
远程过程调用(RPC)
(使用 pika 0.9.8 Python客户端)
在第二篇教程中,我们学习了如何使用_工作队列_在多个workers之间分发耗时的任务。
但是假使我们需要在一台远程的计算机上执行一个函数并等待结果呢?那就将是一件不同的事情了。这种模式通常被称为_远程过程调用_或_RPC_。
在这份教程中,我们将使用RabbitMQ来构建一个RPC系统:一个客户端和一个可伸缩的RPC服务器。由于我们没有任何耗时的任务值得分发,我们将创建一个虚拟的RPC服务来返回Fibonacci数。
客户端接口
为了描述如何使用一个RPC服务,我们将创建一个简单的客户端类。它将暴露一个名为call的方法,而该方法将发送一个RPC请求,并阻塞直到接到回答。
fibonacci_rpc = FibonacciRpcClient()
result = fibonacci_rpc.call(4)
print "fib(4) is %r" % (result,)
一点关于RPC的说明
尽管RPC是计算领域一个相当常见的模式,但它常常受到批评。问题来自于程序员没有意识到一个函数调用是否是本地的时或如果它是一个慢RPC。困扰诸如导致了一个不可预知的系统并增加了不必须的调试复杂性。不仅没能简化软件,误用RPC还可能导致不可维护的意大利面条式的代码。
牢记,考虑下面的建议:
确保一个调用是本地的还是远程的看起来很明显。
为你的系统写文档。使得组件之间的以来清晰明了。
处理错误情况。客户端在RPC服务器挂掉或执行了很长时间应该如何处理?
有疑问时避免使用RPC。如果可以,你应该使用一个异步的管道 - 而不是RPC - 如阻塞,结果被异步地推进下一个计算步骤。
回调队列
通常基于RabbitMQ执行RPC很简单。一个客户端发送一个请求消息,而一个服务器以一个响应消息来应答。为了接收一个响应,客户端需要在请求中发送一个'callback'队列地址。让我们來试一下:
result = channel.queue_declare(exclusive=True)
callback_queue = result.method.queue
channel.basic_publish(exchange='',
routing_key='rpc_queue',
properties=pika.BasicProperties(
reply_to = callback_queue,
),
body=request)
# ... and some code to read a response message from the callback_queue ...
消息属性
AMQP协议预定义了伴随一个消息一起发送的14种属性。大多数属性很少被用到,除了如下的这些:
delivery_mode: 标记一个消息为persistent(以值2)或transient(其它任何值)。你可能还记得第二篇教程中的这个属性。
content_type: 用来描述编码的mime-type。比如对于常用的JSON编码,把属性设为application/json就是一个很好的实践。
reply_to: 常被用于命名一个callback队列。
correlation_id: 关联RPC响应和请求时很有用。
关联 id
在上面出现的方法中我们为每个RPC请求创建了一个callback队列。那相当没有效率,幸运地是有一个更好的方式 - 让我们为每个客户端创建一个单独的callback 队列。
那产生了一个新的问题,在那个队列中接收的响应到底属于哪个请求不是很清楚。那正是correlation_id属性应用的场合。我们将为每个请求设置一个唯一的值。稍后,当我们从callback队列中接收一条消息时,我们将查看这个属性,基于它我们将能够把一个响应与一个请求匹配起来。如果我们看到一个未知的correlation_id值,我们可以安全地丢弃消息 - 它不属于我们的请求。
你可能会问,我们为什么要忽略callback队列中的未知消息,而不是以一个error而failing?那是由于可能会在服务器端产生一个race condition。尽管可能性不大,RPC服务器可能在将答案发送给我们之后,但在为请求发送一个确认消息之前就死掉。如果发生了那种事,则重启后的RPC服务器将再次处理请求。那就是为什么在客户端上,我们必须优雅地处理重复的响应,而RPC应该是理想地幂等的。
总结
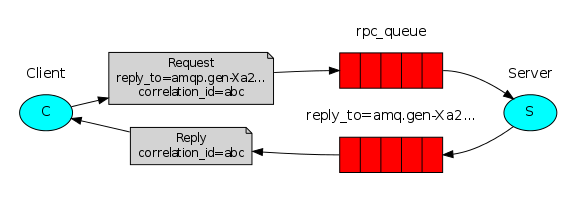
我们的RPC将像这样来工作:
当客户端起来时,它创建一个匿名的exclusive callback队列。
对于一个RPC请求,客户端发送一个消息,带有两个属性:reply_to,被设置为callback 队列,和correlation_id,被设置为给每个请求创建的一个唯一的值。
请求被发送到一个rpc_queue队列。
RPC worker(aka: server) 在那个队列上等待。当一个请求出现时,它来执行工作,并发送一条带有结果的消息给客户端,使用来自于reply_to字段的队列。
客户端在callback队列上等待数据。当一条消息出现时,它检查correlation_id属性。如果它与请求的那个匹配,它将把响应返回给应用。
完整代码
rpc_server.py的代码:
#!/usr/bin/env python
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='rpc_queue')
def fib(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fib(n-1) + fib(n-2)
def on_request(ch, method, props, body):
n = int(body)
print " [.] fib(%s)" % (n,)
response = fib(n)
ch.basic_publish(exchange='',
