PostgreSQL 是非常好的开源的数据库,针对替换ORACLE数据库的重任,基本上大部分中小型企业,能指望的也只有POSTGRESQL ,当然如果你愿意花更多的前,更多的应用程序结构方面的改造,MYSQL 也不是不可以, ORACLE 换成PG 就如同,你从一个中单的一个房间 换到另一个房间, 如果要是ORACLE 到MYSQL ,就如同你从北京,搬到上海. 所以如果不想大动干戈, 并且不想改变现有的整体架构, PG 一定是必然的选择,没有其他.
那在使用PG的时候,可能很快就会体会到PG之美, 与功能强大,这里就不在多说,今天要说的是,POSTGRESQL 在高并发下,超高连接对PG的冲击,以及为什么PG 在高并发连接中,需要使用pgbouncer或pgpool 来.
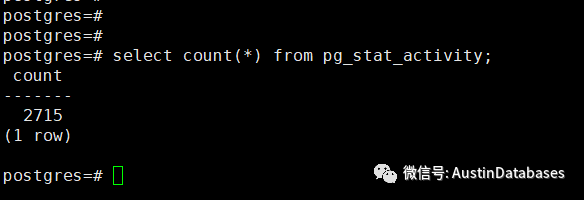
首先就要祭出原理, 到底连接分配的内存要从哪里来出,大部分人包括我,认为,导致PG 无法接受大量连接的主要原因,其实是内存. 由于大量的连接使用了大量的内存,导致,PG 在接受大量的connections 会导致, OOM, 或者性能低下.
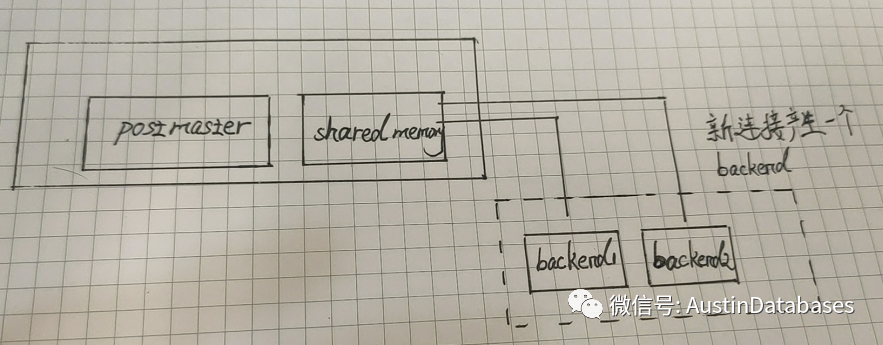
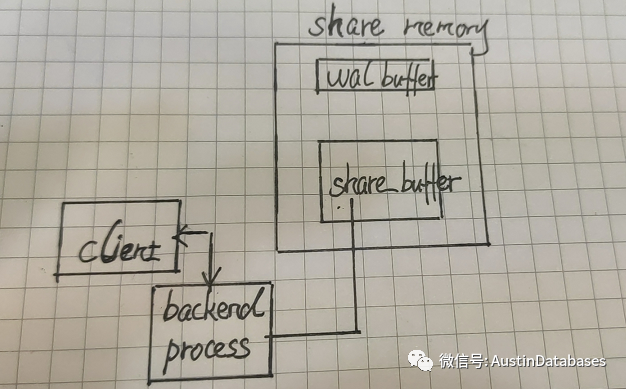
但实际上我们做一个测试,我对一个有用8G 内存的 PG ,加载3000个并发连接并且查询一个表,同时将 shared_buffers 调整成20MB ,然后我就等待着PG崩溃.
