大家好,我是阿沐,一个喜欢分享技术而且爱好写散文的程序员。
今天来给大家介绍一下info命令查看redis具体的详细信息讲解!
起因是:前几年我在老家郑州实习面试(那个时候还没有毕业)的时候遇到面试官提问;面试官来于百度总部的工程师6年java开发经验+3年多的PHP开发经验,我在他的面前基本就是弟弟中的弟弟,虽然勉强通过入职了,但是却被运维无情地嘲笑,就因为组长让我上机看下redis的基础情况,我不会,问了运维。一怒之下,我当天晚上就恶补了一波......,到现在都还记着
不过,讲真,那个时候真的是没有详细的去看过redis的参数信息;你们有在 Redis 官网上好好的看过参数配置吗?
哈哈~,大家不用这么谦虚哈。估计刚刚毕业或者实习中,甚至毕业一两年的开发者都没有好好地去看过(我就是其中一个,当时只会基础的使用)。突然觉得会用跟知道其实就是两码事情;
经常能听到别的同事或者网络留言,会用就行,知道那么多干嘛。ctrl+c and ctrl+v这才是程序员编码的最高境界。是不是大家都是这么想的呢?😂 😂 😂
有句话叫做:知其原理,方可百变「我胡诌地,莫当真」。那么今天我们通过info指令清晰的理解 Redis 内部一系列运行参数。
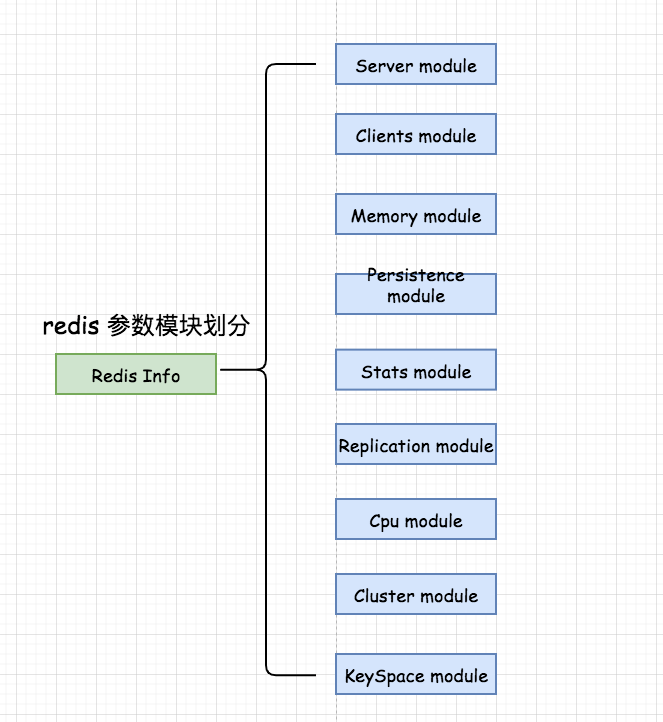
01)详解模块
从上图可以清晰的看出来我们将redis的参数划分为9大模块,每一个模块对应的意思:
- Server module:主要是指redis服务器
环境参数;例如:系统版本号、服务器版本号等等。 - Clients module:主要是指
客户端相关信息;例如:客户端连接数、阻塞等待数、buffer的值等等。 - Memory module:主要是指服务器
内存消耗信息;例如:占用内存大小、redis峰值数据。 - Persistence module:主要是指redis的
持久化信息;例如:最近一次rdb持久化是否成功、服务器是否正在载入持久化文件等等。 - Stats module:主要是指
用来统计通用的数据;例如:1/s并发数、1/min数据量、命中数量等等。 - Replication module:主要是指
主从同步信息说明;同步成功次数、同步失败次数等等。 - Cpu module:主要是指
cpu统计信息;例如:核心态/用户态所占用的CPU时求和累计值等等。 - Cluster module:主要是指
集群的相关信息;例如:是否启用集群模式等等。 - KeySpace module:主要是指
键值对统计数量信息。例如:查找键成功的数量、查找键失败的次数等等。
02)为什么要了解?
