
Big Data technology has been extremely disruptive with open source playing a dominant role in shaping its evolution. While on one hand it has been disruptive, on the other it has led to a complex ecosystem where new frameworks, libraries and tools are being released pretty much every day, creating confusion as technologists struggle and grapple with the deluge.
If you are a Big Data enthusiast or a technologist ramping up (or scratching your head), it is important to spend some serious time deeply understanding the architecture of key systems to appreciate its evolution. Understanding the architectural components and subtleties would also help you choose and apply the appropriate technology for your use case. In my journey over the last few years, some literature has helped me become a better educated data professional. My goal here is to not only share the literature but consequently also use the opportunity to put some sanity into the labyrinth of open source systems.
One caution, most of the reference literature included is hugely skewed towards deep architecture overview (in most cases original research papers) than simply provide you with basic overview. I firmly believe that deep dive will fundamentally help you understand the nuances, though would not provide you with any shortcuts, if you want to get a quick basic overview.
Jumping right in…
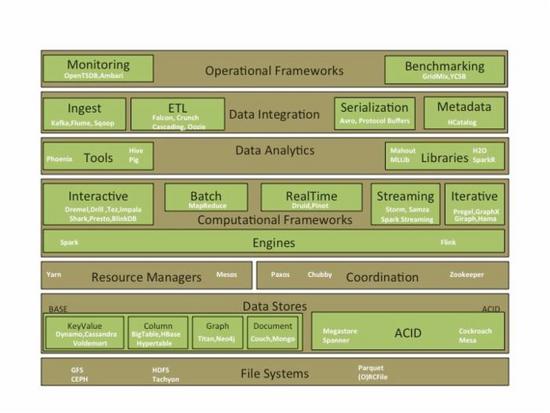
Key architecture layers
File Systems - Distributed file systems which provide storage, fault tolerance, scalability, reliability, and availability.
Data Stores – Evolution of application databases into Polyglot storage with application specific databases instead of one size fits all. Common ones are Key-Value, Document, Column and Graph.
Resource Managers – provide resource management capabilities and support schedulers for high utilization and throughput.
Coordination – systems that manage state, distributed coordination, consensus and lock management.
Computational Frameworks – a lot of work is happening at this layer with highly specialized compute frameworks for Streaming, Interactive, Real Time, Batch and Iterative Graph (BSP) processing. Powering these are complete computation runtimes like BDAS (Spark) & Flink.
Data Analytics –Analytical (consumption) tools and libraries, which support exploratory, descriptive, predictive, statistical analysis and machine learning.
Data Integration – these include not only the orchestration tools for managing pipelines but also metadata management.
Operational Frameworks – these provide scalable frameworks for monitoring & benchmarking.
Architecture Evolution
The modern data architecture is evolving with a goal of reduced latency between data producers and consumers. This consequently is leading to real time and low latency processing, bridging the traditional batch and interactive layers into hybrid architectures like Lambda and Kappa.
Lambda - Established architecture for a typical data pipeline. Mor e details.
Kappa – An alternative architecture which moves the processing upstream to the Stream layer.
SummingBird – a reference model on bridging the online and traditional processing models.
Before you deep dive into the actual layers, here are some general documents which can provide you a great background on NoSQL, Data Warehouse Scale Computing and Distributed Systems.
Data center as a computer – provides a great background on warehouse scale computing.
NOSQL Data Stores – background on a diverse set of key-value, document and column oriented stores.
NoSQL Thesis – great background on distributed systems, first generation NoSQL systems.
Large Scale Data Management - covers the data model, the system architecture and the consistency model, ranging from traditional database vendors to new emerging internet-based enterprises.
Eventual Consistency – background on the different consistency models for distributed systems.
CAP Theorem – a nice background on CAP and its evolution.
There also has been in the past a fierce debate between traditional Parallel DBMS with Map Reduce paradigm of processing. Pro parallel DBMS ( another ) paper(s) was rebutted by the pro MapReduce one. Ironically the Hadoop community from then has come full circle with the introduction of MPI style shared nothing based processing on Hadoop - SQL on Hadoo p.
