目录
- MyBatis的实现逻辑
- MyBatis的缓存实现逻辑
- #{} 和 ${} 的区别是什么?
- MyBatis中自定义标签的执行原理
- 简述Mapper接口的工作原理
- 在Spring中Mapper接口是如何被注入的?
- 在Mapper接口中是否可以有重载方法?
- 当实体类中的属性名和表中的字段名不一样 ,怎么办?
- 如何获取自动生成的键值?
- Mybatis有哪些Executor执行器?
- MyBatis的延迟加载原理
- MyBatis的插件运行原理
- Mybatis是如何进行分页的?
- Mybatis如何处理include标签的?
- MyBatis与Hibernate有哪些不同?
- JDBC编程有哪些不足之处,MyBatis是如何解决这些问题的?
- Mybatis比IBatis比较大的几个改进是什么?
MyBatis的实现逻辑
- 在 MyBatis 的初始化过程中,会生成一个 Configuration 全局配置对象,里面包含了所有初始化过程中生成对象
- 根据 Configuration 创建一个 SqlSessionFactory 对象,用于创建 SqlSession “会话”
- 通过 SqlSession 可以获取到 Mapper 接口对应的动态代理对象,去执行数据库的相关操作
- 动态代理对象执行数据库的操作,由 SqlSession 执行相应的方法,在他的内部调用 Executor 执行器去执行数据库的相关操作
- 在 Executor 执行器中,会进行相应的处理,将数据库执行结果返回
MyBatis的缓存实现逻辑
MyBatis 提供了一级缓存和二级缓存
在 MyBatis 地开启一个 SqlSession 会话时,都会创建一个 Executor 执行器对象
- 一级缓存在 Executor 执行器(SimpleExecutor)中有一个 Cache 对象中,默认就是一个 HashMap 存储缓存数据,执行数据库查询操作前,如果在一级缓存中有对应的缓存数据,则直接返回,不会去访问数据库默认的缓存区域为SESSION,表示开启一级缓存,可以设置为STATEMENT,执行完查询后会清空一级缓存,所有的数据库更新操作也会清空一级缓存缺陷:在多个 SqlSession 会话时,可能导致数据的不一致性,某一个 SqlSession 更新了数据而其他 SqlSession 无法获取到更新后的数据,出现数据不一致性,这种情况是不允许出现了,所以我们通常选择“关闭”一级缓存
- 二级缓存在 Executor 执行器(CachingExecutor)中有一个 TransactionalCacheManager 对象中,可以在一定程度上解决的一级缓存中多个 SqlSession 会话可能会导致数据不一致的问题,就是将一个 XML 映射文件中定义的缓存对象放在全局对象中,对于同一个 Mapper 接口都是使用这个 Cache 对象,不管哪个 SqlSession 都是使用该 Cache 对象执行数据库查询操作前,如果在二级缓存中有对应的缓存数据,则直接返回,没有的话则去一级缓存中获取,如果有对应的缓存数据,则直接返回,不会去访问数据库默认全局开启,需要在每个 XML 映射文件中定义缺陷:对于不同的 XML 映射文件,如果某个的 XML 映射文件修改了相应的数据,其他的 XML 映射文件获取到的缓存数据就可能不是最新的,也出现了脏读的问题,当然你可以所有的 XML 映射文件都通过
来使用同一个 Cache 对象,不过这样太局限了,且缓存的数据仅仅是保存在了本地内存中,对于当前高并发的环境下是无法满足要求的,所以我们通常不使用MyBatis的缓存
所以对于 MyBatis 中的缓存,我认为是存在一定的缺陷,无法在正式的生产环境使用,如果需要使用缓存,可以参考我的另一篇文档《JetCache源码分析》
#{} 和 ${} 的区别是什么?
两者在 MyBatis 中都可以作为 SQL 的参数占位符,在处理方式上不同
- #{}:在解析 SQL 的时候会将其替换成 ? 占位符,然后通过 JDBC 的 PreparedStatement 对象添加参数值,这里会进行预编译处理,可以有效地防止 SQL 注入,提高系统的安全性
- ${}:在 MyBatis 中带有该占位符的 SQL 片段会被解析成动态 SQL 语句,根据入参直接替换掉这个值,然后执行数据库相关操作,存在 SQL注入 的安全性问题
MyBatis中自定义标签的执行原理
MyBatis 提供了以下几种动态 SQL 的标签:
在 MyBatis 的初始化过程中的解析 SQL 过程中,会将定义的一个 SQL 解析成一个个的 SqlNode 对象,当需要执行数据库查询前,需要根据入参对这些 SqlNode 对象进行解析,使用OGNL表达式计算出结果,然后根据结果拼接对应的 SQL 片段,以此完成动态 SQL 的功能
如何使用可以参考MyBatis官方文档
简述Mapper接口的工作原理
在 MyBatis 的初始化过程中,每个一个 XML 映射文件中的、
同一个 Mapper 接口中为什么不能定义重载方法?
