
前言
本文写于 2019 年,如有不对之处欢迎指出。
Babel 对于前端开发者来说应该是很熟悉了,日常开发中基本上是离不开它的。
已经 9102 年了,我们已经能够熟练地使用 es2015+ 的语法。但是对于浏览器来说,可能和它们还不够熟悉,我们得让浏览器理解它们,这就需要 Babel。
当然,仅仅是 Babel 是不够的,还需要 polyfill 等等等等,这里就先不说了。
这篇文章是一个 Babel 的入门文章,希望能够用浅显易懂的语言让不懂 Babel 的人不再恐惧。
What:什么是 Babel
Babel is a toolchain that is mainly used to convert ECMAScript 2015+ code into a backwards compatible version of JavaScript in current and older browsers or environments.
简单地说,Babel 能够转译 ECMAScript 2015+ 的代码,使它在旧的浏览器或者环境中也能够运行。
我们可以在 https://babel.docschina.org/repl 尝试一下。
一个小🌰:
`// es2015 的 const 和 arrow function
const add = (a, b) => a + b;
// Babel 转译后
var add = function add(a, b) {
return a + b;
};
`
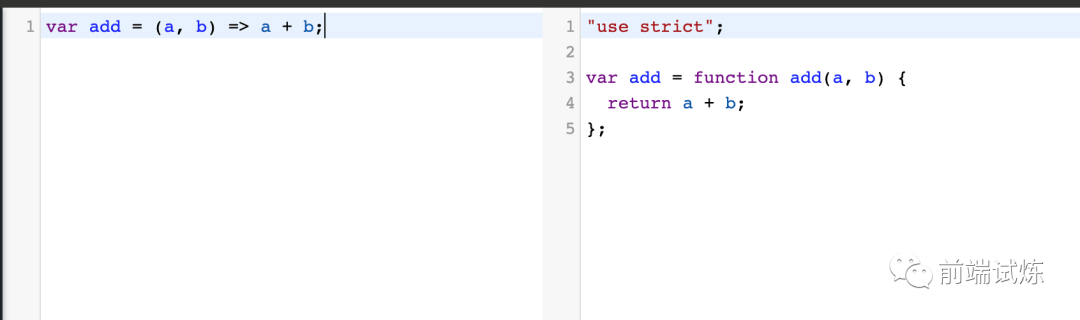
Babel 的功能很纯粹。我们传递一段源代码给 Babel,然后它返回一串新的代码给我们。就是这么简单,它不会运行我们的代码,也不会去打包我们的代码。
它只是一个编译器。
How: Babel 是如何工作的
首先得要先了解一个概念:抽象语法树(Abstract Syntax Tree, AST),Babel 本质上就是在操作 AST 来完成代码的转译。
AST
AST 是什么这里就不细说了,想要了解更多信息可以查看 Abstract syntax tree - Wikipedia。
这里比较关心的一段 JavaScript 代码会生成一个怎样的 AST,Babel 又是怎么去操作 AST 的。
我们还是拿上面的🌰来说明 const add = (a, b) => a + b;,这样一句简单的代码,我们来看看它生成的 AST 会是怎样的:
{ "type": "Program", "body": [ { "type": "VariableDeclaration", // 变量声明 "declarations": [ // 具体声明 { "type": "VariableDeclarator", // 变量声明 "id": { "type": "Identifier", // 标识符(最基础的) "name": "add" // 函数名 }, "init": { "type": "ArrowFunctionExpression", // 箭头函数 "id": null, "expression": true, "generator": false, "params": [ // 参数 { "type": "Identifier", "name": "a" }, { "type": "Identifier", "name": "b" } ], "body": { // 函数体 "type": "BinaryExpression", // 二项式 "left": { // 二项式左边 "type": "Identifier", "name": "a" }, "operator": "+", // 二项式运算符 "right": { // 二项式右边 "type": "Identifier", "name": "b" } } } } ], "kind": "const" } ], "sourceType": "module" }
我们可以通过一棵“树”来更为直观地展示这句代码的 AST(从第二层的 declarations 开始):
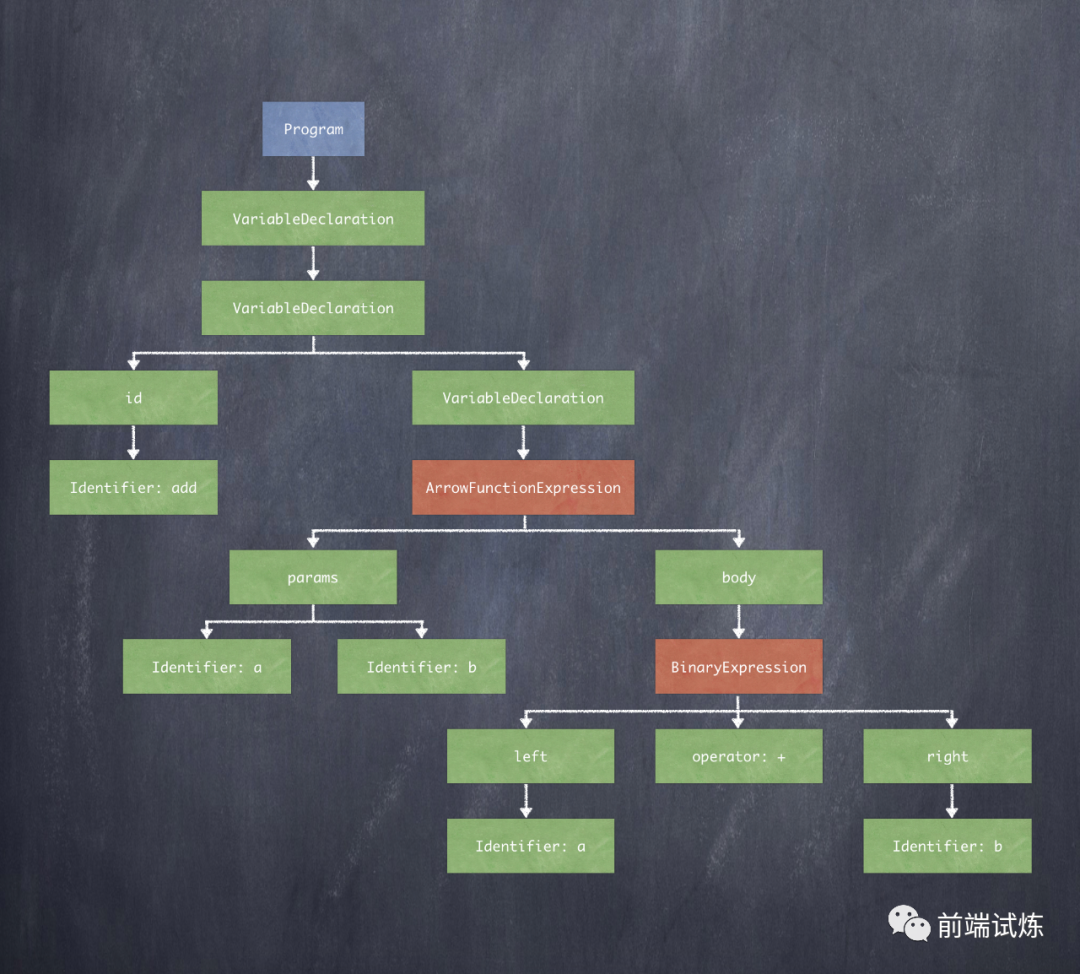
一个 AST 的根节点始终都是 Program,上面的例子我们从 declarations 开始往下读:
