
前言
GitOps 的概念最初来源于 Weaveworks 的联合创始人 Alexis 在 2017 年 8 月发表的一篇博客 GitOps - Operations by Pull Request。文章介绍了 Weaveworks 的工程师如何以 Git 作为事实的唯一真实来源,部署、管理和监控基于 Kubernetes 的 SaaS 应用。
随后,Weaveworks 在其网站上发表了一系列介绍 GitOps 应用案例和最佳实践的文章,对 GitOps 进行推广。同时,市场上也出现了一批拥抱 GitOps 模式的工具和产品,如 Jenkins X、Argo CD、Weave Flux 等。而 KubeCon EU 2019 中关于 GitOps 的讨论 GitOps and Best Practices for Cloud Native CICD,则让 GitOps 进入到了更多人的视野当中。
本文将以上述资料为基础,重点介绍如下内容:
- 什么是 GitOps?
- 推模式和拉模式
- GitOps 的主要优势
- GitOps 关键工具
什么是 GitOps?
GitOps 是一种快速、安全的方法,可供开发或运维人员维护和更新运行在 Kubernetes 或其他声明式编排框架中的复杂应用。
GitOps 四项原则
以声明的方式描述整个系统
借助 Kubernetes、Terraform 等工具,我们只需要声明系统想要达到的目标状态,工具会驱动系统向目标状态逼近。声明意味着系统状态由一组事实而不是一组指令保证,方便进行维护。当我们将声明信息存储在 Git 中后,系统状态便具备了唯一的事实来源。这样,我们可以轻松地部署和回滚应用。更重要的是,当灾难发生时,群集的基础架构也能够可靠且快速地再现。
系统的目标状态通过 Git 进行版本控制
通过将系统的目标状态存储在具有版本控制功能的系统中,并作为唯一的事实来源,我们能够从中派生和驱动一切。
- 通过 pull request 发起对目标状态的变更申请,状态变化清晰呈现,变更 review 简单明了。
- 系统的每一次变更都对应着一条 git commit,变更行为可审计。
- 回滚操作只需要使用
git revert命令把目标状态恢复到前一个状态。
对目标状态的变更批准后将自动应用到系统
一旦将声明的状态保存在 Git 中,下一步就是允许对该状态的任何变更都能自动地应用于系统,这样可以极大地提升产品交付速度。更重要的是,GitOps 采用拉模式更新系统状态,将做什么和怎么做分开,这样能够更加有效地划分出系统的安全边界。
驱动收敛 & 上报偏离
GitOps 中包含一个操作的反馈和控制循环。它将持续地比较系统的实际状态和 Git 中的目标状态,如果在预期时间内状态仍未收敛,便会触发告警并上报差异。同时,该循环让系统具备了自愈能力。自愈不仅仅意味着节点或 pod 失败, 这些由 Kubernetes 处理,在更广泛的角度,它能修正一些非预期的操作造成的系统状态偏离。下图展示了 GitOps 按控制论思想构建的闭环控制系统。
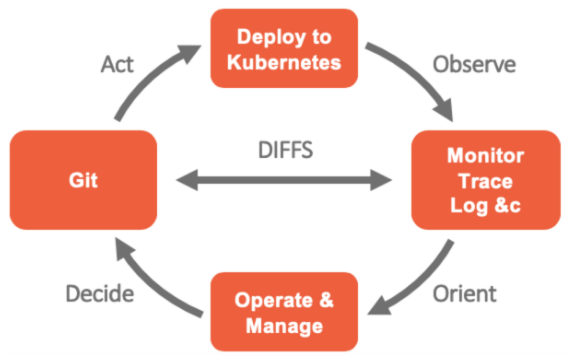
GitOps 的简洁定义
进一步,可以将 GitOps 总结成以下两点:
- An operating model for Kubernetes and other cloud native technologies, providing a set of best practices that unify deployment, management and monitoring for containerized clusters and applications.
- A path towards a developer experience for managing applications; where end-to-end CICD pipelines and git workflows are applied to both operations, and development.
