https://www.cnblogs.com/littleatp/p/8563273.html
mongodb配置主从模式
在大数据的时代,传统的关系型数据库要能更高的服务必须要解决高并发读写、海量数据高效存储、高可扩展性和高可用性这些难题。不过就是因为这些问题Nosql诞生了
NOSQL有这些优势:
大数据量,可以通过廉价服务器存储大量的数据,轻松摆脱传统mysql单表存储量级限制。
高扩展性,Nosql去掉了关系数据库的关系型特性,很容易横向扩展,摆脱了以往老是纵向扩展的诟病。
高性能,Nosql通过简单的key-value方式获取数据,非常快速。还有NoSQL的Cache是记录级的,是一种细粒度的Cache,所以NoSQL在这个层面上来说就要性能高很多。
灵活的数据模型,NoSQL无需事先为要存储的数据建立字段,随时可以存储自定义的数据格式。而在关系数据库里,增删字段是一件非常麻烦的事情。如果是非常大数据量的表,增加字段简直就是一个噩梦。
高可用,NoSQL在不太影响性能的情况,就可以方便的实现高可用的架构。比如mongodb通过mongos、mongo分片就可以快速配置出高可用配置。
主从模式(官方不建议使用)。使用mysql数据库时大家广泛用到,采用双机备份后主节点挂掉了后从节点可以接替主机继续服务。所以这种模式比单节点的高可用性要好很多
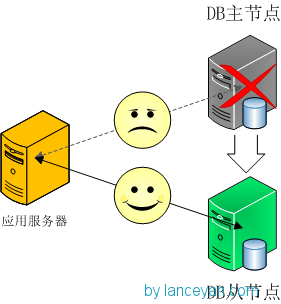
mongoDB副本集的架构图
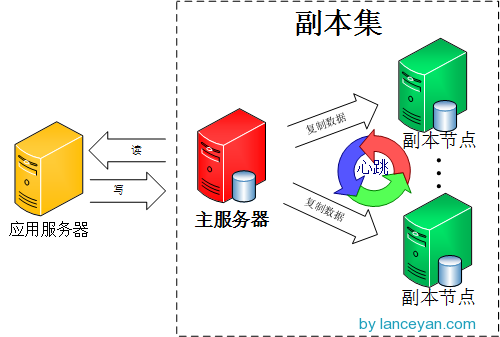
由图可以看到客户端连接到整个副本集,不关心具体哪一台机器是否挂掉。主服务器负责整个副本集的读写,副本集定期同步数据备份,一但主节点挂掉,副本节点就会选举一个新的主服务器,这一切对于应用服务器不需要关心。我们看一下主服务器挂掉后的架构:
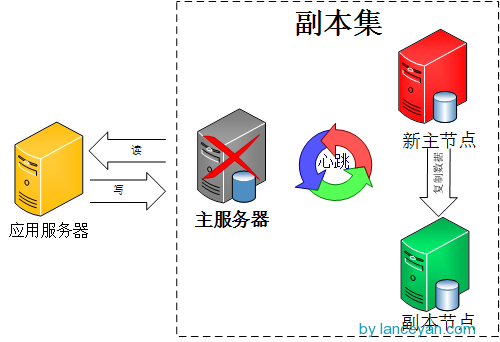
官方推荐的副本集机器数量为至少3个,那我们也按照这个数量配置测试。
1、准备两台机器 192.168.1.136、192.168.1.137、192.168.1.138。 192.168.1.136 当作副本集主节点,192.168.1.137、192.168.1.138作为副本集副本节点。
2、分别在每台机器上建立mongodb副本集测试文件夹
#存放整个mongodb文件
mkdir -p /data/mongodbtest/replset
#存放mongodb数据文件
mkdir -p /data/mongodbtest/replset/data
#进入mongodb文件夹
cd /data/mongodbtest
3、下载mongodb的安装程序包
wget http:``//fastdl``.mongodb.org``/linux/mongodb-linux-x86_64-2``.4.8.tgz
注意linux生产环境不能安装32位的mongodb,因为32位受限于操作系统最大2G的文件限制。
#解压下载的压缩包
tar xvzf mongodb-linux-x86_64-2.4.8.tgz
4、分别在每台机器上启动mongodb
/data/mongodbtest/mongodb-linux-x86_64-2``.4.8``/bin/mongod --dbpath /data/mongodbtest/replset/data --replSet repset
可以看到控制台上显示副本集还没有配置初始化信息。
5、初始化副本集
在三台机器上任意一台机器登陆mongodb
/data/mongodbtest/mongodb-linux-x86_64-2``.4.8``/bin/mongo
#使用admin数据库
use admin
#定义副本集配置变量,这里的 _id:”repset” 和上面命令参数“ –replSet repset” 要保持一样。
config = { _id: "repset" , members:[
... {_id:0,host: "192.168.1.136:27017" },
... {_id:1,host: "192.168.1.137:27017" },
... {_id:2,host: "192.168.1.138:27017" }]
... }
{
"_id" : "repset",
"members" : [
{
"_id" : 0,
"host" : "192.168.1.136:27017"
},
{
"_id" : 1,
"host" : "192.168.1.137:27017"
},
{
"_id" : 2,
"host" : "192.168.1.138:27017"
}
]
}
#初始化副本集配置
rs.initiate(config);
6、测试副本集数据复制功能