

Dubbo 路由机制是在服务间的调用时,通过将服务提供者按照设定的路由规则来决定调用哪一个具体的服务。
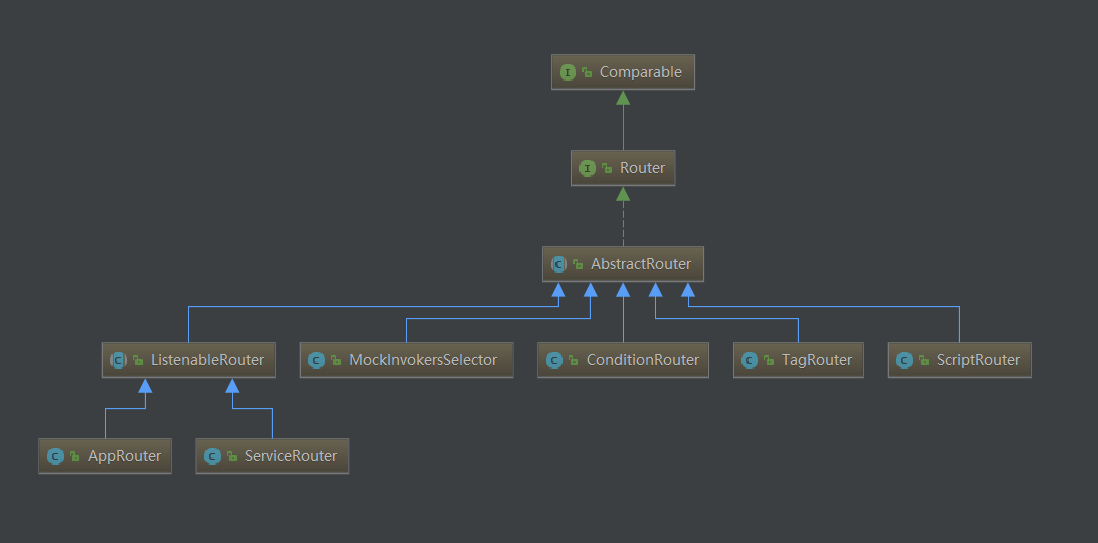
路由服务结构
Dubbo 实现路由都是通过实现 RouterFactory 接口。当前版本 dubbo-2.7.5 实现该接口类如下:
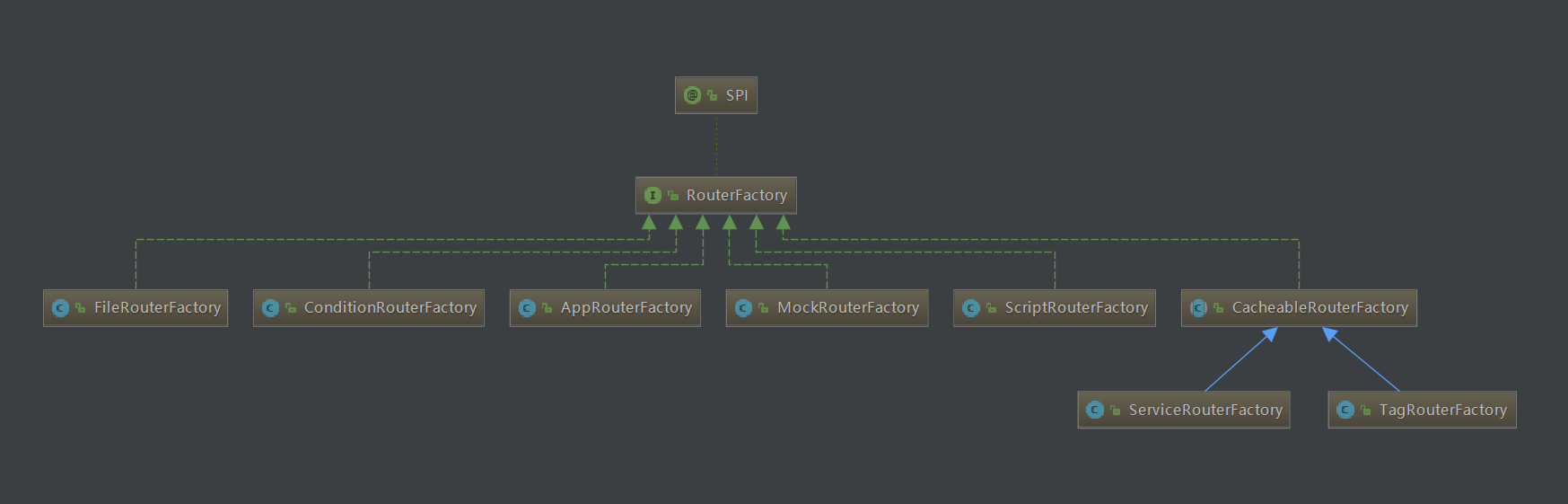
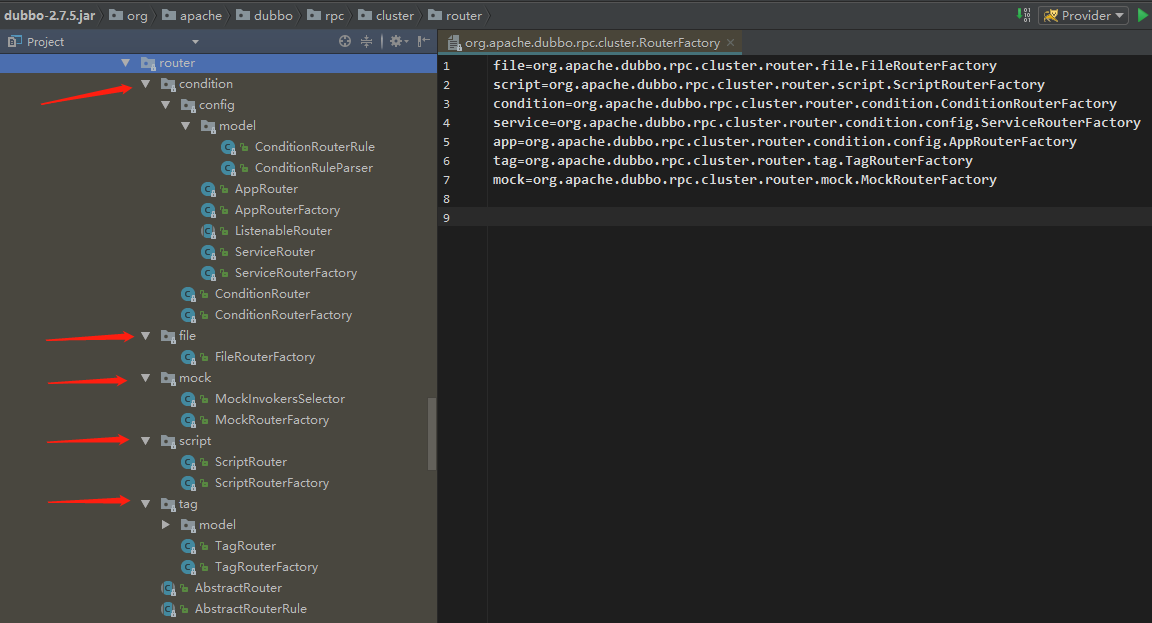
路由实现工厂类是在 router 包下
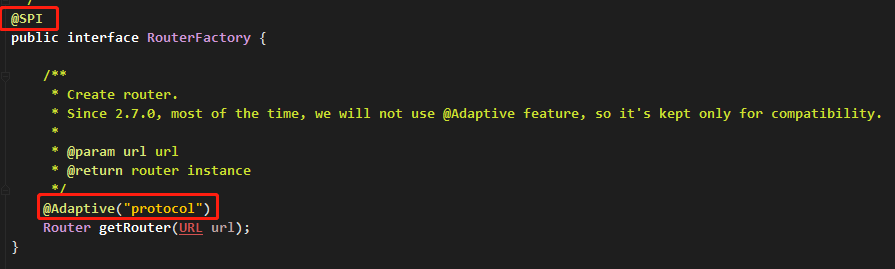
由于 RouterFactory 是 SPI 接口,同时在获取路由 RouterFactory#getRouter 方法上有 @Adaptive("protocol") 注解,所以在获取路由的时候会动态调用需要的工厂类。
可以看到 getRouter 方法返回的是一个 Router 接口,该接口信息如下
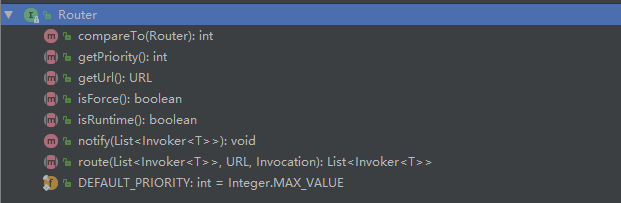
其中 Router#route 是服务路由的入口,对于不同类型的路由工厂,有特定的 Router 实现类。
以上就是通过解析 URL,获取到具体的 Router,通过调用 Router#router 过滤出符合当前路由规则的 invokers。
服务路由实现
