
前言
上一篇使用逻辑回归预测了用户性别,由于矩阵比较稀疏所以会影响训练速度。所以考虑降维,降维方案有很多,本次只考虑PCA和SVD。
PCA和SVD原理
我简述一下:
- PCA是将高维数据映射到低维坐标系中,让数据尽量稀疏
- SVD就是非方阵的PCA
- 实际使用中SVD和PCA并无太大区别
- 如果特征大于数据记录数,并不能有好的效果,具体原因自己可以去看。
代码
数据获取和处理
以前文章写过很多次,这里略过 原数据shape为:2000*1900
PCA和矩阵转换
查看最佳维度数
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
pca = PCA().fit(song_hot_matrix)
plt.plot(np.cumsum(pca.explained_variance_ratio_))
plt.xlabel('number of components')
plt.ylabel('cumulative explained variance');
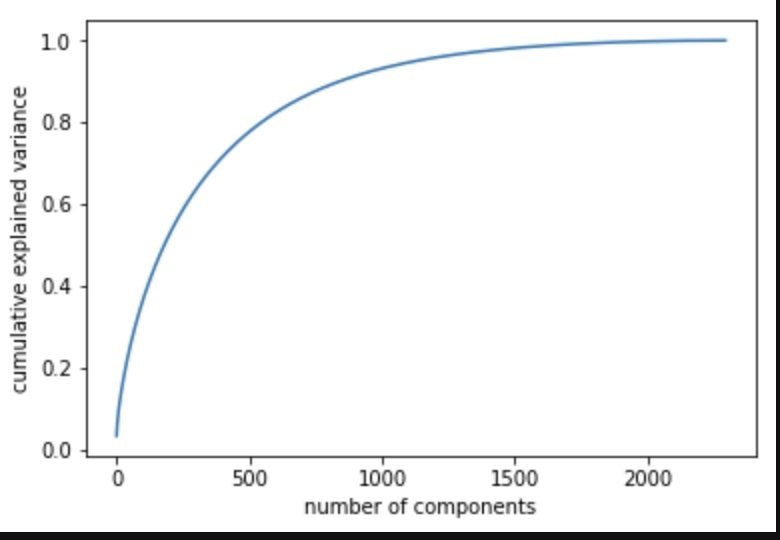
从图中可以看出大概1500维度已经可以达到90+解释性
保留99%矩阵解释性
pca = PCA(n_components=0.99, whiten=True)
song_hot_matrix_pca = pca.fit_transform(song_hot_matrix)
得到压缩后特征为: 2000*1565 并没有压缩多少
模型训练
import os
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID" # see issue #152
os.environ["CUDA_VISIBLE_DEVICES"] = ""
import numpy as np
from keras.models import Sequential
from keras.layers import Dense, Activation, Embedding,Flatten,Dropout
import matplotlib.pyplot as plt
from keras.utils import np_utils
from sklearn import datasets
from sklearn.model_selection import train_test_split
n_class=user_decades_encoder.get_class_count()
song_count=song_label_encoder.get_class_count()
print(n_class)
print(song_count)
train_X,test_X, train_y, test_y = train_test_split(song_hot_matrix_pca,
decades_hot_matrix,
test_size = 0.2,
random_state = 0)
train_count = np.shape(train_X)[0]
# 构建神经网络模型
model = Sequential()
model.add(Dense(input_dim=song_hot_matrix_pca.shape[1], units=n_class))
model.add(Activation('softmax'))
# 选定loss函数和优化器
model.compile(loss='categorical_crossentropy', optimizer='sgd', metrics=['accuracy'])
# 训练过程
print('Training -----------')
for step in range(train_count):
scores = model.train_on_batch(train_X, train_y)
if step % 50 == 0:
print("训练样本 %d 个, 损失: %f, 准确率: %f" % (step, scores[0], scores[1]*100))
print('finish!')
训练结果:
训练样本 4750 个, 损失: 0.371499, 准确率: 83.207470
训练样本 4800 个, 损失: 0.381518, 准确率: 82.193959
训练样本 4850 个, 损失: 0.364363, 准确率: 83.763909
训练样本 4900 个, 损失: 0.378466, 准确率: 82.551670
训练样本 4950 个, 损失: 0.391976, 准确率: 81.756759
训练样本 5000 个, 损失: 0.378810, 准确率: 83.505565
测试集验证:
# 准确率评估
from sklearn.metrics import classification_report
scores = model.evaluate(test_X, test_y, verbose=0)
print("%s: %.2f%%" % (model.metrics_names[1], scores[1]*100))
Y_test = np.argmax(test_y, axis=1)
y_pred = model.predict_classes(song_hot_matrix_pca.transform(test_X))
print(classification_report(Y_test, y_pred))
accuracy: 50.20%
很明显已经过拟合
处理过拟合-增加Dropout
这里使用加Dropout,随机丢弃特征的方式处理过拟合,代码:
# 构建神经网络模型
model = Sequential()
model.add(Dropout(0.5))
model.add(Dense(input_dim=song_hot_matrix_pca.shape[1], units=n_class))
model.add(Activation('softmax'))
accuracy:70%
处理过拟合-L1L2正则
这里给权重增加正则
# 构建神经网络模型
model = Sequential()
model.add(Dense(input_dim=song_hot_matrix_pca.shape[1], units=n_class, kernel_regularizer=regularizers.l2(0.01)))
model.add(Activation('softmax'))
accuracy:62%
Well Done
其实SVD的做法与PCA类似,这里不再演示。经过我测试发现,在我的数据集上,PCA虽然加快了训练速度,但是丢弃了太多特征,导致数据很容易过拟合。加入Dropout或者增加正则相可以改善过拟合的情况,下一篇会分享自编码降维。











