
背景
近年来,公司业务发展迅猛,为数众多的业务场景产生了大量的图片,文档,音频,视频等非结构化数据,尤其是随着移动互联网、AI、IoT技术的成熟和应用市场的全面爆发,大量智能硬件设备将会生成更大规模的非结构化多媒体数据。如此大量的小文件如何存储,问题应运而生。传统存储厂商出售的存储服务价格昂贵,公有云厂商对具体业务场景的定制化改造略有欠缺,因此,我们决定自研小文件存储服务。
NebulasFs简介
曾经关注小文件存储技术的同学可能阅读过Facebook发表的那篇关于海量小图片存储系统Haystack的论文(Finding a needle in Haystack: Facebook’s photo storage),Haystack通过合并多个小文件成一个大文件、以减少文件数量的方式解决了普通文件系统在存储数量巨大的小文件时的问题:获取一次文件多次读取元数据信息、文件访问的“长尾”效应导致大量文件元数据不容易缓存等。基于在Haystack的论文中得到的借鉴和参考,我们研发了自己的分布式小文件存储系统——NebulasFs。它是一个分布式、高可用、高可靠、持久化小文件存储系统,可以存储数以百亿的小文件。
架构设计
从分布式角色上划分,可以分为Master和Datanode两个大的角色。
其中,Master负责集群的元数据存储、集群管理、任务调度等工作,它的数据一致性目前由外部一致性工具(ETCD等)实现。Master是一个主多个备。
