Kafka面试题,有问题的地方,欢迎留言交流。
我是草捏子,一只热爱技术和生活的草鱼,我们下期见!
参考资料
[1]
Kafka 面试题:基础 27 问,必须都会的呀: https://xie.infoq.cn/article/6c879c4c3b52e416f251b2909
[2]
八年面试生涯,整理了一套Kafka面试题: https://juejin.cn/post/6844903889003610119
[3]
32 道常见的 Kafka 面试题你都会吗?附答案: https://www.iteblog.com/archives/2605.html
[4]
Kafka面试题与答案全套整理: http://trumandu.github.io/2019/04/13/Kafka%E9%9D%A2%E8%AF%95%E9%A2%98%E4%B8%8E%E7%AD%94%E6%A1%88%E5%85%A8%E5%A5%97%E6%95%B4%E7%90%86/
[5]
大数据Kafka面试题: https://zhuanlan.zhihu.com/p/107350990
[6]
面试官问我如何保证Kafka不丢失消息?我哭了: https://juejin.cn/post/6844904094021189639
[7]
Kafka速度快的原因: https://www.linuxidc.com/Linux/2019-11/161504.htm
[8]
万字长文干货 | Kafka 事务性之幂等性实现: https://cloud.tencent.com/developer/article/1430049
[9]
Kafka事务特性详解: https://www.jianshu.com/p/64c93065473e
本文分享自微信公众号 - java宝典(java_bible)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。