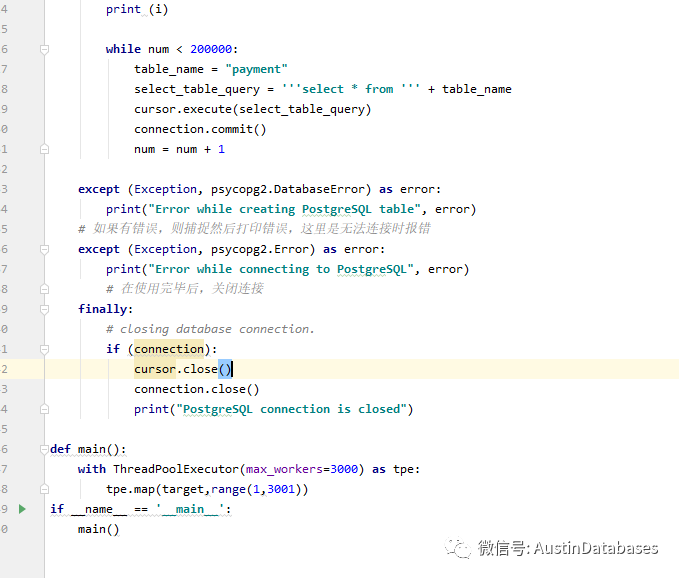
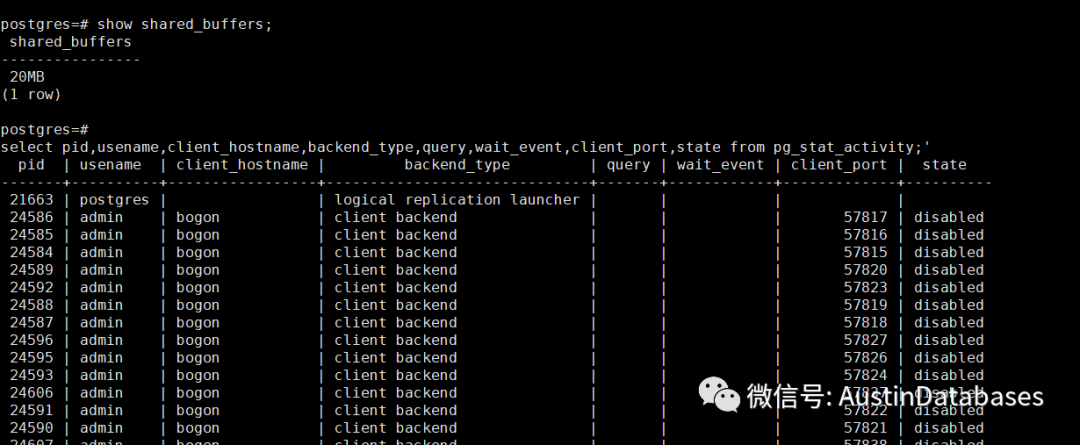
实际上我并没有如愿, PG 还是稳稳的运行, 但系统有一点缓慢,有点卡的感觉
内存方面
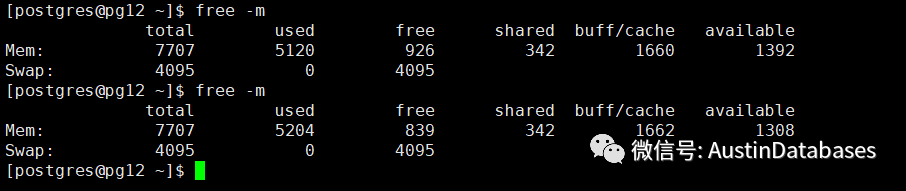
也并没有像我与预期的会彻底的用光.
那么问题来了, 到底各种 大小广而告之,中提到的PG 不适宜 多连接的原因在哪里.
那就的从 PG 的源码中的 PGPROC 说了,
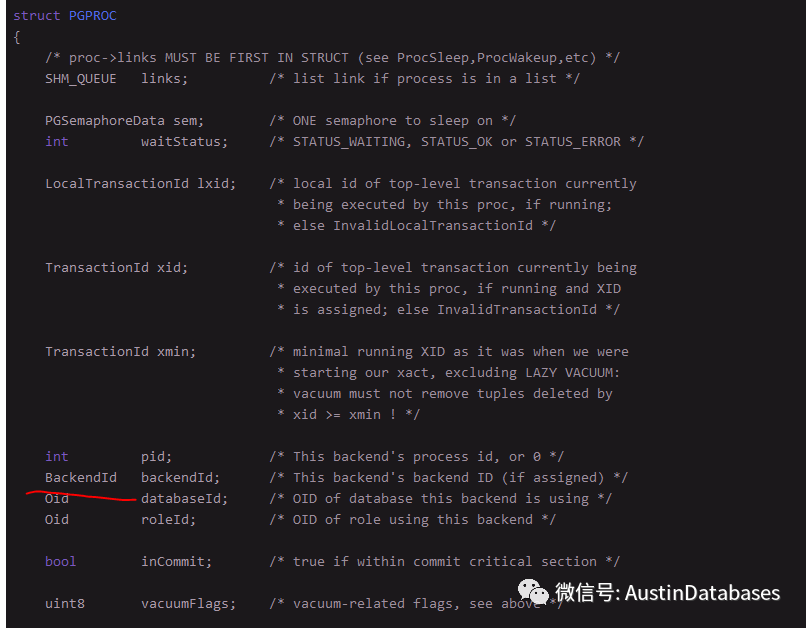

其中上面的each backend has a PGPROC struct in shared memory , + 后面的那句, 应该表明 backend 和 shared memory 之间 存在一个pgproc的结构, 这个结构的主要作用就是 复用.
