
体验平台简介
阿里云开发者实验室提供免费云资源和丰富的场景化实践,旨在帮助开发者在学习应用技术,了解阿里云产品的特性。
阿里云体验实验室地址:https://developer.aliyun.com/adc/labs/
教程介绍
本文将介绍如何使用Linux系统中的文本编辑工具Vim以及文本处理命令。
场景体验
场景内容选自 阿里云体验实验室
本场景将提供一台配置了Aliyun Linux 2的ECS实例(云服务器)。您可以参考本教程学习Linux系统中的文本编辑工具Vim以及文本处理命令。
阿里云 Aliyun Linux 2的ECS实例资源: https://developer.aliyun.com/adc/scenario/aced2264751f4866a8340de4cf9db0fa
涉及以下云产品和服务
[云服务器ECS] 云服务器(Elastic Compute Service,简称ECS)是阿里云提供的性能卓越、稳定可靠、弹性扩展的IaaS(Infrastructure as a Service)级别云计算服务。云服务器ECS免去了您采购IT硬件的前期准备,让您像使用水、电、天然气等公共资源一样便捷、高效地使用服务器,实现计算资源的即开即用和弹性伸缩。阿里云ECS持续提供创新型服务器,解决多种业务需求,助力您的业务发展。
[Aliyun Linux 2] Aliyun Linux 2是阿里云推出的下一代 Linux 发行版,它为云上应用程序环境提供 Linux 社区的最新增强功能,在提供云上最佳用户体验的同时,也针对阿里云基础设施做了深度的优化。Aliyun Linux 2 OS 镜像可以运行在阿里云全规格系列 VM 实例上,包括弹性裸金属服务器 (神龙)。
[Vim] Vim是从vi发展出来的一个文本编辑器。代码补全、编译及错误跳转等方便编程的功能特别丰富,在程序员中被广泛使用,和Emacs并列成为类Unix系统用户最喜欢的文本编辑器。Vim的设计理念是命令的组合。用户学习了各种各样的文本间移动、跳转的命令和其他的普通模式的编辑命令,并且能够灵活组合使用的话,能够比那些没有模式的编辑器更加高效的进行文本编辑。同时Vim与很多快捷键设置和正则表达式类似,可以辅助记忆。并且Vim针对程序员做了优化。
目录一:文本编辑工具Vim
文本编辑工具Vim
vim的三种操作模式 vim有三种操作模式,分别是命令模式(Command mode)、输入模式(Insert mode)和底线命令模式(Last line mode)。
三种模式切换快捷键:
模式
快捷键
命令模式
ESC
输入模式
i或a
底线命令模式
:
命令模式 在命令模式中控制光标移动和输入命令,可对文本进行复制、粘贴、删除和查找等工作。
使用命令vim filename后进入编辑器视图后,默认模式就是命令模式,此时敲击键盘字母会被识别为一个命令,例如在键盘上连续敲击两次d,就会删除光标所在行。
以下是在命令模式中常用的快捷操作:
操作
快捷键
光标左移
h
光标右移
l(小写L)
光标上移
k
光标下移
j
光标移动到下一个单词
w
光标移动到上一个单词
b
移动游标到第n行
nG
移动游标到第一行