File Systems
As the focus shifts to low latency processing, there is a shift from traditional disk based storage file systems to an emergence of in memory file systems - which drastically reduces the I/O & disk serialization cost. Tachyon and Spark RDD are examples of that evolution.
Google File System - The seminal work on Distributed File Systems which shaped the Hadoop File System.
Hadoop File System – Historical context/architecture on evolution of HDFS.
Ceph File System – An alternative to HDFS.
Tachyon – An in memory storage system to handle the modern day low latency data processing.
File Systems have also seen an evolution on the file formats and compression techniques. The following references gives you a great background on the merits of row and column formats and the shift towards newer nested column oriented formats which are highly efficient for Big Data processing. Erasure codes are using some innovative techniques to reduce the triplication (3 replicas) schemes without compromising data recoverability and availability.
Column Oriented vs Row-Stores – good overview of data layout, compression and materialization.
RCFile – Hybrid PAX structure which takes the best of both the column and row oriented stores.
Parquet – column oriented format first covered in Google’s Dremel’s paper.
ORCFile – an improved column oriented format used by Hive.
Compression – compression techniques and their comparison on the Hadoop ecosystem.
Erasure Codes – background on erasure codes and techniques; improvement on the default triplication on Hadoop to reduce storage cost.
Data Stores
Broadly, the distributed data stores are classified on ACID & BASE stores depending on the continuum of strong to weak consistency respectively. BASE further is classified into KeyValue, Document, Column and Graph - depending on the underlying schema & supported data structure. While there are multitude of systems and offerings in this space, I have covered few of the more prominent ones. I apologize if I have missed a significant one...
BASE
Key Value Stores
Dynamo – key-value distributed storage system
Cassandra – Inspired by Dynamo; a multi-dimensional key-value/column oriented data store.
Voldemort – another one inspired by Dynamo, developed at LinkedIn.
Column Oriented Stores
BigTable – seminal paper from Google on distributed column oriented data stores.
HBase – while there is no definitive paper , this provides a good overview of the technology.
Hypertable – provides a good overview of the architecture.
Document Oriented Stores
CouchDB – a popular document oriented data store.
MongoDB – a good introduction to MongoDB architecture.
Graph
Neo4j – most popular Graph database.
Titan – open source Graph database under the Apache license.
ACID
I see a lot of evolution happening in the open source community which will try and catch up with what Google has done – 3 out of the prominent papers below are from Google , they have solved the globally distributed consistent data store problem.
Megastore – a highly available distributed consistent database. Uses Bigtable as its storage subsystem.
Spanner – Globally distributed synchronously replicated linearizable database which supports SQL access.
MESA – provides consistency, high availability, reliability, fault tolerance and scalability for large data and query volumes.
CockroachDB – An open source version of Spanner (led by former engineers) in active development.
Resource Managers
While the first generation of Hadoop ecosystem started with monolithic schedulers like YARN, the evolution now is towards hierarchical schedulers (Mesos), that can manage distinct workloads, across different kind of compute workloads, to achieve higher utilization and efficiency.
YARN – The next generation Hadoop compute framework.
Mesos – scheduling between multiple diverse cluster computing frameworks.
These are loosely coupled with schedulers whose primary function is schedule jobs based on scheduling policies/configuration.
Schedulers
Capacity Scheduler - introduction to different features of capacity scheduler.
FairShare Scheduler - introduction to different features of fair scheduler.
Delayed Scheduling - introduction to Delayed Scheduling for FairShare scheduler.
Fair & Capacity schedulers – a survey of Hadoop schedulers.
Coordination
These are systems that are used for coordination and state management across distributed data systems.
Paxos – a simple version of the classical paper; used for distributed systems consensus and coordination.
Chubby – Google’s distributed locking service that implements Paxos.
Zookeeper – open source version inspired from Chubby though is general coordination service than simply a locking service
Computational Frameworks
The execution runtimes provide an environment for running distinct kinds of compute. The most common runtimes are
Spark – its popularity and adoption is challenging the traditional Hadoop ecosystem. Flink – very similar to Spark ecosystem; strength over Spark is in iterative processing.