一个VariableDeclaration(变量声明):声明了一个 name 为 add 的ArrowFunctionExpression(箭头函数):
params(函数入参):a和b函数体:函数主体是一个
BinaryExpression(二项式),一个标准的二项式分为三部分:left(左边):aoperator(运算符):加号 +right(右边):b
这样就拆解了这一行代码。
如果想要了解更多,可以阅读和尝试:
分析
AST:https://ASTexplorer.net
Babel 工作过程
了解了 AST 是什么样的,就可以开始研究 Babel 的工作过程了。
上面说过,Babel 的功能很纯粹,它只是一个编译器。
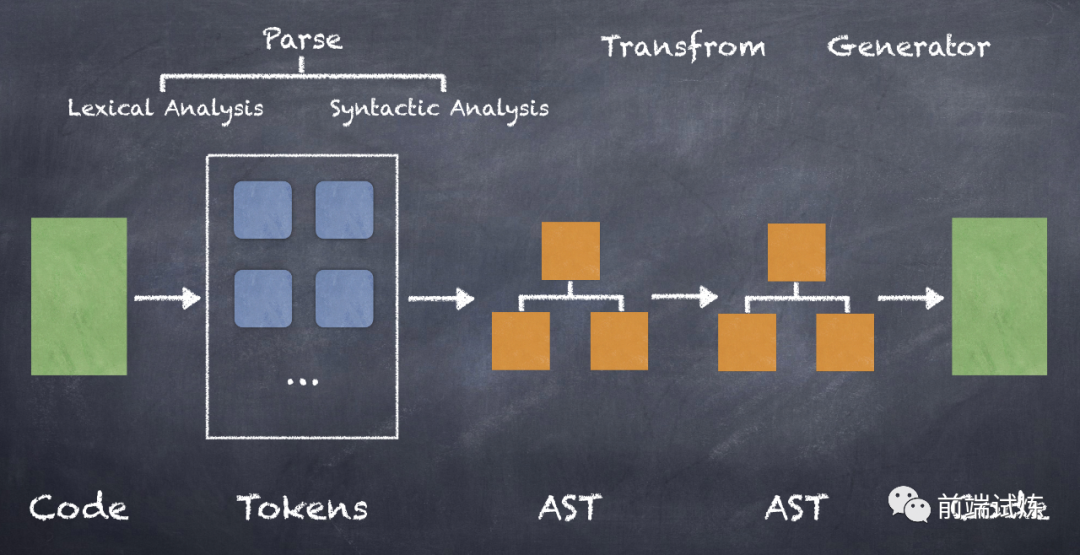
大多数编译器的工作过程可以分为三部分:
「Parse(解析)」:将源代码转换成更加抽象的表示方法(例如抽象语法树)
「Transform(转换)」:对(抽象语法树)做一些特殊处理,让它符合编译器的期望
「Generate(代码生成)」:将第二步经过转换过的(抽象语法树)生成新的代码
嗯... 既然 Babel 是一个编译器,当然它的工作过程也是这样的。我们来仔细看看这三步分别做了什么事。当然,还是拿上面的🌰来说明 const add = (a, b) => a + b,看看它是如何经过 Babel 变成:
var add = function add(a, b) { return a + b; };
Parse(解析)
一般来说,Parse 阶段可以细分为两个阶段:「词法分析」(Lexical Analysis, LA)和「语法分析」(Syntactic Analysis, SA)。
词法分析
词法分析阶段可以看成是对代码进行“分词”,它接收一段源代码,然后执行一段 tokenize 函数,把代码分割成被称为Tokens 的东西。Tokens 是一个数组,由一些代码的碎片组成,比如数字、标点符号、运算符号等等等等,例如这样:
[ { "type": "Keyword", "value": "const" }, { "type": "Identifier", "value": "add" }, { "type": "Punctuator", "value": "=" }, { "type": "Punctuator", "value": "(" }, { "type": "Identifier", "value": "a" }, { "type": "Punctuator", "value": "," }, { "type": "Identifier", "value": "b" }, { "type": "Punctuator", "value": ")" }, { "type": "Punctuator", "value": "=>" }, { "type": "Identifier", "value": "a" }, { "type": "Punctuator", "value": "+" }, { "type": "Identifier", "value": "b" } ]
通过 http://esprima.org/demo/parse.html 生成的。
看上去好像很容易啊,就是把一句完整的代码拆成一个个独立个体就好了。但是,我们得让机器知道怎么拆~
我们来试着实现一下 tokenize 函数:
`/**
- 词法分析 tokenize
- @param {string} code JavaScript 代码
- @return {Array} token
*/
function tokenize(code) {
if (!code || code.length === 0) {
return [];
}
var current = 0; // 记录位置
var tokens = []; // 定义一个空的 token 数组
var LETTERS = /[a-zA-Z\$\_]/i;
var KEYWORDS = /const/; // 模拟一下判断是不是关键字
var WHITESPACE = /\s/;
var PARENS = /\(|\)/;
var NUMBERS = /[0-9]/;
var OPERATORS = /[+*/-]/;