gg
移动游标到最后一行
G
快速回到上一次光标所在位置
Ctrl+o
删除当前字符
x
删除前一个字符
X
删除整行
dd
删除一个单词
dw或daw
删除至行尾
d$或D
删除至行首
d^
删除到文档末尾
dG
删除至文档首部
d1G
删除n行
ndd
删除n个连续字符
nx
将光标所在位置字母变成大写或小写
~
复制游标所在的整行
yy(3yy表示复制3行)
粘贴至光标后(下)
p
粘贴至光标前(上)
P
剪切
dd
交换上下行
ddp
替换整行,即删除游标所在行并进入插入模式
cc
撤销一次或n次操作
u{n}
撤销当前行的所有修改
U
恢复撤销操作
Ctrl+r
整行将向右缩进
>>
整行将向左退回
<<
若档案没有更动,则不储存离开,若档案已经被更动过,则储存后离开
ZZ
输入模式 在命令模式下按i或a键就进入了输入模式,在输入模式下,您可以正常的使用键盘按键对文本进行插入和删除等操作。
底线命令模式 在命令模式下按:键就进入了底线命令模式,在底线命令模式中可以输入单个或多个字符的命令。
以下是底线命令模式中常用的快捷操作:
操作
命令
保存
:w
退出
:q
保存并退出
:wq(:wq!表示强制保存退出)
将文件另存为其他文件名
:w new_filename
显示行号
:set nu
取消行号
:set nonu
使本行内容居中
:ce
使本行文本靠右
:ri
使本行内容靠左
:le
向光标之下寻找一个名称为word的字符串
:/word
向光标之上寻找一个字符串名称为word的字符串
:?word
重复前一个搜寻的动作
:n
从第一行到最后一行寻找word1字符串,并将该字符串取代为word2
:1,$s/word1/word2/g或 :%s/word1/word2/g
使用示例
1.List item
新建一个文件并进入vim命令模式。
vim 静夜思.txt

2.按下i进入输入模式,输入《静夜思》的诗名。
3.按下ECS键回到命令模式,并输入底线命令:ce,使诗名居中。 
4.按下o键换行并进入输入模式,输入第一行诗。 
5.按下ECS键回到命令模式,并输入底线命令:ce,使第一行诗居中。 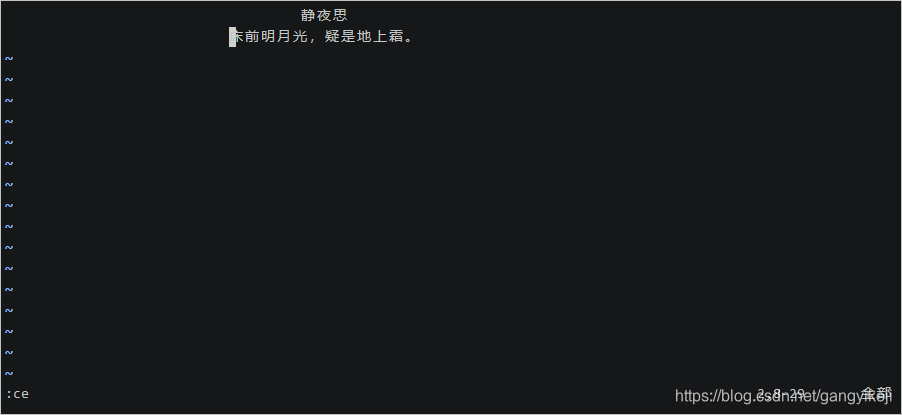
6.按下o键换行并进入输入模式,输入第二行诗。 
7.按下ECS键回到命令模式,并输入底线命令:ce,使第二行诗居中。 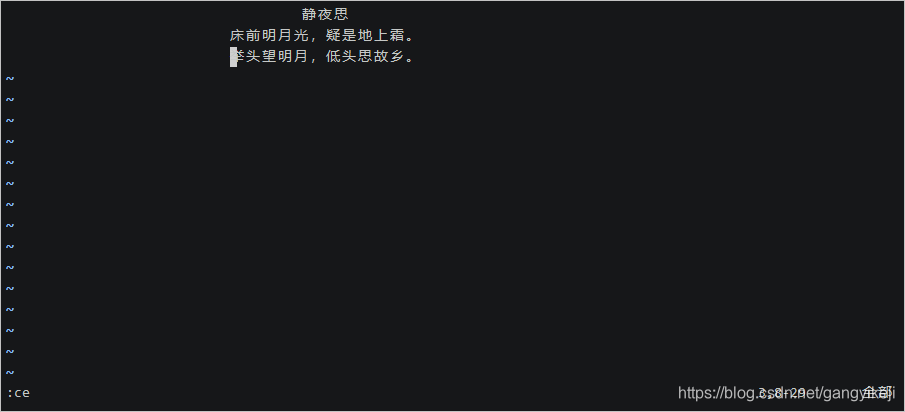
8.在命令模式中执行底线命令:wq离开vim。
目录二:文本文件查看命令
cat
命令描述:cat命令用于查看内容较少的纯文本文件。
命令格式:cat [选项] [文件]。
命令参数说明:
参数
说明
-n或--number
显示行号
-b或--number-nonblank
显示行号,但是不对空白行进行编号
-s或--squeeze-blank
当遇到有连续两行以上的空白行,只显示一行的空白行
命令使用示例:
1.将一个自增序列写入test.txt文件中。
for i in $(seq 1 10); do echo $i >> test.txt ; done
2.查看文件内容。