如果你已经是一个大神,那么完全可以不用了解了。但是对于刚刚进入职场或者工作一年、两年、甚至三年的开发并不一定了解知道这些相关知识。
现在大多公司已经配置了专业的运维、DBA,环境搭建、redis集群、主从架构全部都被他们做了,难道我们开发就不需要学习了吗?
面试过很多开发都曾经这样回答过:“公司都有专业的运维团队,很多我们不能参与,所以没有实战之地。只能从事业务需求开发”。这样很显然我们的技术迭代肯定上不去,一个开发不仅仅只会做业务需求、更重要的是懂得知识的积累:mysql主主、主从;redis多主多从部署;docker、k8s等等,即使不是我们部署的,但是我们也要知道是怎么一回事,公司的架构是怎么样,怎么实现的,怎个流程规范?
这就是为什么要去了解这些的原因,尽管看上去这是一篇很基础且简单的文章。估计不少人会在喷,但是阿沐的面对的对象群体是需要巩固和加强redis知识的学者。
03)内部信息详解
➜ ~ redis-cli -h localhost
localhost:6379> info
# Server
redis_version:5.0.9 -- Redis 服务器版本
redis_git_sha1:00000000 -- Git SHA1
redis_git_dirty:0 -- Git脏标志符
redis_build_id:544ec503bcbee8b6 -- 内部版本号
redis_mode:standalone -- 运行模式 单机还是集群
os:Darwin 17.7.0 x86_64 -- 服务器的宿主操作系统
arch_bits:64 -- 体系结构(32位或者64位)
multiplexing_api:kqueue -- Redis使用的事件循环机制
atomicvar_api:atomic-builtin -- 原子处理api
gcc_version:4.2.1 -- 用于编译Redis服务器的GCC编译器的版本号
process_id:411 -- 务器进程的PID
run_id:e8bf4443cdd6696036e07c4a65d64e6916a6a79e -- Redis 服务器的随机标识符(用于 Sentinel 和集群)
tcp_port:6379 -- TCP/IP 监听端口
uptime_in_seconds:29924 -- redis server启动的时间(单位秒)
uptime_in_days:0 -- redis server启动的时间(单位天)
hz:10 -- redis内部调度(进行关闭timeout的客户端,删除过期key等等)频率,程序规定serverCron每秒运行10次
configured_hz:10 -- 服务器的已配置频率设置
lru_clock:9421068 -- 自增的时钟,用于LRU管;该时钟100ms(hz=10,因此每1000ms/10=100ms执行一次定时任务)更新一次
executable:/usr/local/opt/redis/bin/redis-server -- 服务器可执行文件的路径
config_file:/usr/local/etc/redis.conf -- redis配置文件的路径
# Clients
connected_clients:1 -- 客户端已连接的数量(不包括通过从属服务器连接的客户端)
client_recent_max_input_buffer:2 -- 当前客户端最近最大输入缓存大小
client_recent_max_output_buffer:0 -- 当前客户端最近最大输出缓存大小
blocked_clients:0 -- 正在等待阻塞命令(BLPOP、BRPOP、BRPOPLPUSH)的客户端的数量
# Memory
used_memory:148180600 -- Redis分配器分配的内存总量,以字节(byte)为单位
used_memory_human:1015.52K -- 以人类可读的格式返回Redis分配的内存总量,意思就是让我们正常人能看懂呗,带有单位
used_memory_rss:3293184 -- 从操作系统的角度,返回 Redis 已分配的内存总量(俗称常驻集大小)。这个值和top、ps等命令的输出一致
used_memory_rss_human:3.14M -- 以人类可读的格式,返回 Redis 已分配的内存总量(俗称常驻集大小);这个值和top、ps等命令的输出一致
used_memory_peak:1040976 -- redis的内存消耗峰值(以字节为单位),也就是峰值时占用内存大小
used_memory_peak_human:1016.58K -- 以人类可读的格式返回redis的内存消耗峰值
used_memory_peak_perc:99.90% -- (used_memory/used_memory_peak) *100%,内存峰值占用率
used_memory_overhead:1037198 -- redis为了维护数据集的内部机制所需的内存开销,包括所有客户端输出缓冲区、查询缓冲区、AOF重写缓冲区和主从复制的backlog
used_memory_startup:987504 -- Redis在启动时消耗的初始内存量(以字节为单位)