var PUNCTUATORS = /[~!@#$%^&*()/\|,.<>?"';:_+-=\[\]{}]/;
// 从第一个字符开始遍历
while (current < code.length) {
var char = code[current];
// 判断空格
if (WHITESPACE.test(char)) {
current++;
continue;
}
// 判断连续字符
if (LETTERS.test(char)) {
var value = '';
var type = 'Identifier';
while (char && LETTERS.test(char)) {
value += char;
char = code[++current];
}
// 判断是否是关键字
if (KEYWORDS.test(value)) {
type = 'Keyword'
}
tokens.push({
type: type,
value: value
});
continue;
}
// 判断小括号
if (PARENS.test(char)) {
tokens.push({
type: 'Paren',
value: char
});
current++;
continue;
}
// 判断连续数字
if (NUMBERS.test(char)) {
var value = '';
while (char && NUMBERS.test(char)) {
value += char;
char = code[++current];
}
tokens.push({
type: 'Number',
value: value
});
continue;
}
// 判断运算符
if (OPERATORS.test(char)) {
tokens.push({
type: 'Operator',
value: char
});
current++;
continue;
}
// 判断箭头函数
if (PUNCTUATORS.test(char)) {
var value = char;
var type = 'Punctuator';
var temp = code[++current];
if (temp === '>') {
type = 'ArrowFunction';
value += temp;
current ++;
}
tokens.push({
type: type,
value: value
});
continue;
}
tokens.push({
type: 'Identifier',
value: char
});
current++;
}
return tokens;
}
`
上面这个 tokenize 函数只是自己实现一下,与实际上 Babel 的实现方式还是差不少的,如果感兴趣可以看看https://github.com/babel/babel/blob/master/packages/babel-parser/src/tokenizer
我们来测试一下:
`const tokens = tokenize('const add = (a, b) => a + b');
console.log(tokens);
[
{ "type": "Keyword", "value": "const" },
{ "type": "Identifier", "value": "add" },
{ "type": "Punctuator", "value": "=" },
{ "type": "Paren", "value": "(" },
{ "type": "Identifier", "value": "a" },
{ "type": "Punctuator", "value": "," },
{ "type": "Identifier", "value": "b" },
{ "type": "Paren", "value": ")" },
{ "type": "ArrowFunction", "value": "=>" },
{ "type": "Identifier", "value": "a" },
{ "type": "Operator", "value": "+" },
{ "type": "Identifier", "value": "b" }