cat test.txt
命令输出结果: 
3.将文件内容清空。
cat /dev/null > test.txt
再次检查文件内容。
cat test.txt
命令输出结果: 
more
命令描述:more命令从前向后分页显示文件内容。
常用操作命令:
操作
作用
Enter
向下n行,n需要定义,默认为1行
Ctrl+F或空格键(Space)
向下滚动一页
Ctrl+B
向上滚动一页
=
输出当前行的行号
!命令
调用Shell执行命令
q
退出more
命令使用示例:
从第20行开始分页查看系统日志文件/var/log/messages。
more +20 /var/log/messages
命令输出结果: 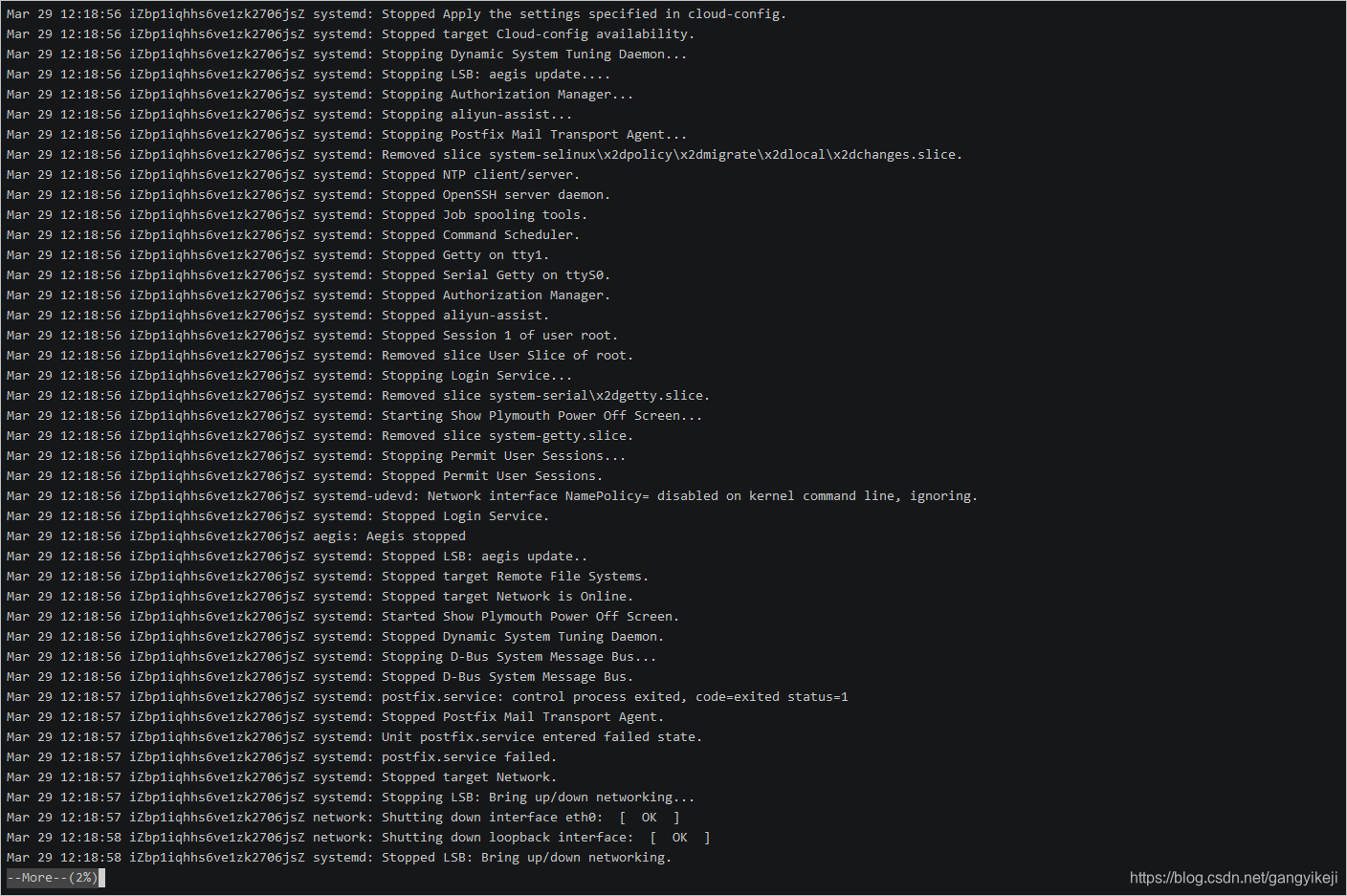
less
命令描述:less命令可以对文件或其它输出进行分页显示,与moe命令相似,但使用 less 可以随意浏览文件,而 more 仅能向前移动,却不能向后移动。
命令格式:less [参数] 文件 。
命令参数说明:
参数
说明
-e
当文件显示结束后,自动离开
-m
显示类似more命令的百分比
-N
显示每行的行号
-s
显示连续空行为一行
命令常用操作:
快捷键
说明
/字符串
向下搜索字符串
?字符串
向上搜索字符串
n
重复前一个搜索
N
反向重复前一个搜索
b或pageup键
向上翻一页
空格键或pagedown键
向下翻一页
u
向前翻半页
d
向后翻半页
y
向前滚动一行
回车键
向后滚动一行
q
退出less命令
命令使用示例:
查看命令历史使用记录并通过less分页显示。
history | less
head
命令描述:head命令用于查看文件开头指定行数的内容。
命令格式:head [参数] [文件]。
命令参数说明: | 参数 | 说明 | |--|--| |-n [行数] | 显示开头指定行的文件内容,默认为10 | | -c [字符数] |显示开头指定个数的字符数 | -q | 不显示文件名字信息,适用于多个文件,多文件时默认会显示文件名 |
命令使用示例:
查看/etc/passwd文件的前5行内容。
head -5 /etc/passwd
命令输出结果: 
tail 命令描述:tail命令用于查看文档的后N行或持续刷新内容。
命令格式:tail [参数] [文件]。
命令参数说明:
参数
说明
-f
显示文件最新追加的内容
-q
当有多个文件参数时,不输出各个文件名
-v
当有多个文件参数时,总是输出各个文件名
-c [字节数]
显示文件的尾部n个字节内容
-n [行数]
显示文件的尾部n行内容
命令使用示例:
查看/var/log/messages系统日志文件的最新10行,并保持实时刷新。
tail -f -n 10 /var/log/messages

按ctrl+c键退出文本实时查看界面。
stat
命令描述:用来显示文件的详细信息,包括inode、atime、mtime、ctime等。
命令使用示例:
查看/etc/passwd文件的详细信息。
stat /etc/passwd
命令输出结果: 
wc