Datanode是面向用户的,它主要负责数据存储和用户请求的路由、分发。Datanode节点包括存储Volume文件和Proxy模块。如下图所示:
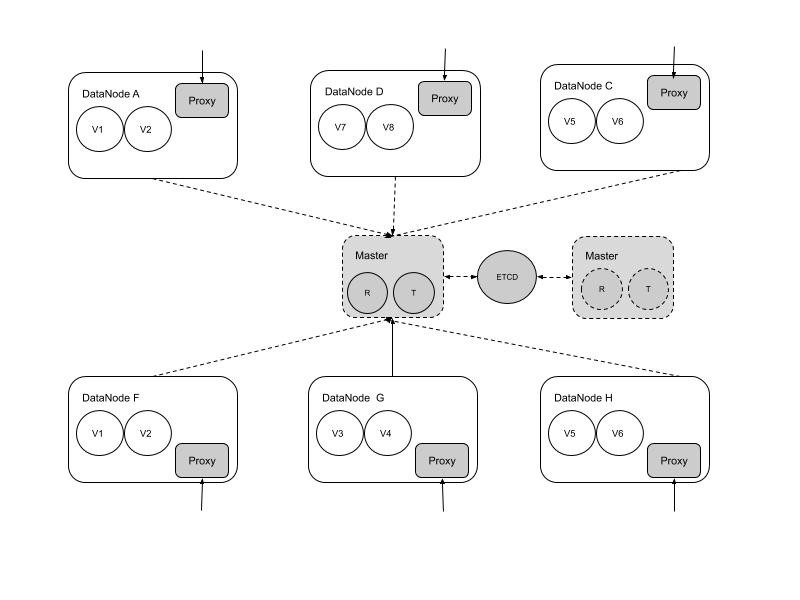
用户的请求可以请求任意一个Datanode节点,节点的Proxy模块会代理用户请求到正确的数据存储节点,并返回给用户结构。对于多个副本的写请求,Proxy模块会按照副本的一致顺序并行写入直至全部成功后返回。对于读请求只读取第一个副本。
NebulasFs功能
为了在存储容量、一致性、可用性等方面有更好的提升来满足海量小文件存储的需求,相对于Haystack论文,我们在接口服务、分布式架构方面做了更多的优化,主要体现在以下方面:
一、提供给用户使用的服务接口简单、轻量、通用
NebulasFs提供给用户Http Restful接口,协议更简单,使用更方便,用户可以通过简单的PUT,GET等操作上传和下载文件。用户无需使用定制的客户端,更加轻量级。
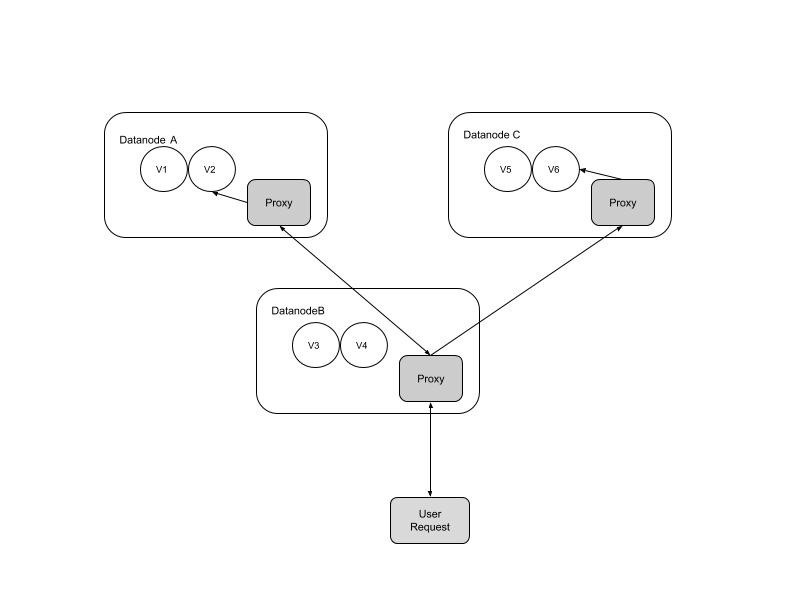
二、用户请求全代理、自动路由
我们知道,Datanode具有数据存储的功能,可是对于数量众多的Datanode来说,用户要想知道哪些数据存储在哪个Datanode上是需要先从Master 拿到数据路由的元数据才知道,这增加了用户请求的复杂度。我们在Datanode上增加了请求代理、路由模块把用户的请求自动代理、路由到正确的Datanode上,使得用户一次请求既能获取数据。
