
简介
我们通过上几篇的介绍已经初步的掌握了Redis集群的相关内容,但这都是针对Redis服务端来说。我们还没有使用客户端去操作Reids集群。Redis为了追求性能的最大化,对集群环境的客户端通信协议做了非常大的修改,也就是说如果我们要从单节点连接Redis切换到连接集群环境Redis,那么客户端的代码需要做出相应的修改。
下面我们介绍一下Redis中的请求重定向。
请求重定向
既然是重定向我们就应该了解,重定向指的是通过某种方法将原来的请求重新转向其它的地方,那么Redis中的重定向指的到底是什么呢?我们知道Redis中的任何键都存储到槽中,而通过上几篇文章中我们知道在Redis集群环境中,槽被均匀的分布到多个主节点中了,所以在我们执行任何Redis命令时,和单节点有很大的不同,因为集群环境首先要计算键对应的槽,再根据槽找出相应的节点。如果计算之后,当前键所在的槽是当前节点,那么就直接处理该命令,如果计算完后,不是当前节点,则Redis会显示MOVED重定向错误,也就是告诉客户端该键所对应槽的正确节点是多少。这个就叫做Redis的重定向。下面我们演示一下上述所说的内容。
下面我们启动一个新节点6387。因为该节点没有添加到集群中,所以我们执行set命令时,可以直接返回成功。

下面我们在集群中执行同样的命令。

我们看在集群环境中执行同样的命令时,Redis提示了MOVED错误。原因也就是上述介绍中的那样。下面我们看一下MOVED重定向的执行流程。也就是如下图所示:
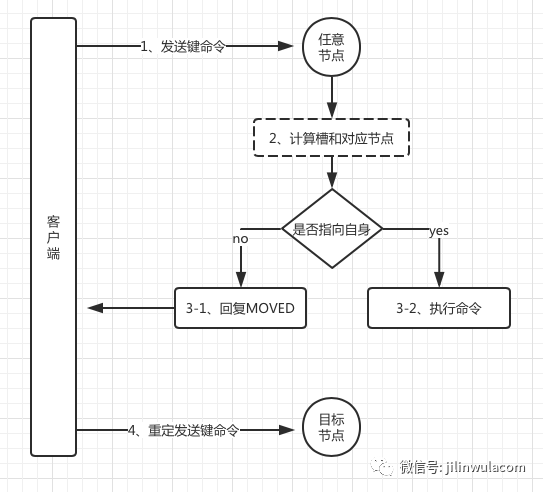
在Redis中我们可以使用cluster keyslot {key}命令查看key所对应的槽,然后在通过cluster nodes命令查看每个节点负责的槽,这样我们就可以在执行命令的时候,就可以知道在哪个节点上执行了。我还还是已上图的key为例。具体操作如下图所示:

我们用cluster keyslot {key}命令查看键所在的槽是12691。然后我们通过cluster nodes命令知道节点6382负责的槽为12288-16383。所以我们在执行命令时,只有在6382节点上执行才能成功,在其它节点上执行Redis都会报MOVED重定向错误。下面我们将上述执行失败的命令在6382节点执行。

在Redis中我们使用redis-cli执行命令时,我们可以添加-c参数,该参数会自动重定向,简化我们手动重定向操作。

键命令执行主要分两个步骤:计算槽,查找槽所在的节点。下面我们详细介绍一下这两方面的内容。
计算槽
Redis根据键的使用CRC16函数计算键的散列值,然后在用散列值对16383取余,这样使每个键都可以映射到0-16383槽范围内。
槽节点查找
Redis计算得到键所对应的槽后,需要查找槽所在的节点。集群內通过消息交换每个节点都会知道所有节点的槽的信息。根据MOVED重定向机制,客户端可以随机连接集群内的任意Redis获取键的所在节点,这种客户端叫做傀儡客户端,它的优点是代码实现简单,对客户端协议影响比较小,只需要根据重定向信息再次发送请求即可。但这样也有它的弊端,也就是每次执行键命令前都要到Redis上进行重定向才能找到要执行命令的节点。这样就额外的增加了IO开销。正是因为这样的弊端所以Redis提供了另一种技术实现,也叫Smart(智能)客户端,在下一篇中,我们在介绍Smart相关的内容。
本文分享自微信公众号 - 吉林乌拉(jilinwulacom)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。












