
Redis4.0新增了非常实用的lazy free特性,从根本上解决Big Key(主要指定元素较多集合类型Key)删除的风险。笔者在redis运维中也遇过几次Big Key删除带来可用性和性能故障。
本文分为以下几节说明redis lazy free:
- lazy free的定义
- 我们为什么需要lazy free
- lazy free的使用
- lazy free的监控
- lazy free实现的简单分析
1 lazy free的定义
lazy free可译为惰性删除或延迟释放;当删除键的时候,redis提供异步延时释放key内存的功能,把key释放操作放在bio(Background I/O)单独的子线程处理中,减少删除big key对redis主线程的阻塞。有效地避免删除big key带来的性能和可用性问题。
2 我们为什么需要lazy free
Redis是single-thread程序(除少量的bio任务),当运行一个耗时较大的请求时,会导致所有请求排队等待redis不能响应其他请求,引起性能问题,甚至集群发生故障切换。而redis删除大的集合键时,就属于这类比较耗时的请求。通过测试来看,删除一个100万个元素的集合键,耗时约1000ms左右。以下测试,删除一个100万个字段的hash键,耗时1360ms;处理此DEL请求期间,其他请求完全被阻塞。
删除一个100万字段的hash键
127.0.0.1:6379> HLEN hlazykey
(integer) 1000000
127.0.0.1:6379> del hlazykey
(integer) 1
(1.36s)
127.0.0.1:6379> SLOWLOG get
1) 1) (integer) 0
2) (integer) 1501314385
3) (integer) 1360908
4) 1) "del"
2) "hlazykey"
5) "127.0.0.1:35595"
6) “"
测试估算,可参考;和硬件环境、Redis版本和负载等因素有关
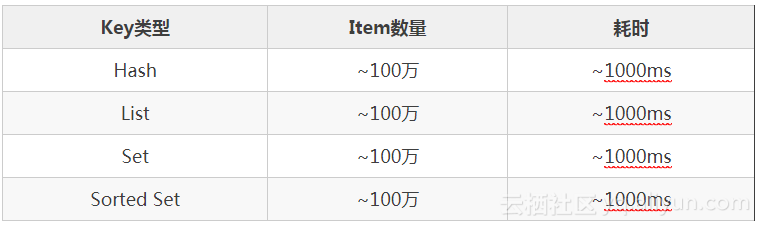
redis4.0有lazy free功能后,这类主动或被动的删除big key时,和一个O(1)指令的耗时一样,亚毫秒级返回; 把真正释放redis元素耗时动作交由bio后台任务执行。在redis4.0前,没有lazy free功能;DBA只能通过取巧的方法,类似scan big key,每次删除100个元素;但在面对“被动”删除键的场景,这种取巧的删除就无能为力。
例如:我们生产Redis Cluster大集群,业务缓慢地写入一个带有TTL的2000多万个字段的Hash键,当这个键过期时,redis开始被动清理它时,导致redis被阻塞20多秒,当前分片主节点因20多秒不能处理请求,并发生主库故障切换。
我有几张阿里云幸运券分享给你,用券购买或者升级阿里云相应产品会有特惠惊喜哦!把想要买的产品的幸运券都领走吧!快下手,马上就要抢光了。
3 lazy free的使用
lazy free的使用分为2类:第一类是与DEL命令对应的主动删除,第二类是过期key删除、maxmemory key驱逐淘汰删除。
主动删除键使用lazy free
UNLINK命令
UNLINK命令是与DEL一样删除key功能的lazy free实现。唯一不同时,UNLINK在删除集合类键时,如果集合键的元素个数大于64个(详细后文),会把真正的内存释放操作,给单独的bio来操作。示例如下:使用UNLINK命令删除一个大键mylist, 它包含200万个元素,但用时只有0.03毫秒
127.0.0.1:7000> LLEN mylist
(integer) 2000000
127.0.0.1:7000> UNLINK mylist
(integer) 1
127.0.0.1:7000> SLOWLOG get
1) 1) (integer) 1
2) (integer) 1505465188
3) (integer) 30
4) 1) "UNLINK"
2) "mylist"
5) "127.0.0.1:17015"
6) ""
注意:DEL命令,还是阻塞的删除操作。
FLUSHALL/FLUSHDB ASYNC