因为 Mapper 接口中的方法是通过 接口名称+'.'+方法名 去找到对应的 MappedStatement 对象,如果方法名相同,则对应的 MappedStatement 对象就是同一个,就存在问题了,所以同一个 Mapper 接口不能定义重载的方法
每个 Mapper 接口都会创建一个动态代理对象(JDK 动态代理),代理类会拦截接口的方法,找到对应的 MappedStatement 对象,然后执行数据库相关操作
执行逻辑如下:
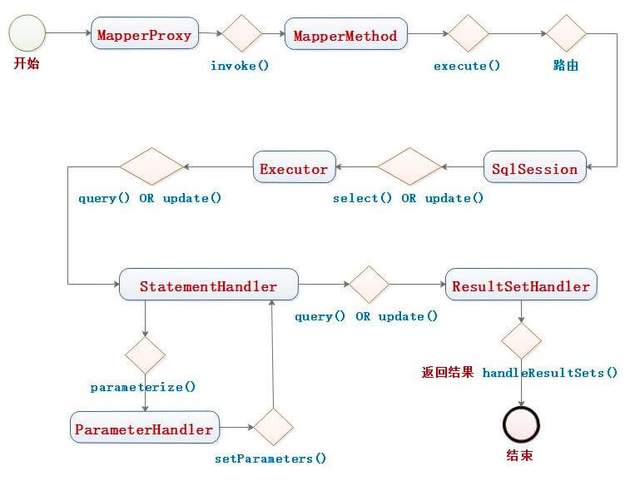
其中 MapperProxy 为 Mapper 接口的动态代理对象的代理类
在Spring中Mapper接口是如何被注入的?
通过 SqlSession 的 getMapper(Class
在 MyBatis 的 MyBatis-Spring 集成 Spring 子项目中,通过实现 Spring 的 BeanDefinitionRegistryPostProcessor 接口,实现它的 postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry) 方法,也就是在 Spring 完成 BeanDefinition 的初始化工作后,会将 Mapper 接口也解析成 BeanDefinition 对象注册到 registry 注册表中,并且会修改其 beanClass 为 MapperFactoryBean 类型,还添加了一个入参为 Mapper 接口的 Class 对象的名称
这样 Mapper 接口会对应一个 MapperFactoryBean 对象,由于这个对象实现了 FactoryBean 接口,实现它的 getObject() 方法,该方法会通过 SqlSession 的 getMapper(Class
在Mapper接口中是否可以有重载方法?
不可以,参考Mapper接口的工作原理这个问题
当实体类中的属性名和表中的字段名不一样 ,怎么办?
- 通过 AS 关键字为字段名设置一个别名与属性名对应
- 通过
来映射字段名和实体类属性名的一一对应的关系,通过配置 property 和 column 属性,如下:

3.是第一种的特殊情况。大多数场景下,数据库字段名和实体类中的属性名差,主要是前者为下划线风格,后者为驼峰风格。在这种情况下,可以开启 MyBatis 的mapUnderscoreToCamelCase配置,实现自动的下划线转驼峰的功能,如下:

如何获取自动生成的键值?
不同的数据库,获取自动生成的(主)键值的方式是不同的
MySQL 有两种方式获取自动生成的键值,如下:
- 在
标签中添加useGeneratedKeys="true"等属性

3.在

Oracle 也有两种方式,序列和触发器,基于序列,根据

Mybatis有哪些Executor执行器?