推模式和拉模式
本章将介绍交付流水线中的推模式和拉模式,并解释为何 GitOps 选用拉模式来构建流水线。
CI/CD 流水线
目前大多数 CI/CD 工具都基于推模式建交付流水线。代码被合并到主分支后会触发 CI 系统进行构建和一系列的测试,并将新生成的镜像推送至镜像仓库,最后再通过kubectl set image、helm upgrade、ksonnet apply等方式将新版本直接应用到系统,整个流程如下图所示。
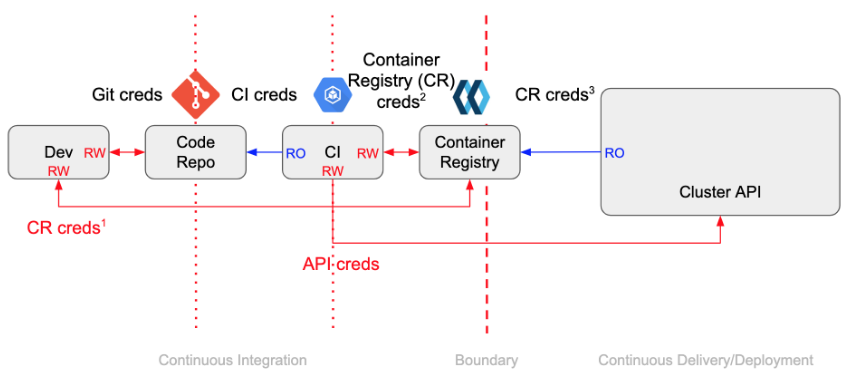
虽然这样的方式自动化程度很高,但对它进行审视后会发现如下问题:
- 跨越安全边界共享秘钥 - 在推模式下,为了让 CI 系统能够自动地部署应用,需要将集群的访问秘钥共享给它。虽然可以通过一些措施进行防护,但毕竟还是将秘钥暴露在了可信度较低的安全上下文中。这种做法扩大了攻击面,会给系统带来潜在的安全风险。
- 回滚操作复杂 - 如果通过 CI 任务完成一次部署后,系统出现异常,你将如何知道应该回滚到哪一个版本?你可能需要仔细查看构建日志才能找到答案。
- 难以快速重建集群 - 在集群完全崩溃的情况下进行重建,如何确定需要部署的每个应用的版本?你可能需要重新跑一遍 CI 任务。
GitOps 流水线
GitOps 基于拉模式构建交付流水线。此时,开发人员发布一个新功能的流程如下:
- 通过 pull request 向主分支提交包含新功能的代码。
- 代码审核通过后将被合并至主分支。
- 合并行为将触发 CI 系统进行构建和一系列的测试,并将新生成的镜像推送至镜像仓库。
- GitOps 检测到有新的镜像,会提取最新的镜像标记,然后同步到 Git 配置仓库的清单中。
- GitOps 检测到集群状态过期,会从配置仓库中拉取更新后的清单,并将包含新功能的镜像部署到集群里。
通过为不同的集群创建各自的子目录或分支,可以轻松地将该模式拓展到多集群环境。
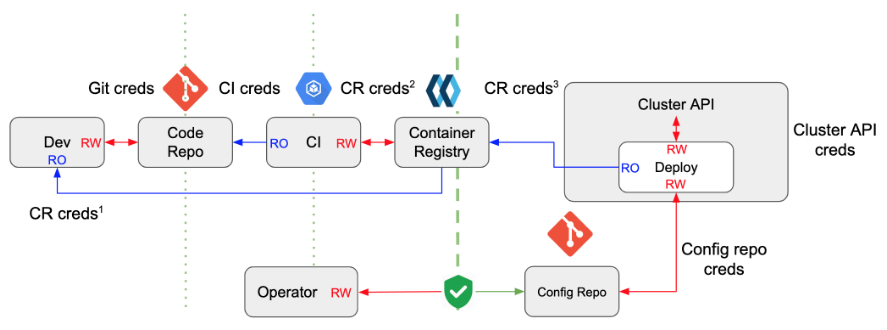
接下来让我们看看 GitOps 流水线如何解决推式流水线中存在的那些问题。
- 部署在集群内部的 GitOps 模块负责更新集群,这样就避免了集群 API 和秘钥的跨边界暴露。更重要的是,流水线中每个逻辑单元的写操作都被限定在了安全边界以内,职责划分清晰。
- 由于每一次变更都对应着一条 git commit,回滚操作只需要简单的把目标状态恢复到前一个状态。
- 由于在 Git 的配置仓库中保留了集群的目标状态,如果集群完全崩溃,可以基于仓库中的清单快速重建集群。
GitOps 的主要优势
经过上面两章的介绍,可以将 GitOps 的优势总结如下:
- 提高生产力 - 采用集成了反馈控制循环的持续部署流水线可以大大提升新功能的发布速度。
- 提升开发者体验 - 开发者可以使用熟悉的工具 Git 去发布新功能,而无需了解复杂的部署交付流程。新入职的员工可以在几天内快速上手,从而提高工作效率。
- 行为可审计 - 使用 Git 工作流管理集群,天然能够获得所有变更的审计日志,满足合规性需求,提升系统的安全与稳定性。
- 更高的可靠性 - 借助 Git 的还原(revert)、分叉(fork)功能,可以实现稳定且可重现的回滚。由于整个系统的描述都存放在 Git 中,我们有了唯一的真实来源,这能大大缩短集群完全崩溃后的恢复时间。
- 一致性和标准化 - 由于 GitOps 为基础设置、应用程序、Kubernetes 插件的部署变更提供了统一的模型,因此我们可以在整个组织中实现一致的端到端工作流。不仅仅是 CI/CD 流水线由 pull request 驱动,运维任务也可以通过 Git 完全重现。
- 更强的安全保证 - 得益于 Git 内置的安全特性,保障了存放在 Git 中的集群目标状态声明的安全性。
GitOps 关键工具
GitOps 的概念来源于 Weaveworks,但它并没有和特定的公司或工具绑定。下面列出了一些实现 GitOps 模式可选用的工具。
Infrastructure as Code & Configuration as Code
版本控制工具
状态比较工具
交付流水线
总结
Flickr 的工程师 John Allspaw 和 Paul Hammond 在 Velocity Conf 2009 上发表的演讲 10+ Deploys Per Day: Dev and Ops Cooperation at Flickr 开启了 DevOps 时代的序幕。它是人们追求以更高的频率发布高质量的软件的必然产物。
进入云原生时代后,产品的基础设施、系统架构和运维方式都发生了很大变化。为此,GitOps 对 DevOps 理念进行了扩展,它吸收了 DevOps 文化中协作、试验、快速反馈、持续改进等思想,并以 Git 作为事实的来源和链接的桥梁,旨在简化云原生时代基础设施和应用程序的部署与管理方式,实现产品更快、更频繁、更稳定的交付。
原文链接
本文为云栖社区原创内容,未经允许不得转载。