used_memory_dataset:2690 -- 数据集的字节大小used_memory—used_memory_overhead
used_memory_dataset_perc:5.14% -- 净内存使用量的百分比(used_memory_dataset/(used_memory—used_memory_startup))*100%
total_system_memory:8589934592 -- 整个系统内存
total_system_memory_human:16.00G -- 正常人可以看懂的格式显示 系统内存大小 带单位
used_memory_lua:37888 -- Lua脚本存储占用的内存
used_memory_lua_human:37.00K -- 正常人可看懂的格式显示Lua脚本存储占用的内存 带单位
used_memory_scripts:0 -- 缓存的Lua脚本使用的字节数
used_memory_scripts_human:0B -- 正常人可看懂的格式显示 缓存的Lua脚本使用的字节数 带单位
maxmemory:0 -- Redis实例的最大内存配置 字节数
maxmemory_human:0B -- 正常人可看懂格式显示 最大内存配置 带单位
maxmemory_policy:noeviction -- 当达到maxmemory时的淘汰策略
allocator_frag_ratio:3.24
allocator_frag_bytes:2249712
allocator_rss_ratio:1.00
allocator_rss_bytes:0
rss_overhead_ratio:1.01
rss_overhead_bytes:37888
mem_fragmentation_ratio:3.27
mem_fragmentation_bytes:2287600
mem_not_counted_for_evict:0
mem_replication_backlog:0
mem_clients_slaves:0
mem_clients_normal:49694
mem_aof_buffer:0
mem_allocator:libc -- 内存分配器
active_defrag_running:0 -- 表示没有活动的defrag任务正在运行,1表示有活动的defrag任务正在运行(defrag:表示内存碎片整理)
lazyfree_pending_objects:0 -- 0表示不存在延迟释放(也有资料翻译未惰性删除)的挂起对象
# Persistence
loading:0 -- 服务器是否正在载入持久化文件
rdb_changes_since_last_save:5 -- 离最近一次成功生成rdb文件,写入命令的个数,即有多少个写入命令没有持久化
rdb_bgsave_in_progress:0 -- 服务器是否正在创建rdb文件
rdb_last_save_time:1620033801 -- 上一次成功保存RDB的基于纪元的时间戳 秒
rdb_last_bgsave_status:ok -- 最近一次rdb持久化是否成功
rdb_last_bgsave_time_sec:-1 -- 最近一次成功生成rdb文件耗时时间(以秒为单位)
rdb_current_bgsave_time_sec:-1 -- 正在进行的RDB保存操作的持续时间(以秒为单位)
rdb_last_cow_size:0 -- 上一次RDB保存操作期间写时复制内存的大小(以字节为单位)
aof_enabled:0 -- 是否开启了aof
aof_rewrite_in_progress:0 -- 标识aof的rewrite操作是否在进行中
aof_rewrite_scheduled:0 -- 如果rdb保存完成之后执行rewrite
aof_last_rewrite_time_sec:-1 -- 最近一次aof rewrite耗费的时长(以秒为单位)
aof_current_rewrite_time_sec:-1 -- 如果rewrite操作正在进行,则记录所使用的时间(以秒为单位)
aof_last_bgrewrite_status:ok -- 上次bgrewriteaof操作的状态
aof_last_write_status:ok -- 上次aof写入状态
aof_last_cow_size:0 -- 最近一次aof重写时复制内存的大小(以字节为单位)
# Stats
total_connections_received:1 -- 务器接受的连接总数(过度地创建和销毁连接对性能有影响)
total_commands_processed:3 -- redis处理的命令总数
instantaneous_ops_per_sec:0 -- redis每秒处理的命令数,就是qps
total_net_input_bytes:63 -- redis网络读取流量的总字节数
total_net_output_bytes:14765 -- redis网络写入流量的总字节数
instantaneous_input_kbps:0.00 -- redis网络入口kps,以KB/秒为单位