三、多租户,提供租户资源隔离机制,避免相互影响
一个集群提供的服务可能有多个用户来使用,为了避免互相影响,NebulasFs抽象出了资源池的概念,不同的资源池物理上是分布在不同的硬件之上,资源池在机器维度上不交叉,可以有效的做到资源的隔离。不同的用户可以分布在不同的资源池也可以共享资源池,这需要管理员提前做好规划。资源池类型是多样的,它的范围可能是跨数据中心的,也可能是跨机柜,也可能是在一个机柜之内的。根据不同的物理硬件性能和数据副本存储冗余需求,对不同类型的数据存储需求也需要提前规划。
四、可定制的数据多副本存储方案,数据无丢失、多种故障域组合
为了提供可用性,保证写入数据不丢失,文件数据一般都会做容灾存储大于1的副本数量,以便在发生不可恢复的硬件故障时保证数据可用性以及用作之后的自动补齐副本数量。不同重要级别的数据和不同级别故障类型决定了使用不同级别的存储方案。NebulasFs预先定义了5个级别的故障域,分别是:数据中心、机柜列、机柜、机器、磁盘。要求可用性较高的数据存储时使用跨数据中心做容灾副本,以便在整个数据中心不可用时使用另外一个数据中心的数据。要求没那么高的数据可以在做容灾副本策略的时候选择跨机柜存储即可,使得即便在边沿交换机故障后也可用。
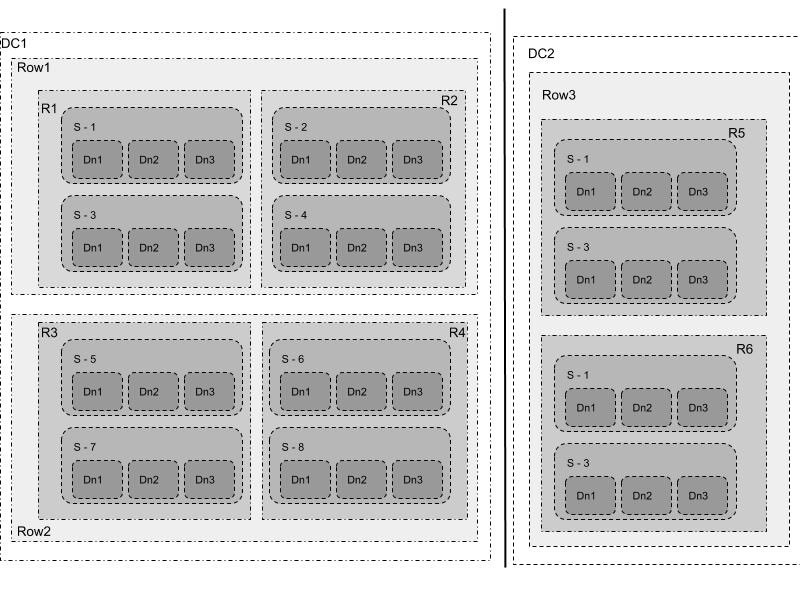