命令描述:wc命令用于统计指定文本的行数、字数、字节数。
命令格式:wc [参数] [文件]。
命令参数说明:
参数
说明
-l
只显示行数
-w
只显示单词数
-c
只显示字节数
命令使用示例:
统计/etc/passwd文件的行数。
wc -l /etc/passwd
命令输出结果: 
file
命令描述: file命令用于辨识文件类型。
命令格式:file [参数] [文件]。
命令参数说明:
参数
说明
-b
列出辨识结果时,不显示文件名称
-c
详细显示指令执行过程,便于排错或分析程序执行的情形
-f [文件]
指定名称文件,其内容有一个或多个文件名称时,让file依序辨识这些文件,格式为每列一个文件名称
-L
直接显示符号连接所指向的文件类别
命令使用示例:
查看/var/log/messages文件的文件类型。
file /var/log/messages
命令输出结果: 
diff
命令描述:diff命令用于比较文件的差异。
命令使用示例:
1.构造两个相似的文件
echo -e '第一行\n第二行\n我是log1第3行\n第四行\n第五行\n第六行' > 1.log
echo -e '第一行\n第二行\n我是log2第3行\n第四行' > 2.log
2.分别查看两个文件 
3.使用diff查看两个文件的差异 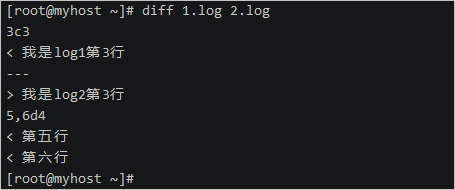
对比结果中的3c3表示两个文件在第3行有不同,5,6d4表示2.log文件相比1.log文件在第4行处开始少了1.log文件的第5和第6行。
文本文件处理命令
grep
命令描述:grep命令用于查找文件里符合条件的字符串。
grep全称是Global Regular Expression Print,表示全局正则表达式版本,它能使用正则表达式搜索文本,并把匹配的行打印出来。
在Shell脚本中,grep通过返回一个状态值来表示搜索的状态:
0:匹配成功。 1:匹配失败。 2:搜索的文件不存在。 命令格式:grep [参数] [正则表达式] [文件]。
命令常用参数说明:
参数
说明
-c或--count
计算符合样式的列数
-d recurse或-r
指定要查找的是目录而非文件
-e [范本样式]
指定字符串做为查找文件内容的样式
-E 或 --extended-regexp
将样式为延伸的正则表达式来使用
-G 或 --basic-regexp
将样式视为普通的表示法来使用
-i 或 --ignore-case
忽略字符大小写的差别
-n 或 --line-number
在显示符合样式的那一行之前,标示出该行的列数编号
-v 或 --revert-match
显示不包含匹配文本的所有行
命令使用示例:
查看sshd服务配置文件中监听端口配置所在行编号。
grep -n Port /etc/ssh/ssh_config
命令输出结果: 
查询字符串在文本中出现的行数。
grep -c localhost /etc/hosts
命令输出结果: 
反向查找,不显示符合条件的行。
ps -ef | grep sshd
ps -ef | grep -v grep | grep sshd