上面展示了路由实现类,这几个实现类型中,ConditionRouter 条件路由是最为常用的类型,由于文章篇幅有限,本文就不对全部的路由类型逐一分析,只对条件路由进行具体分析,只要弄懂这一个类型,其它类型的解析就能容易掌握。
条件路由参数规则
在分析条件路由前,先了解条件路由的参数配置,官方文档如下:

条件路由规则内容如下:

条件路由实现分析
分析路由实现,主要分析工厂类的 xxxRouterFactory#getRouter 和 xxxRouter#route 方法。
ConditionRouterFactory#getRouter
ConditionRouterFactory 中通过创建 ConditionRouter 对象来初始化解析相关参数配置。

在 ConditionRouter 构造函数中,从 URL 里获取 rule 的字符串格式的规则,解析规则在 ConditionRouter#init 初始化方法中。
public void init(String rule) {
try {
if (rule == null || rule.trim().length() == 0) {
throw new IllegalArgumentException("Illegal route rule!");
}
// 去掉 consumer. 和 provider. 的标识
rule = rule.replace("consumer.", "").replace("provider.", "");
// 获取 消费者匹配条件 和 提供者地址匹配条件 的分隔符
int i = rule.indexOf("=>");
// 消费者匹配条件
String whenRule = i < 0 ? null : rule.substring(0, i).trim();
// 提供者地址匹配条件
String thenRule = i < 0 ? rule.trim() : rule.substring(i + 2).trim();
// 解析消费者路由规则
Map<String, MatchPair> when = StringUtils.isBlank(whenRule) || "true".equals(whenRule) ? new HashMap<String, MatchPair>() : parseRule(whenRule);
// 解析提供者路由规则
Map<String, MatchPair> then = StringUtils.isBlank(thenRule) || "false".equals(thenRule) ? null : parseRule(thenRule);
// NOTE: It should be determined on the business level whether the `When condition` can be empty or not.