routing_key=props.reply_to,
properties=pika.BasicProperties(correlation_id = \
props.correlation_id),
body=str(response))
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_qos(prefetch_count=1)
channel.basic_consume(on_request, queue='rpc_queue')
print " [x] Awaiting RPC requests"
channel.start_consuming()
服务器端的代码相当直接:
(4) 像通常那样,一开始我们就建立连接并声明队列。
(11) 我们声明了我们的fibonacci函数。它假设输入都是有效的正数。(不要期待在输入大数时这个函数仍能工作,它可能是最慢的递归实现了)。
(19) 我们为basic_consume声明了一个callback,RPC服务器的核心。当接到消息时执行它。它完成工作并发回响应。
(32) 我们可能想要运行多个服务器进程。为了在多个服务器之间平衡负载,我们需要设置prefetch_count setting。
rpc_client.py的代码:
#!/usr/bin/env python
import pika
import uuid
class FibonacciRpcClient(object):
def __init__(self):
self.connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
self.channel = self.connection.channel()
result = self.channel.queue_declare(exclusive=True)
self.callback_queue = result.method.queue
self.channel.basic_consume(self.on_response, no_ack=True,
queue=self.callback_queue)
def on_response(self, ch, method, props, body):
if self.corr_id == props.correlation_id:
self.response = body
def call(self, n):
self.response = None
self.corr_id = str(uuid.uuid4())
self.channel.basic_publish(exchange='',
routing_key='rpc_queue',
properties=pika.BasicProperties(
reply_to = self.callback_queue,
correlation_id = self.corr_id,
),
body=str(n))
while self.response is None:
self.connection.process_data_events()
return int(self.response)
fibonacci_rpc = FibonacciRpcClient()
print " [x] Requesting fib(30)"
response = fibonacci_rpc.call(30)
print " [.] Got %r" % (response,)
客户端代码要稍微复杂一点:
(7) 我们建立一个连接,channel并为回复声明一个exclusive 'callback'队列。
(16) 我们订阅'callback'队列,以便于我们能够收到RPC响应。
(18) 每次响应,'on_response'回调都会被执行,来做一点非常简单的工作,对于每一个响应消息,它都检查correlation_id是否是我们在寻找的那个。如果是,则把响应保存进self.response,然后打破consuming循环。
(23) 接下来,我们定义了我们的主call方法 - 它执行实际的RPC请求。
(24) 在这个方法中,我们首先要产生一个唯一correlation_id数,并保存它 - 'on_response'回调函数将使用这个值来捕获适当的响应。
(25) 下一步,我们发布请求消息,带有两个属性:reply_to和correlation_id。
(32) 此时我们可以坐下来休息一下,并等待适当的响应到达。
(33) 最后我们将响应返回给用户。
我们的RPC服务现在准备好了。我们可以启动服务器:
$ python rpc_server.py
[x] Awaiting RPC requests
要请求一个Fibonacci数,则执行客户端:
$ python rpc_client.py
[x] Requesting fib(30)
当前的设计不是一个RPC服务仅有的可能的实现,但它有一些重要的优势:
如果RPC服务器很慢,你可以通过运行另一个来扩展。试着在一个新的终端中运行第二个rpc_server.py。
在客户端,RPC请求发送和接收只是一个消息。不需要异步地调用诸如queue_declare之类的。由此对于一个单独的RPC请求,RPC客户端只需要一个网络来回。
我们的代码仍然是过分简化了的,而没有去解决更复杂(但重要)的问题,比如:
如果没有服务器在运行的话,那么客户但应该如何反应?
一个客户端是否应该有一些RPC的超时机制?
如果服务器失灵并抛出了一个异常,那它是否应该被转发给客户端呢?
在处理消息之前,对于进入的无效消息做防护(比如检查边界等)。
此种方式实现的RPC,是否可以应对,同一个客户端同时发出多个RPC请求的情况?
(rpc_client.py和rpc_server.py 的完整代码)。
Done。
原文地址。