通过对FLUSHALL/FLUSHDB添加ASYNC异步清理选项,redis在清理整个实例或DB时,操作都是异步的。
127.0.0.1:7000> DBSIZE
(integer) 1812295
127.0.0.1:7000> flushall //同步清理实例数据,180万个key耗时1020毫秒
OK
(1.02s)
127.0.0.1:7000> DBSIZE
(integer) 1812637
127.0.0.1:7000> flushall async //异步清理实例数据,180万个key耗时约9毫秒
OK
127.0.0.1:7000> SLOWLOG get
1) 1) (integer) 2996109
2) (integer) 1505465989
3) (integer) 9274 //指令运行耗时9.2毫秒
4) 1) "flushall"
2) "async"
5) "127.0.0.1:20110"
6) ""
被动删除键使用lazy free
lazy free应用于被动删除中,目前有4种场景,每种场景对应一个配置参数; 默认都是关闭。
lazyfree-lazy-eviction no
lazyfree-lazy-expire no
lazyfree-lazy-server-del no
slave-lazy-flush no
注意:从测试来看lazy free回收内存效率还是比较高的; 但在生产环境请结合实际情况,开启被动删除的lazy free 观察redis内存使用情况。
lazyfree-lazy-eviction
针对redis内存使用达到maxmeory,并设置有淘汰策略时;在被动淘汰键时,是否采用lazy free机制;
因为此场景开启lazy free, 可能使用淘汰键的内存释放不及时,导致redis内存超用,超过maxmemory的限制。此场景使用时,请结合业务测试。
lazyfree-lazy-expire
针对设置有TTL的键,达到过期后,被redis清理删除时是否采用lazy free机制;
此场景建议开启,因TTL本身是自适应调整的速度。
lazyfree-lazy-server-del
针对有些指令在处理已存在的键时,会带有一个隐式的DEL键的操作。如rename命令,当目标键已存在,redis会先删除目标键,如果这些目标键是一个big key,那就会引入阻塞删除的性能问题。 此参数设置就是解决这类问题,建议可开启。
slave-lazy-flush
针对slave进行全量数据同步,slave在加载master的RDB文件前,会运行flushall来清理自己的数据场景,
参数设置决定是否采用异常flush机制。如果内存变动不大,建议可开启。可减少全量同步耗时,从而减少主库因输出缓冲区爆涨引起的内存使用增长。
4 lazy free的监控
lazy free能监控的数据指标,只有一个值:lazyfree_pending_objects,表示redis执行lazy free操作,在等待被实际回收内容的键个数。并不能体现单个大键的元素个数或等待lazy free回收的内存大小。
所以此值有一定参考值,可监测redis lazy free的效率或堆积键数量; 比如在flushall async场景下会有少量的堆积。
5 lazy free实现的简单分析
antirez为实现lazy free功能,对很多底层结构和关键函数都做了修改;该小节只介绍lazy free的功能实现逻辑;代码主要在源文件lazyfree.c和bio.c中。
UNLINK命令
unlink命令入口函数unlinkCommand()和del调用相同函数delGenericCommand()进行删除KEY操作,使用lazy标识是否为lazyfree调用。如果是lazyfree,则调用dbAsyncDelete()函数。
但并非每次unlink命令就一定启用lazy free,redis会先判断释放KEY的代价(cost),当cost大于LAZYFREE_THRESHOLD才进行lazy free.
释放key代价计算函数lazyfreeGetFreeEffort(),集合类型键,且满足对应编码,cost就是集合键的元数个数,否则cost就是1.