The frameworks broadly can be classified based on the model and latency of processing
Batch
MapReduce – The seminal paper from Google on MapReduce.
MapReduce Survey – A dated, yet a good paper; survey of Map Reduce frameworks.
Iterative (BSP)
Pregel – Google’s paper on large scale graph processing
Giraph - large-scale distributed Graph processing system modelled around Pregel
GraphX - graph computation framework that unifies graph-parallel and data parallel computation.
Hama - general BSP computing engine on top of Hadoop
Open source graph processing survey of open source systems modelled around Pregel BSP.
Streaming
Stream Processing – A great overview of the distinct real time processing systems
Storm – Real time big data processing system
Samza - stream processing framework from LinkedIn
Spark Streaming – introduced the micro batch architecture bridging the traditional batch and interactive processing.
Interactive
Dremel – Google’s paper on how it processes interactive big data workloads, which laid the groundwork for multiple open source SQL systems on Hadoop.
Impala – MPI style processing on make Hadoop performant for interactive workloads.
Drill – A open source implementation of Dremel.
Shark – provides a good introduction to the data analysis capabilities on the Spark ecosystem.
Shark – another great paper which goes deeper into SQL access.
Dryad – Configuring & executing parallel data pipelines using DAG.
Tez – open source implementation of Dryad using YARN.
BlinkDB - enabling interactive queries over data samples and presenting results annotated with meaningful error bars
RealTime
Druid – a real time OLAP data store. Operationalized time series analytics databases
Pinot – LinkedIn OLAP data store very similar to Druid.
Data Analysis
The analysis tools range from declarative languages like SQL to procedural languages like Pig. Libraries on the other hand are supporting out of the box implementations of the most common data mining and machine learning libraries.
Tools
Pig – Provides a good overview of Pig Latin.
Pig – provide an introduction of how to build data pipelines using Pig.
Hive – provides an introduction of Hive.
Hive – another good paper to understand the motivations behind Hive at Facebook.
Phoenix – SQL on Hbase.
Join Algorithms for Map Reduce – provides a great introduction to different join algorithms on Hadoop.
Join Algorithms for Map Reduce – another great paper on the different join techniques.
Libraires
MLlib – Machine language framework on Spark.
SparkR – Distributed R on Spark framework.
Mahout – Machine learning framework on traditional Map Reduce.
Data Integration
Data integration frameworks provide good mechanisms to ingest and outgest data between Big Data systems. It ranges from orchestration pipelines to metadata framework with support for lifecycle management and governance.
Ingest/Messaging
Flume – a framework for collecting, aggregating and moving large amounts of log data from many different sources to a centralized data store.
Sqoop – a tool to move data between Hadoop and Relational data stores.
Kafka – distributed messaging system for data processing
ETL/Workflow
Crunch – library for writing, testing, and running MapReduce pipelines.
Falcon – data management framework that helps automate movement and processing of Big Data.
Cascading – data manipulation through scripting.
Oozie – a workflow scheduler system to manage Hadoop jobs.
Metadata
HCatalog - a table and storage management layer for Hadoop.
Serialization
ProtocolBuffers – language neutral serialization format popularized by Google. Avro – modeled around Protocol Buffers for the Hadoop ecosystem.
Operational Frameworks
Finally the operational frameworks provide capabilities for metrics, benchmarking and performance optimization to manage workloads.
Monitoring Frameworks
OpenTSDB – a time series metrics systems built on top of HBase.
Ambari - system for collecting, aggregating and serving Hadoop and system metrics
Benchmarking
YCSB – performance evaluation of NoSQL systems.
GridMix – provides benchmark for Hadoop workloads by running a mix of synthetic jobs
Background on big data benchmarking with the key challenges associated.
Summary
I hope that the papers are useful as you embark or strengthen your journey. I am sure there are few hundred more papers that I might have inadvertently missed and a whole bunch of systems that I might be unfamiliar with - apologies in advance as don't mean to offend anyone though happy to be educated....












