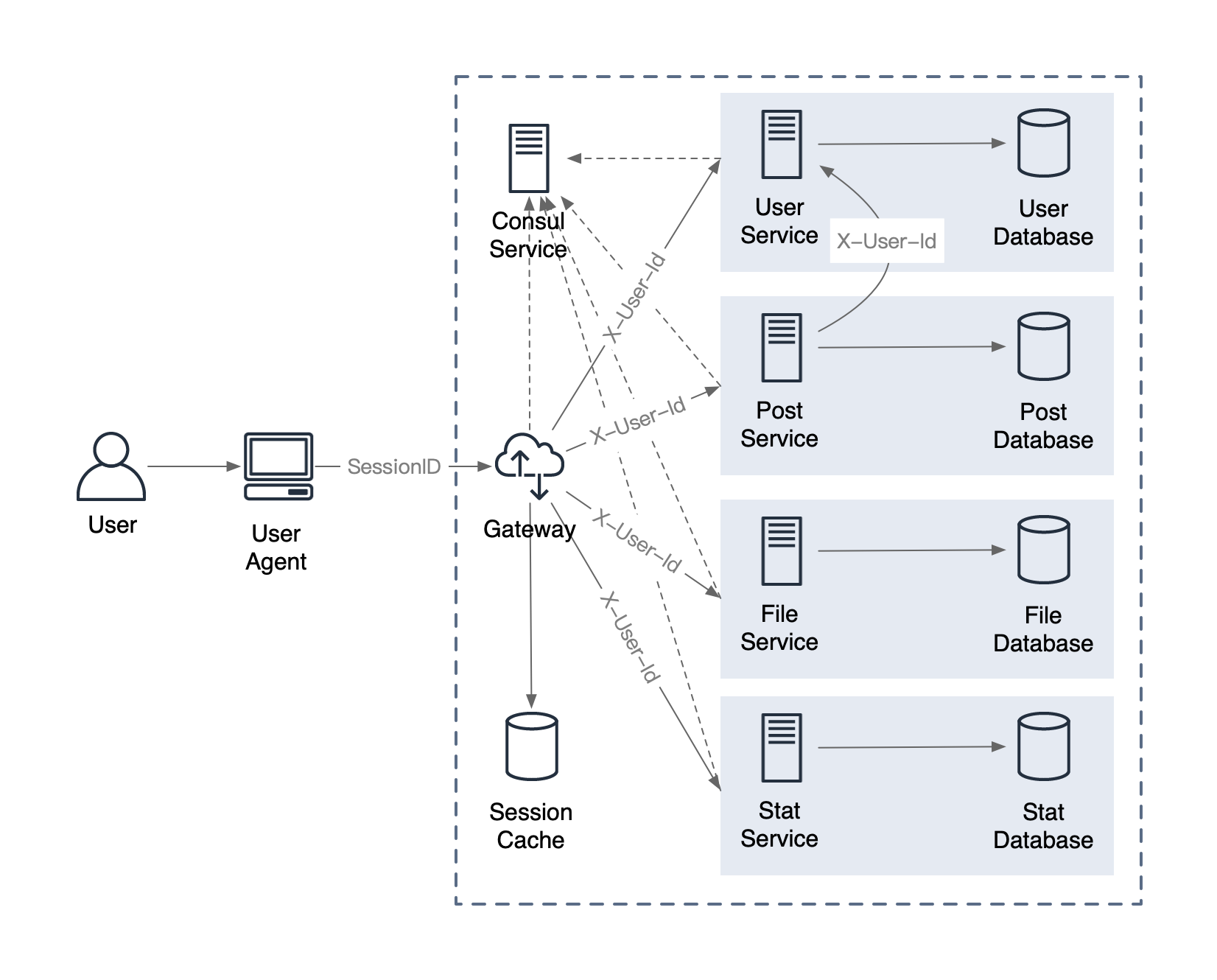
一、概述
在单体应用时代,接口缓慢能够被迅速定位和发现,而随着分布式微服务的流行,服务之间的调用关系越来越复杂,错中复杂的调用关系使得我们想找到某一个接口的效率缓慢变得非常困难,而分布式服务调用跟踪组件就解决了这个 问题。Sleuth是SprinCloud在分布式系统中提供追踪解决方案,zipkin是基于Google Dapper的分布式链路调用监控系统。先介绍下有关的专业术语,
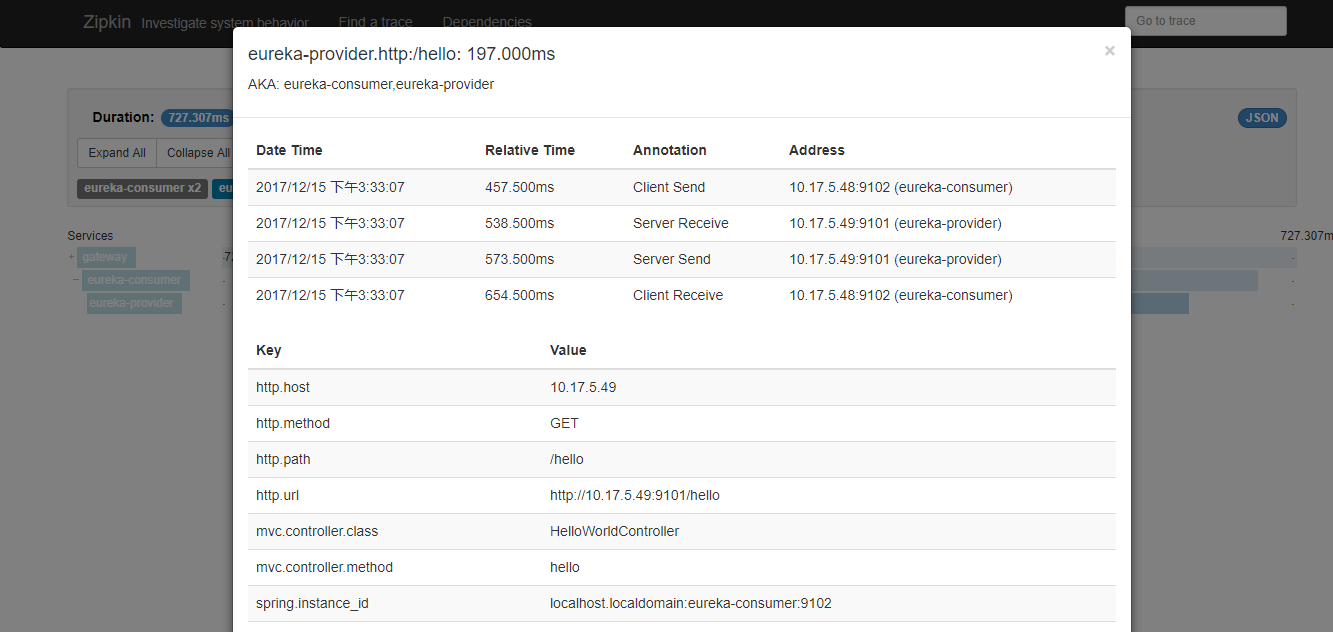
- Span:基本工作单元,例如,在一个新建的span中发送一个RPC等同于发送一个回应请求给RPC,span通过一个64位ID唯一标识,trace以另一个64位ID表示,span还有其他数据信息,比如摘要、时间戳事件、关键值注释(tags)、span的ID、以及进度ID(通常是IP地址)
- Trace:一系列spans组成的一个树状结构,例如,如果你正在跑一个分布式服务工程,你可能需要创建一个trace。
- Annotation:用来及时记录一个事件的存在,一些核心annotations用来定义一个请求的开始和结束
cs - Client Sent -客户端发起一个请求,这个annotion描述了这个span的开始
