
Python编码格式导致的csv读取错误(pandas.read_csv)
本文记录python小白我今天遇到的这两个问题(csv.reader和pandas.csv_read):
- pandas模块“CParserError: Error tokenizing data. C error: Expected 1 fields in line 4, saw 2”错误
- csv模块“line contains NULL byte”错误
今天处理数据时疏忽了,而且还偷懒把数据复制到xlsx保存后,直接修改文件后缀成.csv准备用来读取。之后运行算法要读数据的时候果然问题来了。
import pandas as pd
path = 'water30.csv'
df=pd.read_csv(path)
- 1
- 2
- 3
- 4
注:后两行可写作df=pd.read_csv('water30.csv')。但由于read_csv本身有好多参数(虽然这里不用), 故写成path习惯好些。
这样会报错CParserError: Error tokenizing data. C error: Expected 1 fields in line 4, saw 2
我在网上查了好多种解决办法,由于read_csv的参数很多,所以各有其词,我这里遇到的应该也只是其中一种,久寻无果。直到我看到这里说看了模块_csv.c的代码后,发现文件里不能有 “\0”, 所以csv文件不可以是unicode编码的,可以是ANSI。
针对我直接改后缀名的结果是,点击那个.csv打开时就已经提示我: 
也就是这里改后缀并没有把文件格式弄好。所以我选择“另存为”改选了文件格式为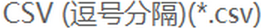 之后,读取就不会报错了。
之后,读取就不会报错了。
注:有个疑问没有解决,就是那个我“直接改后缀得到的那个.csv”我用记事本打开查看了一下,编码就是ANSI啊。那我就不知道为什么报错了……不过问题倒是暂时解决了。
现在读取到的格式为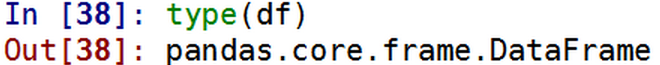 是个结构体。
是个结构体。