this.whenCondition = when;
this.thenCondition = then;
} catch (ParseException e) {
throw new IllegalStateException(e.getMessage(), e);
}
}
以路由规则字符串中的=>为分隔符,将消费者匹配条件和提供者匹配条件分割,解析两个路由规则后,赋值给当前对象的变量。
调用 parseRule 方法来解析消费者和服务者路由规则。
// 正则验证路由规则
protected static final Pattern ROUTE_PATTERN = Pattern.compile("([&!=,]*)\\s*([^&!=,\\s]+)");
private static Map<String, MatchPair> parseRule(String rule)
throws ParseException {
/**
* 条件变量和条件变量值的映射关系
* 比如 host => 127.0.0.1 则保存着 host 和 127.0.0.1 的映射关系
*/
Map<String, MatchPair> condition = new HashMap<String, MatchPair>();
if (StringUtils.isBlank(rule)) {
return condition;
}
// Key-Value pair, stores both match and mismatch conditions
MatchPair pair = null;
// Multiple values
Set<String> values = null;
final Matcher matcher = ROUTE_PATTERN.matcher(rule);
while (matcher.find()) {
// 获取正则前部分匹配(第一个括号)的内容
String separator = matcher.group(1);
// 获取正则后部分匹配(第二个括号)的内容
String content = matcher.group(2);
// 如果获取前部分为空,则表示规则开始位置,则当前 content 必为条件变量
if (StringUtils.isEmpty(separator)) {
pair = new MatchPair();
condition.put(content, pair);
}
// 如果分隔符是 &,则 content 为条件变量
else if ("&".equals(separator)) {
// 当前 content 是条件变量,用来做映射集合的 key 的,如果没有则添加一个元素
if (condition.get(content) == null) {
pair = new MatchPair();
condition.put(content, pair);
} else {
pair = condition.get(content);
}
}
// 如果当前分割符是 = ,则当前 content 为条件变量值
else if ("=".equals(separator)) {
if (pair == null) {
throw new ParseException("Illegal route rule \""
+ rule + "\", The error char '" + separator
+ "' at index " + matcher.start() + " before \""
+ content + "\".", matcher.start());
}
// 由于 pair 还没有被重新初始化,所以还是上一个条件变量的对象,所以可以将当前条件变量值在引用对象上赋值
values = pair.matches;
values.add(content);
}
// 如果当前分割符是 = ,则当前 content 也是条件变量值
else if ("!=".equals(separator)) {
if (pair == null) {
throw new ParseException("Illegal route rule \""
+ rule + "\", The error char '" + separator
+ "' at index " + matcher.start() + " before \""
+ content + "\".", matcher.start());
}
// 与 = 时同理
values = pair.mismatches;
values.add(content);
}
// 如果当前分割符为 ',',则当前 content 也为条件变量值
else if (",".equals(separator)) { // Should be separated by ','
if (values == null || values.isEmpty()) {
throw new ParseException("Illegal route rule \""
+ rule + "\", The error char '" + separator