NebulasFs故障域和资源隔离池之间的关系如下:
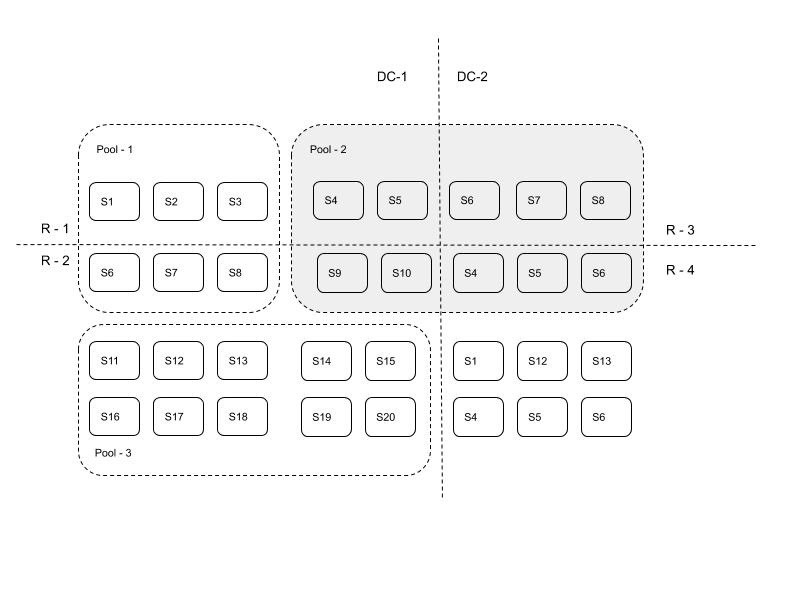
S代表服务器,R-1, R-2是属于数据中心DC-1的两个机柜,R-3, R42是属于数据中心DC-2的两个机柜。Pool-1是跨机柜故障域的资源隔离池,Pool-2是跨数据中心故障域的资源池,Pool-3是跨服务器故障域的资源池。
NebulasFs 故障域逻辑和物理概念对应如下:
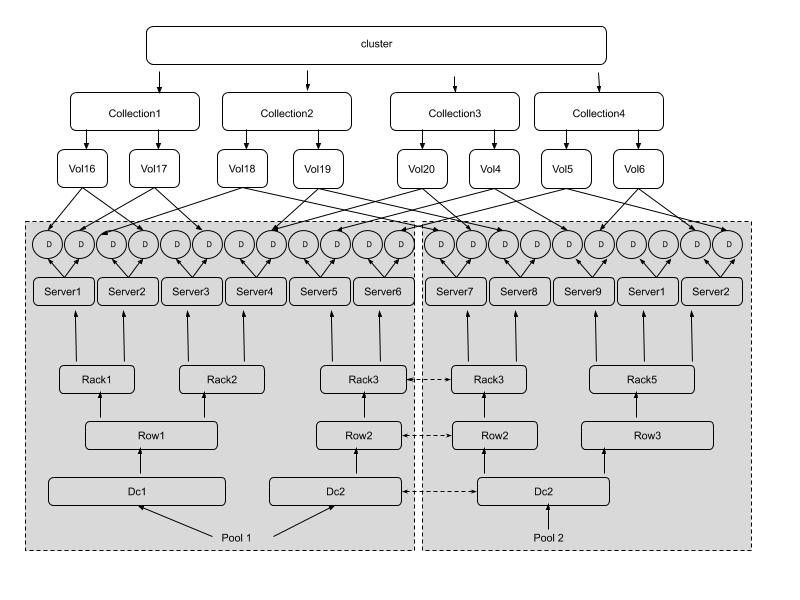
其中上半部分是逻辑概念,下半部分是物理概念。用户及请求均与逻辑概念相关,管理运维涉及物理概念相关。一个用户可以对应一个或者多个Collection, 一个Collection对应多个Volume, 每个Volume是存储在DataNode上的文件(有几个副本就有几个文件)。一般一个DataNode对应服务器上的一块硬盘。一台服务器上有多个DataNode。服务器(Server)的上层是机柜(Rack)、一排机柜(Row)和数据中心(DataCenter)。
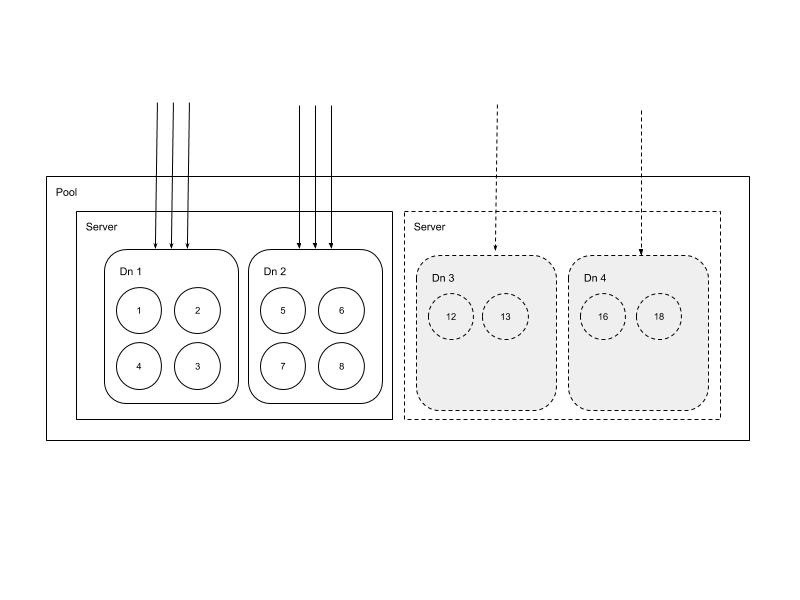
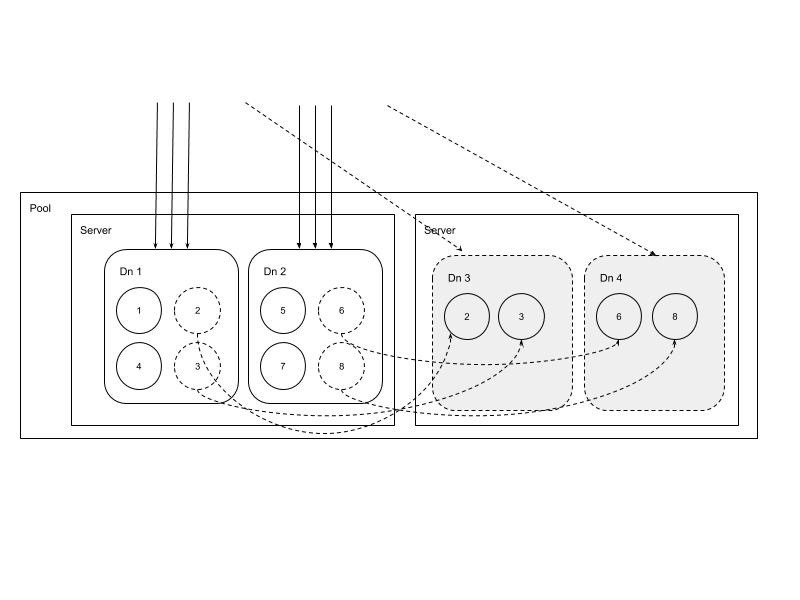
五、自动化扩容和再平衡
