
这是最好的时代,也是最坏的时代。
在这个信息爆炸的时代,学术论文以指数级爆发性增长。
每隔几年世界上的论文数量就会翻一翻。
几乎每年都有超过350万篇的论文被发表出来。
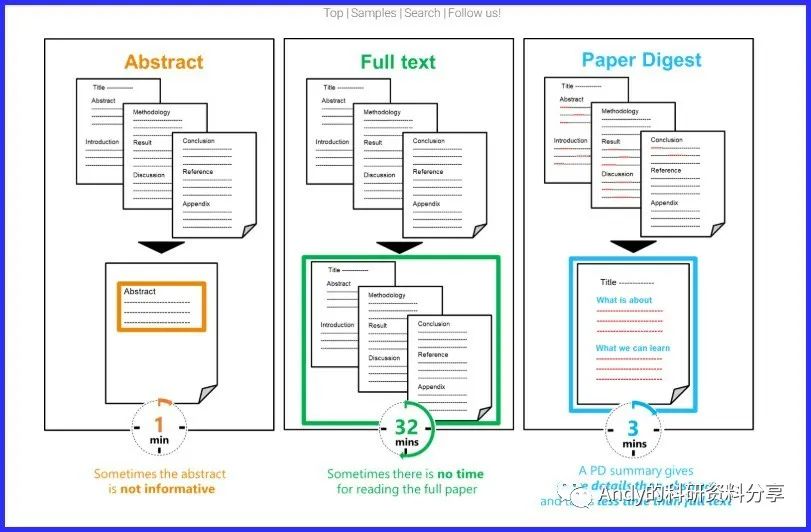
然而,阅读并理解一篇文章所讲的内容并非易事。在美国,教授们平均每月需要阅读至少20.66篇文献,而每一篇文献至少需要花费32分钟。这是Professor这种level的调查结果,对于我们这些萌新来说,必然是要花费更更更长的时间和精力!!!真是读论文读着读着头就秃了……
幸而来自东京工业大学的研究人员开发出一款可以帮助大家的人工智能在线文献总结器:Paper Digest

网址是:paper-digest.com
Paper digest的口号是:将阅读论文的时间缩短到三分钟!!!
Paper digest的使用十分简单,只需要把文献的DOI输入进去或将PDF文件上传即得。但是如果是用DOI的话,文献是要OA(Open Access)才行,非OA的不可以的。但是如果你下载了PDF文件那就可以上传让它直接去读,注册后登陆即可食用。
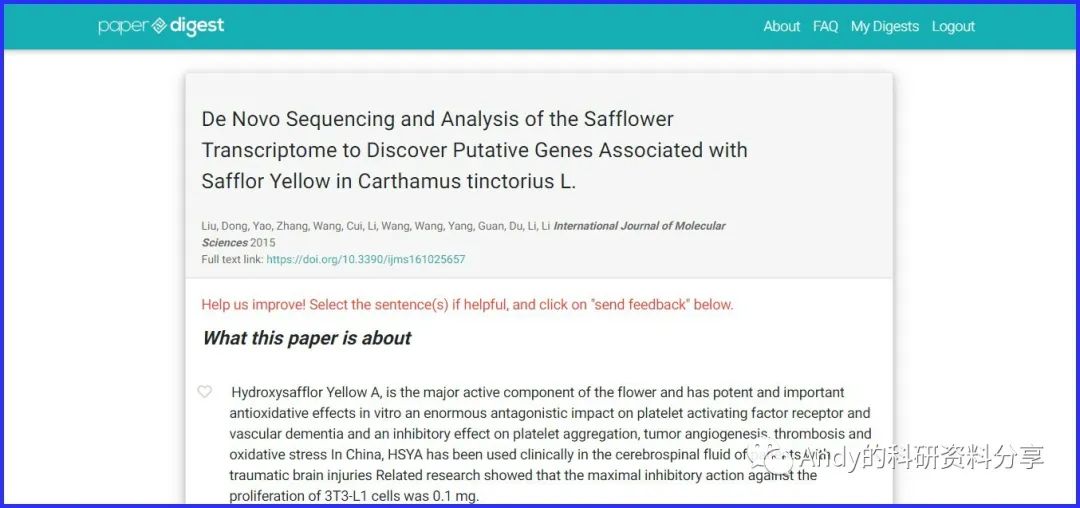
提交DOI或者上传PDF文档后,Paper Digest会用AI对整篇文章进行通篇扫描,并反馈给你文章的内容是什么(What this paper is about)及你可以从文章里学到什么(What you can learn)。即帮你粗略的阅读文献,让你知道文章是什么内容,用了什么方法,得到什么结果,大大的节省时间。

本文分享自微信公众号 - 生物信息学(swxxx1)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。