举例:
1一个包含100元素的list key, 它的free cost就是100
2 一个512MB的string key, 它的free cost是1
所以可以看出,redis的lazy free的cost计算主要时间复杂度相关。
lazyfreeGetFreeEffort()函数代码
size_t lazyfreeGetFreeEffort(robj *obj) {
if (obj->type == OBJ_LIST) {
quicklist *ql = obj->ptr;
return ql->len;
} else if (obj->type == OBJ_SET && obj->encoding == OBJ_ENCODING_HT) {
dict *ht = obj->ptr;
return dictSize(ht);
} else if (obj->type == OBJ_ZSET && obj->encoding == OBJ_ENCODING_SKIPLIST){
zset *zs = obj->ptr;
return zs->zsl->length;
} else if (obj->type == OBJ_HASH && obj->encoding == OBJ_ENCODING_HT) {
dict *ht = obj->ptr;
return dictSize(ht);
} else {
return 1; /* Everything else is a single allocation. */
}
}
dbAsyncDelete()函数的部分代码
#define LAZYFREE_THRESHOLD 64 //根据FREE一个key的cost是否大于64,用于判断是否进行lazy free调用
int dbAsyncDelete(redisDb *db, robj *key) {
/* Deleting an entry from the expires dict will not free the sds of
* the key, because it is shared with the main dictionary. */
if (dictSize(db->expires) > 0) dictDelete(db->expires,key->ptr); //从expires中直接删除key
dictEntry *de = dictUnlink(db->dict,key->ptr); //进行unlink处理,但不进行实际free操作
if (de) {
robj *val = dictGetVal(de);
size_t free_effort = lazyfreeGetFreeEffort(val); //评估free当前key的代价
/* If releasing the object is too much work, let's put it into the
* lazy free list. */
if (free_effort > LAZYFREE_THRESHOLD) { //如果free当前key cost>64, 则把它放在lazy free的list, 使用bio子线程进行实际free操作,不通过主线程运行
atomicIncr(lazyfree_objects,1); //待处理的lazyfree对象个数加1,通过info命令可查看
bioCreateBackgroundJob(BIO_LAZY_FREE,val,NULL,NULL);
dictSetVal(db->dict,de,NULL);
}
}
}
在bio中实际调用lazyfreeFreeObjectFromBioThread()函数释放key
void lazyfreeFreeObjectFromBioThread(robj *o) {
decrRefCount(o); //更新对应引用,根据不同类型,调用不同的free函数
atomicDecr(lazyfree_objects,1); //完成key的free,更新待处理lazyfree的键个数
}
flushall/flushdb async命令
当flushall/flushdb带上async,函数emptyDb()调用emptyDbAsync()来进行整个实例或DB的lazy free逻辑处理。
emptyDbAsync处理逻辑如下:
/* Empty a Redis DB asynchronously. What the function does actually is to
* create a new empty set of hash tables and scheduling the old ones for
* lazy freeing. */
void emptyDbAsync(redisDb *db) {
dict *oldht1 = db->dict, *oldht2 = db->expires; //把db的两个hash tables暂存起来
db->dict = dictCreate(&dbDictType,NULL); //为db创建两个空的hash tables
db->expires = dictCreate(&keyptrDictType,NULL);
atomicIncr(lazyfree_objects,dictSize(oldht1)); //更新待处理lazyfree的键个数,加上db的key个数
bioCreateBackgroundJob(BIO_LAZY_FREE,NULL,oldht1,oldht2);//加入到bio list
}
在bio中实际调用lazyfreeFreeDatabaseFromBioThread函数释放db
void lazyfreeFreeDatabaseFromBioThread(dict *ht1, dict *ht2) {
size_t numkeys = dictSize(ht1);
dictRelease(ht1);
dictRelease(ht2);
atomicDecr(lazyfree_objects,numkeys);//完成整个DB的free,更新待处理lazyfree的键个数
}
被动删除键使用lazy free
被动删除4个场景,redis在每个场景调用时,都会判断对应的参数是否开启,如果参数开启,则调用以上对应的lazy free函数处理逻辑实现。
总结
因为Redis是单个主线程处理,antirez一直强调”Lazy Redis is better Redis”。而lazy free的本质就是把某些cost较高的(主要时间复制度,占用主线程cpu时间片)较高删除操作,从redis主线程剥离,让bio子线程来处理,极大地减少主线阻塞时间。从而减少删除导致性能和稳定性问题。