]
`
看上去和上面的有点不太一样,没关系,我只是细化了一下类别,意思就是这么个意思。
语法分析
「词法分析」之后,代码就已经变成了一个 Tokens 数组了,现在需要通过「语法分析」把 Tokens 转化为上面提到过的 AST。
说来惭愧,这里没有想到很好的思路来实现一个 parse 函数。如果哪天想到了,再补充上来。
现在我们先假设已经实现了这样一个函数,把上面的 Tokens 转化成了一个 AST,进入下一步。
如果感兴趣可以看看官方的做法https://github.com/babel/babel/tree/master/packages/babel-parser/src/parser
Transform(转换)
这一步做的事情也很简单,就是操作 AST。如果忘记了 AST 是什么,可以回到上面再看看。
我们可以看到 AST 中有很多相似的元素,它们都有一个 type 属性,这样的元素被称作「节点」。一个节点通常含有若干属性,可以用于描述 AST 的部分信息。
比如这是一个最常见的 Identifier 节点:
{ type: 'Identifier', name: 'add' }
表示这是一个标识符。
所以,操作 AST 也就是操作其中的节点,可以增删改这些节点,从而转换成实际需要的 AST。
更多的节点规范可以在https://github.com/estree/estree中查看。
Babel 对于 AST 的遍历是深度优先遍历,对于 AST 上的每一个分支 Babel 都会先向下遍历走到尽头,然后再向上遍历退出刚遍历过的节点,然后寻找下一个分支。
还是上面的🌰:
{ "type": "Program", "body": [ { "type": "VariableDeclaration", // 变量声明 "declarations": [ // 具体声明 { "type": "VariableDeclarator", // 变量声明 "id": { "type": "Identifier", // 标识符(最基础的) "name": "add" // 函数名 }, "init": { "type": "ArrowFunctionExpression", // 箭头函数 "id": null, "expression": true, "generator": false, "params": [ // 参数 { "type": "Identifier", "name": "a" }, { "type": "Identifier", "name": "b" } ], "body": { // 函数体 "type": "BinaryExpression", // 二项式 "left": { // 二项式左边 "type": "Identifier", "name": "a" }, "operator": "+", // 二项式运算符 "right": { // 二项式右边 "type": "Identifier", "name": "b" } } } } ], "kind": "const" } ], "sourceType": "module" }
根节点我们就不说了,从 declarations 里开始遍历:
声明了一个变量,并且知道了它的内部属性(
id、init),然后我们再以此访问每一个属性以及它们的子节点。id是一个Idenrifier,有一个name属性表示变量名。之后是
init,init也有好几个内部属性:
type是ArrowFunctionExpression,表示这是一个箭头函数表达式params是这个箭头函数的入参,其中每一个参数都是一个Identifier类型的节点;body属性是这个箭头函数的主体,这是一个BinaryExpression二项式:left、operator、right,分别表示二项式的左边变量、运算符以及右边变量。
这是遍历 AST 的白话形式,再看看 Babel 是怎么做的:
Babel 会维护一个称作 Visitor 的对象,这个对象定义了用于 AST 中获取具体节点的方法。
Visitor
一个 Visitor 一般来说是这样的:
var visitor = { ArrowFunction() { console.log('我是箭头函数'); }, IfStatement() { console.log('我是一个if语句'); }, CallExpression() {} };