- SimpleExecutor(默认):每执行一次数据库的操作,就创建一个 Statement 对象,用完立刻关闭 Statement 对象。
- ReuseExecutor:执行数据库的操作,以 SQL 作为 key 查找缓存的 Statement 对象,存在就使用,不存在就创建;用完后,不关闭 Statement 对象,而是放置于缓存 Map<String, Statement> 内,供下一次使用,就是重复使用 Statement 对象
- BatchExecutor:执行数据库更新操作(没有查询操作,因为 JDBC 批处理不支持查询操作),将所有 SQL 都添加到批处理中(通过 addBatch 方法),等待统一执行(使用 executeBatch 方法)。它缓存了多个 Statement 对象,每个 Statement 对象都是调用 addBatch 方法完毕后,等待一次执行 executeBatch 批处理。实际上,整个过程与 JDBC 批处理是相同。
- CachingExecutor:在上述的三个执行器之上,增加二级缓存的功能
MyBatis的延迟加载原理
MyBatis 获取到查询结果需要进行结果集映射,也就是将 JDBC 返回的结果集转换成我们需要的 Java 对象
在映射的过程中,如果存在嵌套子查询且需要延迟加载,则会为该返回结果的实例对象创建一个动态代理对象(Javassist),也就是说我们拿到的返回结果实际上是一个动态代理对象
这个动态代理对象中包含一个 ResultLoaderMap 对象,保存了需要延迟加载的属性和嵌套子查询的映射关系
当你调用了需要延迟加载的属性的 getter 方法时,会执行嵌套子查询,将结果设置到该对象中,然后将该延迟加载的属性从 ResultLoaderMap 中移除
- 如果你调用了该对象equals、clone、hashCode、toString某个方法(默认),会触发所有的延迟加载,然后全部移除
- 如果你调用了延迟加载的属性的 setter 方法,也会将将延迟加载的属性从 ResultLoaderMap 中移除
MyBatis的插件运行原理
MyBatis 的插件机制仅针对 ParameterHandler、ResultSetHandler、StatementHandler、Executor 这 4 种接口中的方法进行增强处理
Mybatis 使用 JDK 的动态代理,为需要拦截的接口生成代理对象以实现接口方法拦截功能,每当执行这 4 种接口对象的方法时,就会进入拦截方法,具体就是 InvocationHandler 的 #invoke(...)方法。当然,只会拦截那些你指定需要拦截的方法
为什么仅支持这 4 种接口呢?
因为 MyBatis 仅在创建上述接口对象后,将所有的插件应用在该对象上面,也就是为该对象创建一个动态代理对象,然后返回
如何编写一个 MyBatis 插件?
让插件类实现 org.apache.ibatis.plugin.Interceptor 接口,还需要通过注解标注该插件的拦截点,然后在 MyBatis 的配置文件中添加的插件,例如:
@Intercepts({
@Signature(
type = Executor.class,
method = "query",
args = {MappedStatement.class, Object.class, RowBounds.class, ResultHandler.class}
)
})
public class ExamplePlugin implements Interceptor {
// Executor的查询方法:
// public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler)
@Override
public Object intercept(Invocation invocation) throws Throwable {
Object[] args = invocation.getArgs();
RowBounds rowBounds = (RowBounds) args[2];
if (rowBounds == RowBounds.DEFAULT) { // 无需分页
return invocation.proceed();
}
/*
* 将query方法的 RowBounds 入参设置为空对象
* 也就是关闭 MyBatis 内部实现的分页(逻辑分页,在拿到查询结果后再进行分页的,而不是物理分页)
*/
args[2] = RowBounds.DEFAULT;
MappedStatement mappedStatement = (MappedStatement) args[0];
BoundSql boundSql = mappedStatement.getBoundSql(args[1]);
// 获取 SQL 语句,拼接 limit 语句
String sql = boundSql.getSql();
String limit = String.format("LIMIT %d,%d", rowBounds.getOffset(), rowBounds.getLimit());
sql = sql + " " + limit;
// 创建一个 StaticSqlSource 对象
SqlSource sqlSource = new StaticSqlSource(mappedStatement.getConfiguration(), sql, boundSql.getParameterMappings());
// 通过反射获取并设置 MappedStatement 的 sqlSource 字段
Field field = MappedStatement.class.getDeclaredField("sqlSource");
field.setAccessible(true);
field.set(mappedStatement, sqlSource);
// 执行被拦截方法
return invocation.proceed();
}
@Override
public Object plugin(Object target) {
// default impl
return Plugin.wrap(target, this);
}
@Override
public void setProperties(Properties properties) {
// default nop
}
}
Mybatis是如何进行分页的?
