
数据结构是计算机存储,组织数据的方式。数据结构是指相互之间存在一种或多种特定关系的数据元素的集合。通常情况下,精心选择的数据结构可以带来更高的运行或存储效率。数据结构往往同高效的检索算法和索引技术有关
java中常见的几种数据结构(也是初级工程师常见面试题)主要是一些常见的容器,它们主要来自于Collection和Map这2个集合;以下是2个集合的总体框架
(1)Collection接口图

(2)map接口图
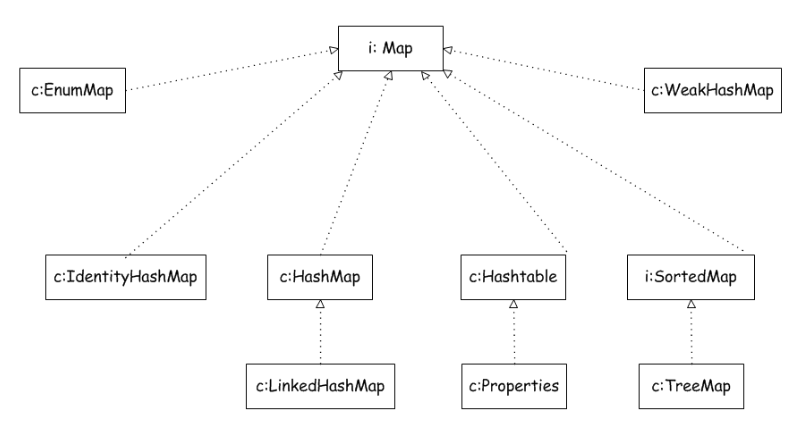
上述2个图片分别来自于
http://www.cnblogs.com/nayitian/p/3266090.html
https://www.cnblogs.com/nayitian/p/3267110.html
下面我将每一个接口或类进行详细介绍,其中他们所拥有的方法就不介绍了,可以自行查API,另外,很多方法也不会用到,常见的方法就那么几个。
1.Collction:
Collection接口继承自超级接口Iterator,是Collection _层次结构_中的根接口。Collection表示一组对象,这些对象也被称为Collection的元素。一些Collection允许有重复的元素(例如List),但是另一些则不允许有重复的元素,即可为无序的(如Set)。JDK不提供此接口的任何直接实现---它会提供更为具体的子接口(如Set和List),这从上面的UML也可以看出来。此接口用来传递Collection,并在需要最大普遍性的地方操作这些Collection。其实现类的底层是由数组或者链表组成,数组是通过首地址+(元素长度*下标),即通过下标查询的,因此查询速度快,而增删慢(在增删的时候,数组需要整体的移动,所以慢);链表不维护序号,即链表不存在下标的概念,所以查询很慢(通过地址查询的),而增删快(直接通过地址删掉某一个元素,其它元素不需要移动)
数组:查询快,增删慢;链表:查询慢,增删快
1.1.List:有序,可重复
ArrayList :底层是数组结构,线程不安全。查询快,增删慢
LinkedList :底层是链表结构,线程不安全。查询慢,增删快
Vector:底层是数组结构,是线程安全的,所以效率很低,已经被ArrayList取代
1.2.Set :无序,不可重复
HashSet类 及其实现类LinkedHashSet:底层是使用了哈希表来支持的,特点: 存取速度快,线程不安全,集合元素允许为NULL
SortedSet接口及其实现类TreeSet:如果元素具备自然顺序 的特性,那么就按照元素自然顺序的特性进行排序存储。
1.3.EnumSet
EnumSet类是专为枚举类设计的集合类,EnumSet中的所有元素都必须是指定枚举类型的枚举值
2.Map
Map用于保存具有映射关系的数据,因此Map集合里保存着两组值,一组值用于保存Map里的key,另外一组用于保存Map里的value,key和value都是可以任意引用类型的数据。Map的key不允许重复,即同一个Map对象的任何两个key通过equals方法比较总是返回false. 给key-value起个名字:Entry,表示一个键值对,对应Map的一个实体;把Entry放到集合set中就是一个Map 如果把Map所有value放在一起来看,元素与元素之间可以重复,每个元素可以根据索引来查找,相当于list集合,只是Map中的索引不再使用整数值,而是以另外一个对象作为索引。如果需要从List集合中取出元素,需要提供该元素的数字索引。 如果需要从Map中取出元素,需要提供该元素的key索引,因此,Map也被称为字典。
常见的实现类:
2.1.HashMap:
采用哈希表算法, 此时Map中的key不会保证添加的先后顺序,key也不允许重复.key判断重复的标准是: key1和key2是否equals为true,并且与hashCode相等.其中实现类LinkedHashMap采用了链表和哈希表算法
2.2.TreeMap:
sortedMap接口的实现类,采用红黑树算法,此时Map中的key会按照自然顺序或定制排序进行排序,,key也不允许重复.key判断重复的标准是: compareTo/compare的返回值是否为0.
2.3.Hashtable:
采用哈希表算法,是HashMap的前身(类似于Vector是ArrayList的前身).打死不用. 在Java的集合框架之前,表示映射关系就使用Hashtable.所有的方法都使用synchronized修饰符,线程安全的,但是性能相对HashMap较低.其子类Properties要求key和value都是String类型.
本文摘自:____
https://www.jianshu.com/p/b878a4e1c762
https://blog.csdn.net/qq\_33440140/article/details/76945557