当我们遍历 AST 的时候,如果匹配上一个 type,就会调用 visitor 里的方法。
这只是一个简单的 Visitor。
上面说过,Babel 遍历 AST 其实会经过两次节点:遍历的时候和退出的时候,所以实际上 Babel 中的 Visitor 应该是这样的:
var visitor = { Identifier: { enter() { console.log('Identifier enter'); }, exit() { console.log('Identifier exit'); } } };
比如我们拿这个 visitor 来遍历这样一个 AST:
params: [ // 参数 { "type": "Identifier", "name": "a" }, { "type": "Identifier", "name": "b" } ]
过程可能是这样的...
进入
Identifier(params[0])走到尽头
退出
Identifier(params[0])进入
Identifier(params[1])走到尽头
退出
Identifier(params[1])
当然,Babel 中的 Visitor 模式远远比这复杂...
回到上面的🌰,箭头函数是 ES5 不支持的语法,所以 Babel 得把它转换成普通函数,一层层遍历下去,找到了 ArrowFunctionExpression 节点,这时候就需要把它替换成 FunctionDeclaration 节点。所以,箭头函数可能是这样处理的:
`import * as t from "@babel/types";
var visitor = {
ArrowFunction(path) {
path.replaceWith(t.FunctionDeclaration(id, params, body));
}
};
`
对细节感兴趣的可以翻翻源码https://github.com/babel/babel/tree/master/packages/babel-traverse。
Generate(代码生成)
经过上面两个阶段,需要转译的代码已经经过转换,生成新的 AST 了,最后一个阶段理所应当就是根据这个 AST 来输出代码。
Babel 是通过 https://github.com/babel/babel/tree/master/packages/babel-generator 来完成的。当然,也是深度优先遍历。
class Generator extends Printer { constructor(ast, opts = {}, code) { const format = normalizeOptions(code, opts); const map = opts.sourceMaps ? new SourceMap(opts, code) : null; super(format, map); this.ast = ast; } ast: Object; generate() { return super.generate(this.ast); } }
经过这三个阶段,代码就被 Babel 转译成功了。
任重而道远...
,想真正掌握 Babel 还有很长的路...
参考链接
Babel是如何读懂JS代码的: https://zhuanlan.zhihu.com/p/27289600
the super tiny compiler: https://github.com/jamiebuilds/the-super-tiny-compiler
理解 Babel 插件: http://taobaofed.org/blog/2016/09/30/babel-plugins/
❤️ 看完三件事
如果你觉得这篇内容对你挺有启发,我想邀请你帮我三个小忙:
点个「在看」,让更多的人也能看到这篇内容(喜欢不点在看,都是耍流氓 -_-)
关注公众号「前端下午茶」,持续为你推送精选好文,也可以加我为好友,随时聊骚。
在看点这里

本文分享自微信公众号 - 前端下午茶(qianduanxiawucha)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。