命令输出结果:

以递归的方式查找目录下含有关键字的文件。
grep -r *.sh /etc
命令输出结果:
使用正则表达式匹配httpd配置文件中异常状态码响应的相关配置。 grep 'ntp[0-9].aliyun.com' /etc/ntp.conf 命令输出结果: 
sed
命令描述:sed是一种流编辑器,它是文本处理中非常中的工具,能够完美的配合正则表达式使用。
- 处理时,把当前处理的行存储在临时缓冲区中,称为模式空间(pattern space)。
- 接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。
- 接着处理下一行,这样不断重复,直到文件末尾。
注意:
sed命令不会修改原文件,例如删除命令只表示某些行不打印输出,而不是从原文件中删去。 如果要改变源文件,需要使用-i选项。 命令格式:sed [参数] [动作] [文件]。
参数说明:
参数
说明
-e [script]
执行多个script
-f [script文件]
执行指定script文件
-n
仅显示script处理后的结果
-i
输出到原文件,静默执行(修改原文件)
动作说明:
动作
说明
a
在行后面增加内容
c
替换行
d
删除行
i
在行前面插入
p
打印相关的行
s
替换内容
命令使用示例:
删除第3行到最后一行内容。
sed '3,$d' /etc/passwd
命令输出结果: 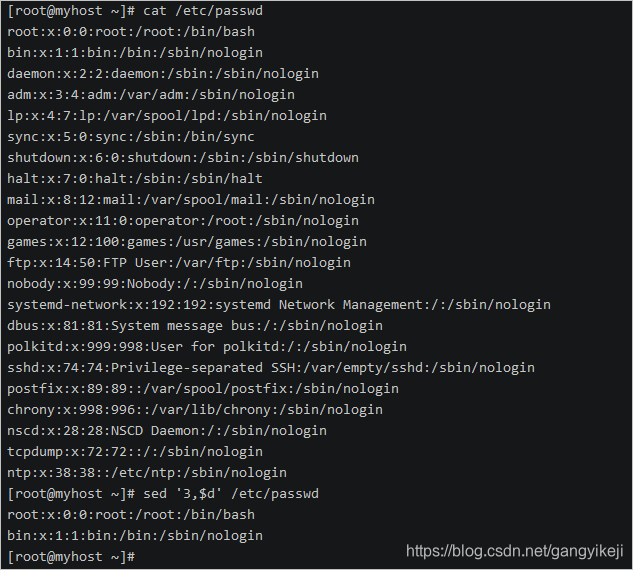
在最后一行新增行。
sed '$a admin:x:1000:1000:admin:/home/admin:/bin/bash' /etc/passwd
命令输出结果: 
替换内容。
sed 's/SELINUX=disabled/SELINUX=enforcing/' /etc/selinux/config
命令输出结果: 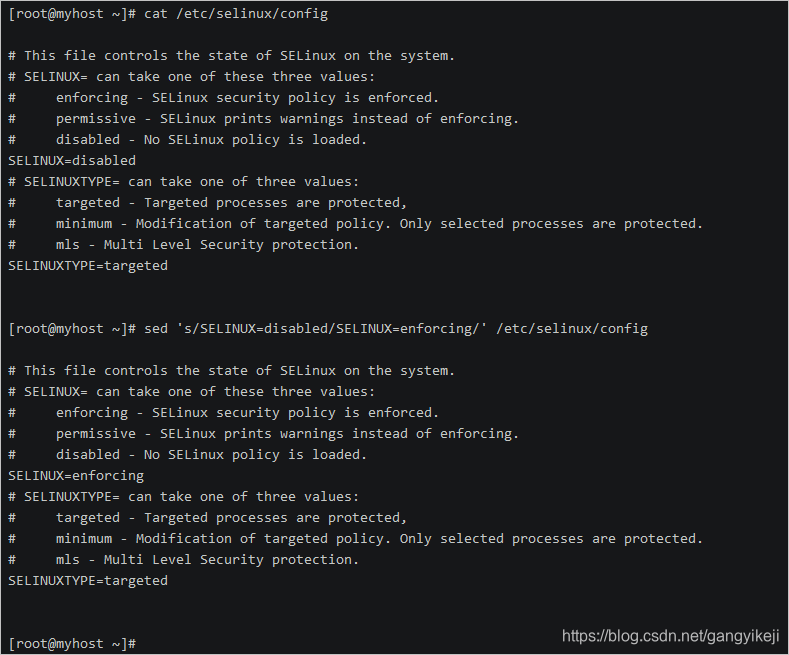
替换行。
sed '1c abcdefg' /etc/passwd
命令输出结果: 
awk
命令描述:和 sed 命令类似,awk 命令也是逐行扫描文件(从第 1 行到最后一行),寻找含有目标文本的行,如果匹配成功,则会在该行上执行用户想要的操作;反之,则不对行做任何处理。
命令格式:awk [参数] [脚本] [文件]。
参数说明:
参数
说明
-F fs
指定以fs作为输入行的分隔符,awk 命令默认分隔符为空格或制表符
-f file
读取awk脚本
-v val=val
在执行处理过程之前,设置一个变量var,并给其设置初始值为val
内置变量:
变量
用途
FS
字段分隔符
$n
指定分隔的第n个字段,如$1、$3分别表示第1、第三列
$0
当前读入的整行文本内容
NF
记录当前处理行的字段个数(列数)
NR
记录当前已读入的行数
FNR
当前行在源文件中的行号
awk中还可以指定脚本命令的运行时机。默认情况下,awk会从输入中读取一行文本,然后针对该行的数据执行程序脚本,但有时可能需要在处理数据前运行一些脚本命令,这就需要使用BEGIN关键字,BEGIN会在awsk读取数据前强制执行该关键字后指定的脚本命令。
