
一、 Java 线程的内存工作模型
在当前的Java内存模型下(JVM 1.2之后),线程可以把变量保存在本地内存(比如机器的寄存器)中,而不是直接在主存中进行读写。如图:
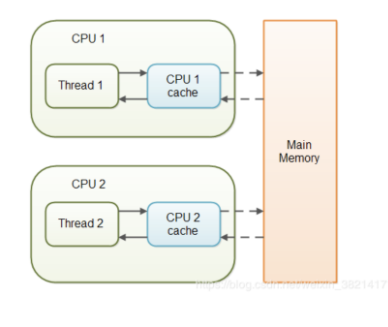
1.1 我们来看一下例子
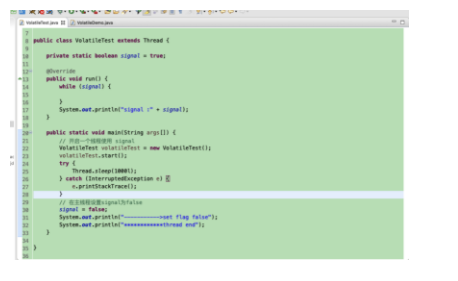
当 signal 为false时 , run 方法会终止。 上诉代码能否实现我们想要的效果。
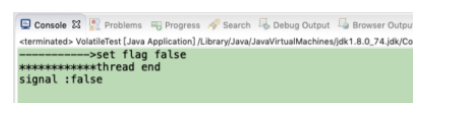
我们来看执行结果:
分析:
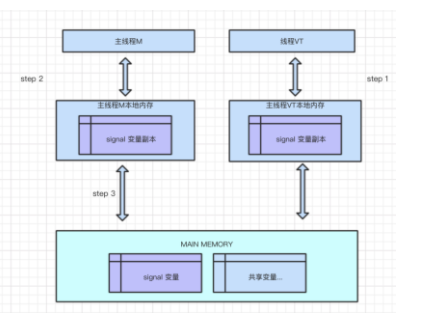
从横向去看看,线程A和线程B就好像通过共享变量在进行隐式通信。 如果线程A更新后数据并没有及时通知线程B,而此时线程B读到的是过期的数据。也就是发生了缓解数据不一致的情况。
如何解决?
可以通过同步机制(控制不同线程间操作发生的相对顺序)来解决或者通过volatile关键字使得每次volatile变量都能够强制刷新到主存,从而对每个线程都是可见的。volatile相较与同步机制会更轻量,性能更好。
修改代码:

可以得出我们想要的结果:
二、volatile底层原理
volatile从内存语义上来看:
当写一个volatile变量时,JMM会把该线程对应的本地内存中的共享变量刷新到主内存
当读一个volatile变量时,线程接下来将从主内存中读取共享变量。
那底层的实现原理是什么?
2.1 首先,查看字节码(javac \ javap)
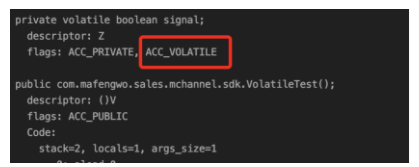
然后再编译成汇编语言(hsdis)
Java -XX:+UnlockDiagnosticVMOptions -XX:+PrintAssembly SingleInstance
亲们实在看不懂,只能通过比较下有关键字volatile与没有的差异。
可以发现多出来好多 lock addl
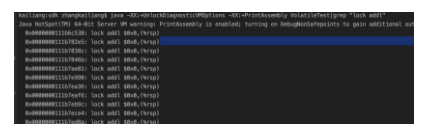
这是个啥?
2.2内存屏障
内存屏障(Memory Barrier)与 内存栅栏(intel称之为 Memory Fence)是同一个概念,不同的叫法。可以通过插入内存屏障指令来禁止特定类型的处理器重排序。
volatile的底层实现是通过插入内存屏障,JMM采用保守策略。如下:
在每一个volatile写操作前面插入一个StoreStore屏障
在每一个volatile写操作后面插入一个StoreLoad屏障
在每一个volatile读操作后面插入一个LoadLoad屏障
在每一个volatile读操作后面插入一个LoadStore屏障
StoreStore屏障可以保证在volatile写之前,其前面的所有普通写操作都已经刷新到主内存中;
StoreLoad屏障的作用是避免volatile写与后面可能有的volatile读/写操作重排序;
LoadLoad屏障用来禁止处理器把上面的volatile读与下面的普通读重排序;
LoadStore屏障用来禁止处理器把上面的volatile读与下面的普通写重排序;
2.3指令重排序
在执行程序时为了提高性能,编译器和处理器常常会对指令做重排序。
指令重排序的目的是为了提高性能,指令重排序仅保证在单线程下不会改变最终的执行结果,但无法保证在多线程下的执行结果。
从java源代码到最终实际执行的指令序列,会分别经历下面三种重排序:

上述的1属于编译器重排序,2和3属于处理器重排序。这些重排序都可能会导致多线程程序出现内存可见性问题。
对于编译器,JMM的编译器重排序规则会禁止特定类型的编译器重排序(不是所有的编译器重排序都要禁止)。
对于处理器重排序,JMM的处理器重排序规则会要求java编译器在生成指令序列时,插入特定类型的内存屏障指令,通过内存屏障指令来禁止特定类型的处理器重排序(不是所有的处理器重排序都要禁止)。
JMM属于语言级的内存模型,它确保在不同的编译器和不同的处理器平台之上,通过禁止特定类型的编译器重排序和处理器重排序,为程序员提供一致的内存可见性保证。
2.4 程序员密切相关的happens-before规则
从JDK5开始,java使用新的JSR -133内存模型(本文除非特别说明,针对的都是JSR- 133内存模型)。JSR-133使用happens-before的概念来阐述操作之间的内存可见性。在JMM中,如果一个操作执行的结果需要对另一个操作可见,那么这两个操作之间必须要存在happens-before关系。这里提到的两个操作既可以是在一个线程之内,也可以是在不同线程之间。
程序顺序规则:
一个线程中的每个操作,happens- before 于该线程中的任意后续操作。
监视器锁规则:
对一个监视器锁的解锁,happens- before 于随后对这个监视器锁的加锁。
volatile变量规则:对一个volatile域的写,happens- before 于任意后续对这个volatile域的读。
传递性:
如果A happens- before B,且B happens- before C,那么A happens- before C。
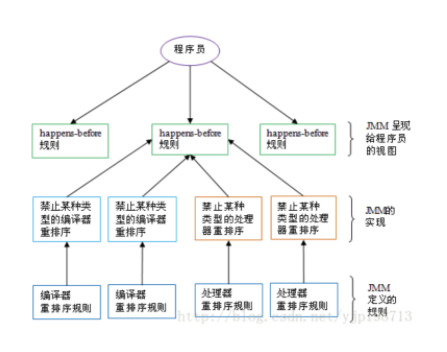
如上图所示,一个happens-before规则通常对应于多个编译器和处理器重排序规则。对于java程序员来说,happens-before规则简单易懂,它避免java程序员为了理解JMM提供的内存可见性保证而去学习复杂的重排序规则以及这些规则的具体实现。
2.5来看一个例子 -- 双重检测的单例
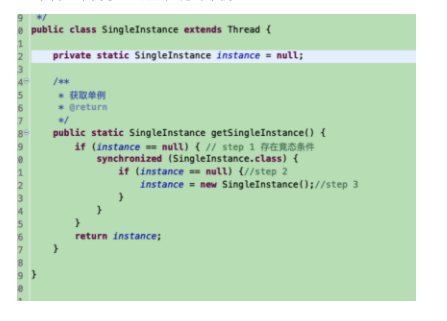
请问这段单例代码有问题吗?
分析:
instance = new TestInstance();可以分解为3行伪代码

假设有线程A 执行到 step 3, 且编译器进行指令重排为Step a-c-b,正好行程A刚执行完Step c,然后线程B执行到 step 1 , 我们来看看会发生什么?
线程B 判断 instance==null 为false ,直接返回 instance; 而此时instance只执行了 Step c. instance = memory //设置instance指向刚分配的地址,内存地址中的对象尚未初始化完成。
要解决这个问题可将代码修改为:
private volatile static SingleInstance instance = null;
三、volatile能保证原子性吗?
看看以下描述:“volatile变量对所有线程是立即可见的,对volatile变量所有的写操作都能立刻反应到其他线程之中,换句话说,volatile变量在各个线程中是一致的,所以基于volatile变量的运算在并发下是安全的”。
这句话的论据部分并没有错,但是其论据并不能得出“基于volatile变量的运算在并发下是安全的”这个结论。
volatile变量在各个线程的工作内存中不存在一致性问题,但是Java里面的运算并非原子操作,并且volatile并不能保证原子性,导致volatile变量的运算在并发下一样是不安全的,我们可以通过一段简单的演示来说明原因,请看下面的例子
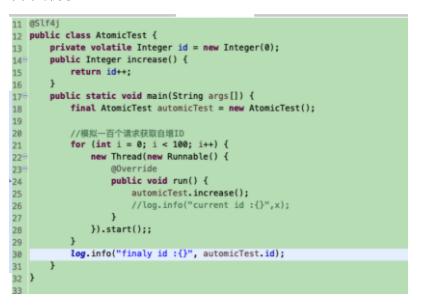
输出结果:
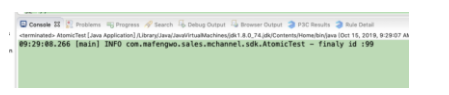
为什么会这样,我们再来分析下:
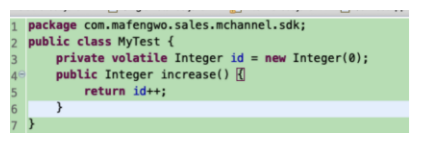
再看看这段代码的字节码:
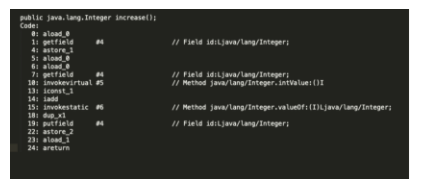
我们将 id++ 简单概括为三个操作:
1.读取变量id的值; -- volatale 保证此处跟主存一致
2.将变量id的值加1;
3.将计算后的值再赋值给变量id的引用。
其中 2、3 不能线程安全.
想要保证原子性,可以使用请同步机制, 以下是采用一种原子操作的数据结构 AtomicInteger.
四、总结
4.1 volatile的使用场景
4.1.1 共享易变状态标记量(如库存售罄标志)
4.1.2双重检测机制实现的单例
4.2主要内容回顾
4.2.1 Java线程的工作内存模型
4.2.2 volatile的作用
volatile修饰的变量不会被指令重排序优化
volatile保证可见性,不保证原子性
4.2.3 volatile原理(禁止指令重排序:先行发生规则与内存屏障)
思考: Java 与 C/C++ 中的volatile 的区别与联系?