后面的NOTE 的twophase.c 证明了PGPROC 结构的复用,因为当前的transaction 在队列中 有两个状态, 真正运行和准备运行.
这个PGPROC 会在 PROC_HDR中被调用, allProcs 是一个指针,也就是所有的PGPROC 都会在这里面.PGPROC 主要的作用是要在事务处理期间处理相关例如等待和处理等工作之间的切换,PROC 主要的作用进程间协同和通讯以及postmaster的跟踪



而为了获取这些信息的变化对share_buffer 和 backend 的临时数据进行获取,他会遍历到其他的process 中, 而如果我们建立的backend越多, 也就是连接到PG的连接越多, 就会导致遍历GetSnapshotData 的工作消耗更多的系统资源,例如CPU.
由于查询是最简单的 select 语句,并且应该也应用到了缓存,IO性能基本上处于没有使用的状态

内存的使用也未占满.
多连接并不是通过内存的消耗,将PG 带入到OOM 和系统无响应的情况中, 而是随着backend变多后,内部沟通的成本太高,导致性能上的问题,所以PG的在多连接中,是需要使用PGPOOL 或者 pgbouncer 之类的缓冲池来保证系统的性能,另外还有一个问题就是为什么要有这么多的连接, 这就是一个问题.
那既然知道了PG在处理超多的连接上会有性能的问题,那如何解决这个问题对大多数使用的人就有相关的意义,可以带着这个问题来问几个问题
内存的使用也未占满.
多连接并不是通过内存的消耗,将PG 带入到OOM 和系统无响应的情况中, 而是随着backend变多后,内部沟通的成本太高,导致性能上的问题,所以PG的在多连接中,是需要使用PGPOOL 或者 pgbouncer 之类的缓冲池来保证系统的性能,另外还有一个问题就是为什么要有这么多的连接, 这就是一个问题.
那既然知道了PG在处理超多的连接上会有性能的问题,那如何解决这个问题对大多数使用的人就有相关的意义,可以带着这个问题来问几个问题。
1 为什么要有并发有那么多的连接, 例如一个数据库要承受3000+以上的连接数,即使是互联网属性,整体的架构设计是什么,如果并发的连接很多的情况下,数据库本身可能已经分库分表,或者已经通过业务继续细分,将访问分散了。所以过多的同一时间的访问,这本身就是一个问题
2 对于数据库的访问,即使不使用PGbouncer 或者pgpool 程序本身也有连接池,对于连接的设计,在整体的程序设计之初就应该有考虑,而不是最后让数据库承接这一切
3 对于任何的数据库连接,都不是百分之百在同一时刻达到最大的处理数,及时是MYSQL 3000 MAX CONNECTIONS连接,在很细分的时间刻度上,同时访问数据库的基本也就是几十个。PG 的连接状态分为
1 active
2 idle
3 idle in transacton
4 aborted
这里PGbouncer 和PGPOOL 到底在帮助PG connections 做了什么
1 和 3,4 不是我们要关心的,而是idle 这个状态,这也是大部分浪费连接数的关键位置,因为程序的连接池要维护一个连接数据库的状态,这也就导致有些时刻PG 大部分的连接的状态在idle,所以要更高的利用 连接,让数据库使用有限的连接,接入更多的要工作的连接就是解决,少连接和应用要多连接的矛盾,所谓的连接复用。。
2 另外如果你经常发现你的连接状态在 idle in transaction 这也就说明经常有大事务长时间在等待什么,这也是解决问题的一个点,为什么一个事务要长时间霸占连接,并等待
另外还有一些连接,只连接不清理不关闭,可能是程序设计有失误,这样的情况我们可以设置对某个数据库的连接的 statement_timeout ,在多长时间不工作我们就关掉这个连接。(设置60秒)
alter database 数据库名 set statement_timeout = 60000;
这里最后总结一下
1 每个数据库有自己的特性,这和数据库设计的之初,架构思路有关
2 数据库的特性不是很好修改的,例如到目前MYSQL 也还是比较适合做OLTP,也没有人让他去做OLAP的操作一样, 过度将一个数据库神话,样样都行这不现实。
3 掌握某个数据库的特点,并展开,让本身的缺点弱化,这才是一个 DB 人员应该做的。

本文分享自微信公众号 - AustinDatabases(AustinDatabases)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。