sr - Server Received -服务端获得请求并准备开始处理它,如果将其sr减去cs时间戳便可得到网 络延迟
ss - Server Sent -注解表明请求处理的完成(当请求返回客户端),如果ss减去sr时间戳便可得到服 务端需要的处理请求时间
cr - Client Received -表明span的结束,客户端成功接收到服务端的回复,如果cr减去cs时间戳 便可得到客户端从服务端获取回复的所有所需时间
二、功能开发实现
1.创建zipkin-server服务
zipkin-server主要作用是使用ZipkinServer 的功能,收集调用数据链,并提供展示页面供用户使用。创建普通的SpringBoot项目zipkin-server,在pom.xml文件中增加如下依赖
在ZipKinServerApplication主方法上添加@EnableZipkinServer注解,启用ZipkinServer功能。
@EnableZipkinServer @SpringBootApplication public class ZipkinServerApplication {
public static void main(String[] args) { SpringApplication.run(ZipkinServerApplication.class, args); } }
修改配置文件
spring.application.name=zipkin-server server.port=9107
启动服务,可以看到链路监控页面,此时没有收集到任何链路调用记录。
2.给原先服务增加链路追踪支持
给eureka-provider、eureka-consumer、gateway三个服务增加如下依赖
该依赖内部包含了两个依赖,等于同时引入了spring-cloud-starter-sleuth,spring-cloud-sleuth-zipkin两个依赖。
修改配置文件
#配置zipkin #指定zipkin的服务端,用于发送链路调用报告 spring.zipkin.base-url=http://10.17.5.50:9107
采样率,值为[0,1]之间的任意实数,这里代表100%采集报告。
spring.sleuth.sampler.percentage=1
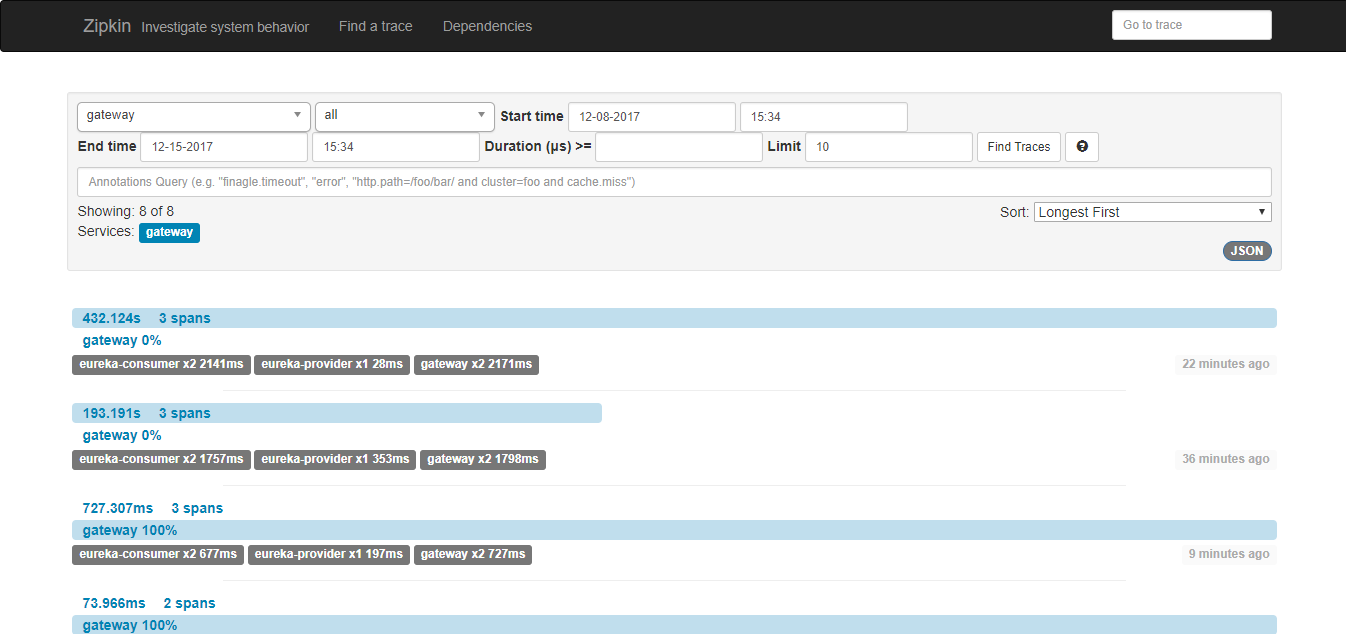
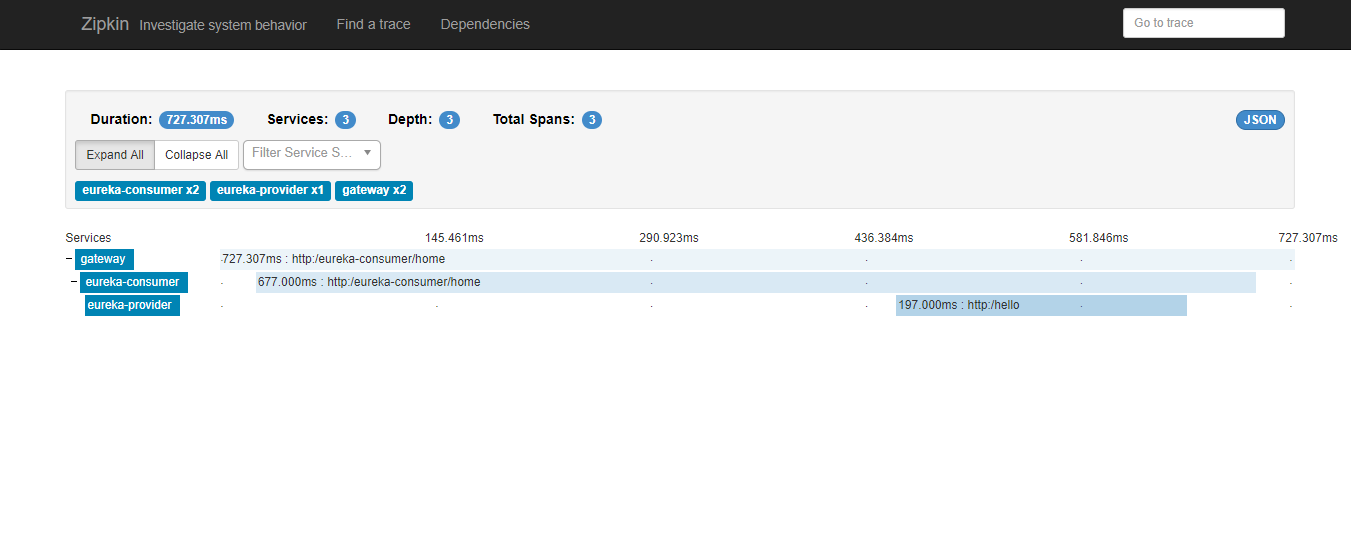
重新部署启动服务,调用zuul接口,观察zipkin-server页面,生成调用链路
三、小结
本文还只是基本的链路分析,如果生产上使用,还需要把监控内容持久化、把监控内容发送从http模式切换到MQ等改造,这些内容下次再详细介绍。