instantaneous_output_kbps:0.00 -- redis网络出口kps,以KB/秒为单位
rejected_connections:0 -- redis连接个数达到maxclients限制,拒绝新连接的个数
sync_full:0 -- 主从完全同步成功次数
sync_partial_ok:0 -- 主从部分同步成功次数
sync_partial_err:0 -- 主从部分同步失败次数
expired_keys:0 -- redis运行以来过期的key的数量
expired_stale_perc:0.00 -- key过期的比率
expired_time_cap_reached_count:0 -- key过期次数
evicted_keys:0 -- redis运行以来剔除(超过了maxmemory后)的key的数量
keyspace_hits:0 -- 查找键成功的数量,也就是命中的数量
keyspace_misses:0 -- 查找键失败的数量,也就是未命中的数量
pubsub_channels:0 -- redis当前使用中的频道数量
pubsub_patterns:0 -- 当前使用的模式的数量
latest_fork_usec:0 -- 最近一次fork操作阻塞redis进程的耗时数,单位微秒
migrate_cached_sockets:0 -- 是否已经缓存了到该地址的连接
slave_expires_tracked_keys:0 -- redis从实例到期key数量
active_defrag_hits:0 -- redis主动进行碎片整理命中次数
active_defrag_misses:0 -- redis主动进行碎片整理未命中次数
active_defrag_key_hits:0 -- redis主动进行碎片整理key命中次数
active_defrag_key_misses:0 -- redis主动进行碎片整理key未命中次数
# Replication
role:master -- redis实例的角色,是master or slave
connected_slaves:0 -- 连接的从slave实例个数
master_replid:1e913ad6101de7d40fcea32378f515e62a55c9db -- master实例启动随机字符串
master_replid2:0000000000000000000000000000000000000000 -- master实例启动随机字符串2,辅助作用,用于故障转移后的同步
master_repl_offset:0 -- redis的当前主从偏移量
second_repl_offset:-1 -- redis的当前主从偏移量2
repl_backlog_active:0 -- 复制积压缓冲区是否开启
repl_backlog_size:1048576 -- 复制积压缓冲大小
repl_backlog_first_byte_offset:0 -- 复制缓冲区里偏移量的大小
repl_backlog_histlen:0 -- 复制积压缓冲区中数据的大小(以字节为单位),值等于master_repl_offset-repl_backlog_first_byte_offset
# CPU
used_cpu_sys:3.629912 -- Redis服务器消耗的系统CPU,这是服务器进程的所有线程(主线程和后台线程)消耗的系统CPU的总和
used_cpu_user:2.675796 -- Redis服务器消耗的用户CPU,这是服务器进程的所有线程(主线程和后台线程)消耗的用户CPU的总和
used_cpu_sys_children:0.000000 -- 后台进程消耗的系统CPU累计总和
used_cpu_user_children:0.000000 -- 后台进程消耗的用户CPU累计总和
# Cluster
cluster_enabled:0 -- 实例是否启用集群模式
# Keyspace
db0:keys = 749916 -- db0的key的数量
expires = 8 -- 含有生存期的key的数
avg_ttl = 138855028143523 -- 平均存活时间整理到这里真的是累死阿沐了,太多参数了,上面是整理了基本的一些参数说明。不过当你真正去整理这些数据的时候,你会发现,你本以为觉得自己知道很多;但是却有不知道的更多。
04)需要重点看的参数
查看redis内存占用情况:
原因:虽然基本大公司内部都会有看板可以直接看到redis集群的使用情况,但是有时候可能需要我们开发上机查看确定是否真的异常。
➜ ~ redis-cli -h localhost info memory | grep -E 'used|human'
used_memory:1038896
used_memory_human:1014.55K
used_memory_rss:1490944
used_memory_rss_human:1.42M
used_memory_peak:1040976
used_memory_peak_human:1016.58K