Mybatis 使用 RowBounds 对象进行分页,它是针对 ResultSet 结果集执行的内存分页,而非数据库分页
所以,实际场景下,不适合直接使用 MyBatis 原有的 RowBounds 对象进行分页。而是使用如下两种方案:
- 在 SQL 内直接书写带有数据库分页的参数来完成数据库分页功能
- 也可以使用分页插件来完成数据库分页。
这两者都是基于数据库分页,差别在于前者是工程师手动编写分页条件,后者是插件自动添加分页条件。
分页插件的基本原理是使用 Mybatis 提供的插件接口,实现自定义分页插件。在插件的拦截方法内,拦截待执行的 SQL ,然后重写 SQL ,根据 dialect 方言,添加对应的物理分页语句和物理分页参数。
举例:SELECT * FROM student ,拦截 SQL 后重写为:select * FROM student LIMI 0,10
目前市面上目前使用比较广泛的 MyBatis 分页插件有:
- Mybatis-PageHelper
- MyBatis-Plus
Mybatis如何处理include标签的?
例如:如果 A 标签通过 include 引用了 B 标签的内容,请问,B 标签能否定义在 A 标签的后面,还是说必须定义在A标签的前面
虽然 Mybatis 解析 XML 映射文件是按照顺序解析的。但是,被引用的 B 标签依然可以定义在同一个 XML 映射文件的任何地方,Mybatis 都可以正确识别。也就是说,无需按照顺序,进行定义。
原理是,Mybatis 解析 A 标签,发现 A 标签引用了 B 标签,但是 B 标签尚未解析到,尚不存在,此时,Mybatis 会将 A 标签标记为未解析状态。然后,继续解析余下的标签,包含 B 标签,待所有标签解析完毕,Mybatis 会重新解析那些被标记为未解析的标签,此时再解析A标签时,B 标签已经存在,A 标签也就可以正常解析完成了。
MyBatis与Hibernate有哪些不同?
Mybatis 和 Hibernate 不同,它不完全是一个 ORM 框架,因为MyBatis 需要程序员自己编写 SQL 语句。不过 MyBatis 可以通过 XML 或注解方式灵活配置要运行的 SQL 语句,并将 Java 对象和 SQL 语句映射生成最终执行的 SQL ,最后将 SQL 执行的结果在映射生成 Java 对象。
Mybatis 学习门槛低,简单易学,程序员直接编写原生态 SQL ,可严格控制 SQL 执行性能,灵活度高。但是灵活的前提是 MyBatis 无法做到数据库无关性,如果需要实现支持多种数据库的软件则需要自定义多套 SQL 映射文件,工作量大。
Hibernate 对象/关系映射能力强,数据库无关性好。如果用 Hibernate 开发可以节省很多代码,提高效率。但是 Hibernate 的缺点是学习门槛高,要精通门槛更高,而且怎么设计 O/R 映射,在性能和对象模型之间如何权衡,以及怎样用好 Hibernate 需要具有很强的经验和能力才行。
总之,按照用户的需求在有限的资源环境下只要能做出维护性、扩展性良好的软件架构都是好架构,所以框架只有适合才是最好。简单总结如下:
- Hibernate 属于全自动 ORM 映射工具,使用 Hibernate 查询关联对象或者关联集合对象时,可以根据对象关系模型直接获取。
- Mybatis 属于半自动 ORM 映射工具,在查询关联对象或关联集合对象时,需要手动编写 SQL 来完成。
当然,实际上,MyBatis 也可以搭配自动生成代码的工具,提升开发效率,还可以使用 MyBatis-Plus 框架,已经内置常用的 SQL 操作,也是非常不错的。
JDBC编程有哪些不足之处,MyBatis是如何解决这些问题的?
问题一:SQL 语句写在代码中造成代码不易维护,且代码会比较混乱。
解决方式:将 SQL 语句配置在 Mapper XML 文件中,与 Java 代码分离。
问题二:根据参数不同,拼接不同的 SQL 语句非常麻烦。例如 SQL 语句的 WHERE 条件不一定,可能多也可能少,占位符需要和参数一一对应。
解决方式:MyBatis 提供
问题三,对结果集解析麻烦,SQL 变化可能导致解析代码变化,且解析前需要遍历。
解决方式:Mybatis 自动将 SQL 执行结果映射成 Java 对象。
Mybatis比IBatis比较大的几个改进是什么?
这是一个选择性了解的问题,因为可能现在很多面试官,都没用过 IBatis 框架
- 有接口绑定,包括注解绑定 SQL 和 XML 绑定 SQL 。
- 动态 SQL 由原来的节点配置变成 OGNL 表达式。
- 在一对一或一对多的时候,引进了
标签,在一对多的时候,引入了 标签,不过都是在 里面配置
原文链接:https://www.cnblogs.com/lifullmoon/p/14014648.html
同时想要领取更多面试题的朋友们只需要加小编vx:mxzFAFAFA即可免费领取!!!