和BEGIN关键字相对应,END关键字允许我们指定一些脚本命令,awk会在读完数据后执行它们。
命令使用示例:
查看本机IP地址。
ifconfig eth0 |awk '/inet/{print $2}'
命令输出结果: 
查看本机剩余磁盘容量。
df -h |awk '/\/$/{print $4}'
命令输出结果: 
统计系统用户个数。
awk -F: '$3<1000{x++} END{print x}' /etc/passwd
命令输出结果: 
输出其中登录Shell不以nologin结尾(对第7个字段做!~反向匹配)的用户名、登录Shell信息。
awk -F: '$7!~/nologin$/{print $1,$7}' /etc/passwd
命令输出结果: 
输出/etc/passwd文件中前三行记录的用户名和用户uid。
head -3 /etc/passwd | awk 'BEGIN{FS=":";print "name\tuid"}{print $1,"\t"$3}END{print "sum lines "NR}'
命令输出结果: 
查看tcp连接数。
netstat -na | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
命令输出结果: 
关闭指定服务的所有的进程。
ps -ef | grep httpd | awk {'print $2'} | xargs kill -9
cut
命令描述:cut命令主要用来切割字符串,可以对输入的数据进行切割然后输出。
命令格式:cut [参数] [文件]。
参数说明:
参数
说明
-b
以字节为单位进行分割
-c
以字符为单位进行分割
-d
自定义分隔符,默认为制表符
命令使用示例:
按字节进行切割。 
按字符进行切割。 
按指定字符进行切割。 
tr
命令描述:tr命令用于对来自标准输入的字符进行替换、压缩和删除。
命令格式:tr [参数] [文本]。
参数说明:
参数
说明
-c
反选指定字符
-d
删除指定字符
-s
将重复的字符缩减成一个字符
-t [第一字符集] [第二字符集]
删除第一字符集较第二字符集多出的字符,使两个字符集长度相等
命令使用示例:
将输入字符由大写转换为小写。
echo "HELLO WORLD" | tr 'A-Z' 'a-z'
命令输出结果: 
删除字符。
echo "hello 123 world 456" | tr -d '0-9'
命令输出结果: 
压缩字符。
echo "thissss is a text linnnnnnne." | tr -s ' sn'
命令输出结果: 
产生随机密码。
cat /dev/urandom | tr -dc a-zA-Z0-9 | head -c 13
命令输出结果: 
体验实验室地址场景地址:https://developer.aliyun.com/adc/scenario/aced2264751f4866a8340de4cf9db0fa 体验实验室中可以使用体验资源直接上手操作