+ "' at index " + matcher.start() + " before \""
+ content + "\".", matcher.start());
}
// 直接向条件变量值集合中添加数据
values.add(content);
} else {
throw new ParseException("Illegal route rule \"" + rule
+ "\", The error char '" + separator + "' at index "
+ matcher.start() + " before \"" + content + "\".", matcher.start());
}
}
return condition;
}
上面就是解析条件路由规则的过程,条件变量的值都保存在 MatchPair 中的 matches、mismatches 属性中,=和,的条件变量值放在可以匹配的 matches 中,!=的条件变量值放在不可匹配路由规则的 mismatches 中。赋值过程中,代码还是比较优雅。

实际上 matches、mismatches 就是保存的是条件变量值。
ConditionRouter#route
Router#route的作用就是匹配出符合路由规则的 Invoker 集合。
// 在初始化中进行被复制的变量
// 消费者条件匹配规则
protected Map<String, MatchPair> whenCondition;
// 提供者条件匹配规则
protected Map<String, MatchPair> thenCondition;
public <T> List<Invoker<T>> route(List<Invoker<T>> invokers, URL url, Invocation invocation)
throws RpcException {
if (!enabled) {
return invokers;
}
// 验证 invokers 是否为空
if (CollectionUtils.isEmpty(invokers)) {
return invokers;
}
try {
// 校验消费者是否有规则匹配,如果没有则返回传入的 Invoker
if (!matchWhen(url, invocation)) {
return invokers;
}
List<Invoker<T>> result = new ArrayList<Invoker<T>>();
if (thenCondition == null) {
logger.warn("The current consumer in the service blacklist. consumer: " + NetUtils.getLocalHost() + ", service: " + url.getServiceKey());
return result;
}
// 遍历传入的 invokers,匹配提供者是否有规则匹配
for (Invoker<T> invoker : invokers) {
if (matchThen(invoker.getUrl(), url)) {
result.add(invoker);
}
}
// 如果 result 不为空,或当前对象 force=true 则返回 result 的 Invoker 列表
if (!result.isEmpty()) {
return result;
} else if (force) {
logger.warn("The route result is empty and force execute. consumer: " + NetUtils.getLocalHost() + ", service: " + url.getServiceKey() + ", router: " + url.getParameterAndDecoded(RULE_KEY));
return result;
}
} catch (Throwable t) {
logger.error("Failed to execute condition router rule: " + getUrl() + ", invokers: " + invokers + ", cause: " + t.getMessage(), t);
}
return invokers;
}
上面代码可以看到,只要消费者没有匹配的规则或提供者没有匹配的规则及 force=false 时,不会返回传入的参数的 Invoker。
匹配消费者路由规则和提供者路由规则方法是 matchWhen 和 matchThen
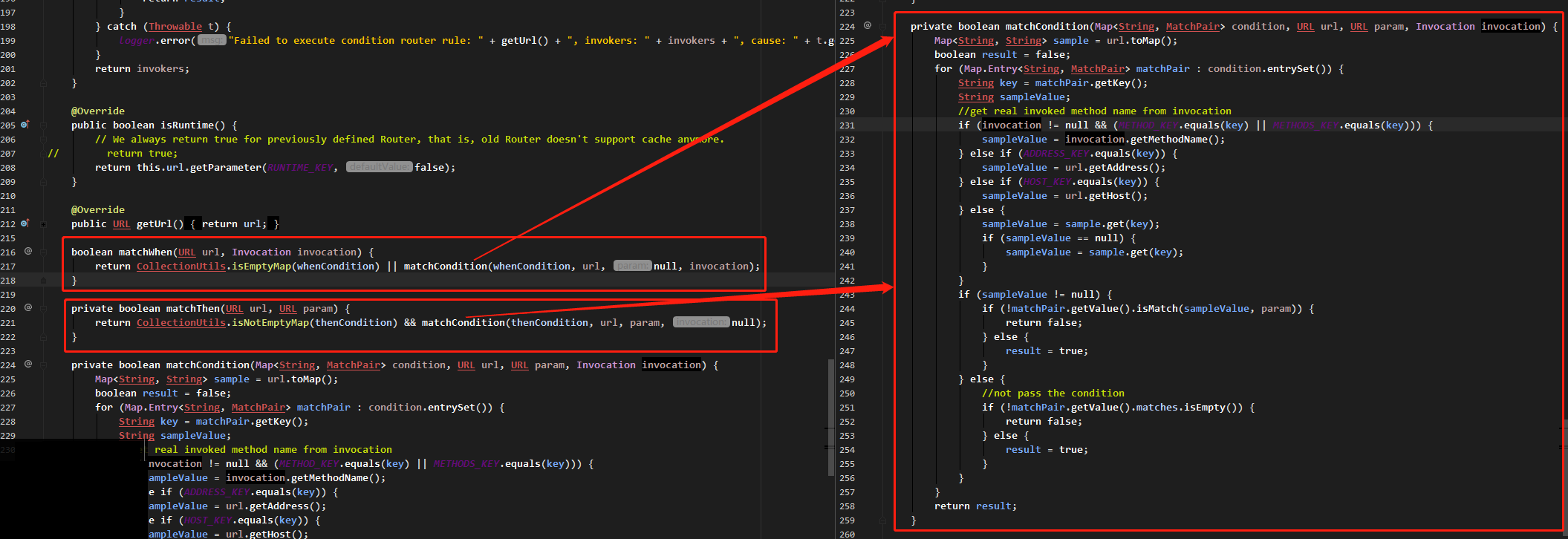
这两个匹配方法都是调用同一个方法 matchCondition 实现的。将消费者或提供者 URL 转为 Map,然后与 whenCondition 或 thenCondition 进行匹配。
匹配过程中,如果 key (即 sampleValue 值)存在对应的值,则通过 MatchPair#isMatch 方法再进行匹配。