used_memory_peak_perc:99.80%
used_memory_lua:37888
used_memory_lua_human:37.00K
used_memory_scripts:0
used_memory_scripts_human:0B上面比较清晰的可以看到,当前redi从操作系统那里分配内存总量以及内存占用率(由于输出比较多,我删除一些展示需要用的几个数据)。
1、used_memory:redis分配器分配的内存总量(单位字节),同时也包含虚拟内存swap。
2、used_memory_rss:redis进程占用操作系统内存量(单位字节);包括进程本身运行内存、内存碎片。
两者区别:used_memory获取对象是redis;used_memory_rss获取对象是操作系统;从上面的结果可以看到明显前者小于后者,是因为redis运行本身需要占用内存且还有内存碎片,所以看上去前者比后者小很多。但并不意味着前者一定小于后者,可能前者会出现虚拟内存导致前者大于后者。
查看客户端连接数:
我们先枚举列出客户端相关参数配置:
➜ ~ redis-cli -h localhost info clients
# Clients
connected_clients:1
client_recent_max_input_buffer:4
client_recent_max_output_buffer:0
blocked_clients:0在查看本机的客户端最大连接数:
localhost:6379> config get maxclients
1) "maxclients"
2) "10000"为什么要将上面和下面拿出来作对比,因为客户端的连接数是受maxclients的限制,这两个参数对我们排查问题很重要。我们可能会在写代码时候遇到redis服务不可用,那么首先确定是不是redis挂掉了。
telnet 127.0.0.1(线上redis的ip地址) 80(端口)通过对链接数量的查看发现异常状态,我们可以通过client list指令查看客户端连接:
localhost:6379> client list
id=10 addr=127.0.0.1:56336 fd=8 name= age=780 idle=1 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=26 qbuf-free=32742 obl=0 oll=0 omem=0 events=r cmd=client
科普命令返回的结果集含义:
以下是域的含义:
id : 序号
addr : 客户端的地址和端口
fd : 套接字所使用的文件描述符
name : 连接名称
age : 以秒计算的已连接时长
idle : 以秒计算的空闲时长
flags : 客户端 flag
db : 该客户端正在使用的数据库ID
sub : 已订阅频道的数量
psub : 已订阅模式的数量
multi : 在事务中被执行的命令数量
qbuf : 查询缓冲区的长度(字节为单位, 0 表示没有分配查询缓冲区)
qbuf-free : 查询缓冲区剩余空间的长度(字节为单位, 0 表示没有剩余空间)
obl : 输出缓冲区的长度(字节为单位, 0 表示没有分配输出缓冲区)
oll : 输出列表包含的对象数量(当输出缓冲区没有剩余空间时,命令回复会以字符串对象的形式被入队到这个队列里)
omem : 输出缓冲区和输出列表占用的内存总量
events : 文件描述符事件
cmd : 最近一次执行的命令那么是不是很清楚就能找到潜藏的连接来源,我们也可以通过查询客户端连接被拒绝的数目,来确保服务是否需要重新优化配置:
➜ ~ redis-cli -h localhost info stats | grep reject
rejected_connections:0 -- 客户端被拒绝的连接数如果这个值出现我们理想预期,就需要调整我们的最大连接数量:
① 通过redis配置文件修改最大连接数:
vim /usr/local/etc/redis.conf
maxclients = 150000
② redis服务启动时指定最大连接数:
redis-server --maxclients 150000当然里面还有查询cpu信息、集群信息、主从复制相关信息的参数,那么我会将这些慢慢地放在下一章节里面将,带着实际的实践项目步步深入。
目前我们只需要了解这里面一些比较常关注的参数即可;讲真地,我自己现在也不一定能记起来多少,也是比较常用常看的数据指标熟悉一点。
最后总结
能看到这里的小伙伴,你们的眼力是真的给力,太多的参数需要去看去记住,真的很不容易!麻烦小伙伴们对着自己竖起大拇指,贼棒。
文章虽然比较简短,可能高手大佬们看到就会骂“垃圾,写的是个啥”;我还是那句话,我们针对的群体对象不同。而且这些不是什么空穴来风随便写的文章,而是经过大厂的面试、领导的询问才会结合自己的实际情况写出来。
不知看完文章小伙伴们对redis info的内部参数是否有进一步的了解?如果阿沐的文章感觉有帮助或者有不足之处,请在评论下面留言。
好了,我是阿沐,一个不想30岁就被淘汰的打工人 ⛽️ ⛽️ ⛽️ 。感谢各位小伙伴的:收藏、点赞、分享和留言,我们下期再见。