扩容分为存储容量不足进行扩容和请求流量过载进行的扩容。由于容量不足的扩容后无需再平衡,只有请求流量大扩容后需要做数据再平衡。再平衡是按照容灾副本数等策略进行的,按照策略添加的Datanode会自动注册到Master上,Master按照预定的规则进行协调再平衡。
两种扩容情况如下:
六、自动化副本修复补齐
一定规模的集群故障可能会变的比较频繁,在我们的系统中故障很大程度上意味着数据副本的丢失,人工补齐数据副本工作量较大,因此自动化补齐副本就成了一个比较重要的功能。自动化补齐副本是靠Master发现副本缺失和协调补齐的。在补齐的过程中数据副本都会变成只读。过程如下图:
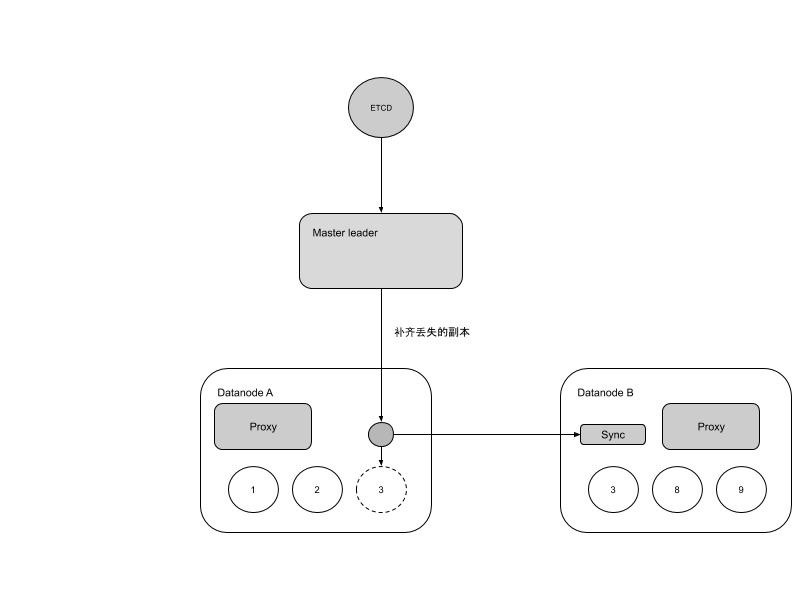
整个自动化副本补齐如下图所示:

由于硬盘故障,数据节点 2 和 3 上的Volume 3 和 6 副本丢失,自动补齐自动把这两个副本补齐到数据节点 4 和 5 上,并加入到集群中。
小 结
到目前为止,NebulasFs在内部已经使用了近一年的时间。除此之外NebulasFs还做为后端存储为另一个对象存储(AWS S3协议)提供服务以存储大文件。
伴随着业务的不断接入,NebulasFs也会不断完善,为业务增长提供更好的保障。
推荐阅读
(360技术原创内容,转载请务必保留文末二维码,谢谢~)

关于360技术
360技术是360技术团队打造的技术分享公众号,每天推送技术干货内容
更多技术信息欢迎关注“360技术”微信公众号