private boolean isMatch(String value, URL param) {
// 存在可匹配的规则,不存在不可匹配的规则
if (!matches.isEmpty() && mismatches.isEmpty()) {
// 不可匹配的规则列表为空时,只要可匹配的规则匹配上,直接返回 true
for (String match : matches) {
if (UrlUtils.isMatchGlobPattern(match, value, param)) {
return true;
}
}
return false;
}
// 存在不可匹配的规则,不存在可匹配的规则
if (!mismatches.isEmpty() && matches.isEmpty()) {
// 不可匹配的规则列表中存在,则返回false
for (String mismatch : mismatches) {
if (UrlUtils.isMatchGlobPattern(mismatch, value, param)) {
return false;
}
}
return true;
}
// 存在可匹配的规则,也存在不可匹配的规则
if (!matches.isEmpty() && !mismatches.isEmpty()) {
// 都不为空时,不可匹配的规则列表中存在,则返回 false
for (String mismatch : mismatches) {
if (UrlUtils.isMatchGlobPattern(mismatch, value, param)) {
return false;
}
}
for (String match : matches) {
if (UrlUtils.isMatchGlobPattern(match, value, param)) {
return true;
}
}
return false;
}
// 最后剩下的是 可匹配规则和不可匹配规则都为空时
return false;
}
匹配过程再调用 UrlUtils#isMatchGlobPattern 实现
public static boolean isMatchGlobPattern(String pattern, String value, URL param) {
// 如果以 $ 开头,则获取 URL 中对应的值
if (param != null && pattern.startsWith("$")) {
pattern = param.getRawParameter(pattern.substring(1));
}
//
return isMatchGlobPattern(pattern, value);
}
public static boolean isMatchGlobPattern(String pattern, String value) {
if ("*".equals(pattern)) {
return true;
}
if (StringUtils.isEmpty(pattern) && StringUtils.isEmpty(value)) {
return true;
}
if (StringUtils.isEmpty(pattern) || StringUtils.isEmpty(value)) {
return false;
}
// 获取通配符位置
int i = pattern.lastIndexOf('*');
// 如果value中没有 "*" 通配符,则整个字符串值匹配
if (i == -1) {
return value.equals(pattern);
}
// 如果 "*" 在最后面,则匹配字符串 "*" 之前的字符串即可
else if (i == pattern.length() - 1) {
return value.startsWith(pattern.substring(0, i));
}
// 如果 "*" 在最前面,则匹配字符串 "*" 之后的字符串即可
else if (i == 0) {
return value.endsWith(pattern.substring(i + 1));
}
// 如果 "*" 不在字符串两端,则同时匹配字符串 "*" 左右两边的字符串
else {
String prefix = pattern.substring(0, i);
String suffix = pattern.substring(i + 1);
return value.startsWith(prefix) && value.endsWith(suffix);
}
}
就这样完成全部的条件路由规则匹配,虽然看似代码较为繁杂,但是理清规则、思路,一步一步还是较好解析,前提是要熟悉相关参数的用法及形式,不然代码较难理解。
最后
单纯从逻辑上,如果能够掌握条件路由的实现,去研究其它方式的路由实现,相信不会有太大问题。只是例如像脚本路由的实现,你得先会使用脚本执行引擎为前提,不然就不理解它的代码。最后,在 dubbo-admin 上可以设置路由,大家可以尝试各种使用规则,通过实操才能更好掌握和理解路由机制的实现。
Dubbo 相关文章











