
摘要:中国工商银行联合华为完成了金融行业首家规模超千台的Hadoop集群大版本滚动升级,为期两周的升级过程突破了传统的离线升级模式,真正实现了业务无感的平滑滚动升级。
2020年8月27日,中国工商银行联合华为完成了金融行业首家规模超千台的Hadoop集群大版本滚动升级,为期两周的升级过程突破了传统的离线升级模式,真正实现了业务无感的平滑滚动升级。全程集群作业无中断、性能无影响,为全行上百个应用、上千个场景、上万个作业保障了7*24小时不间断的数据服务。本次滚动升级对金融科技领域意义重大,中国工商银行为金融同业树立了大数据服务连续性上的建设标杆,响应了国家大数据和人工智能战略技术高地的建设要求,为金融同业大数据平台的高可用建设提供了可参考的综合解决方案。
一、项目背景
中国工商银行从2002年起持续优化数据架构,推进数据赋能业务,在完成数据大集中的同时,率先建设金融行业企业级数据仓库。以“开放、共享”为原则,工商银行于2016年启动大数据服务云体系的建设,完成了企业级全量数据集中和通用服务沉淀,截至目前以可靠、高效、易扩展的大数据和人工智能平台为基础,以数据中台为赋能核心,构建了集基础设施、大数据和人工智能技术、海量高时效全数据、标准智能共享服务、丰富多样业务场景于一体的数据智能生态新模式(如图1),助力全行服务提质增效,向智能化、生态化时代的跃进。
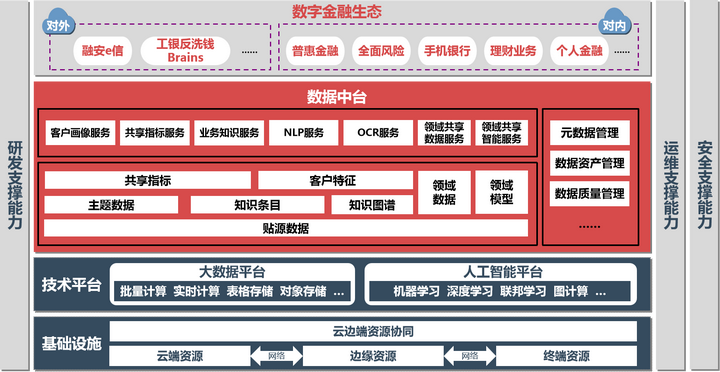
图1 中国工商银行大数据服务云现有架构
工行大数据平台的Hadoop批量集群已超过一千个节点,日均处理作业数十万个,数据存储数十PB,赋能于180余总行应用和境内外41家分行及子公司,承载了全行重点批量作业,其中包括监管报送、反洗钱、反欺诈、损益分析、减值测算等多个重要业务场景,服务连续性需求较高。为了在保障7*24小时不间断服务的前提下,维持技术引领,Hadoop集群应做到业务无感的平滑滚动升级,保障技术组件的先进性,降低技术风险,深化技术能力,助力新技术场景创新和IT架构转型升级。
二、项目内容
2.1 技术挑战
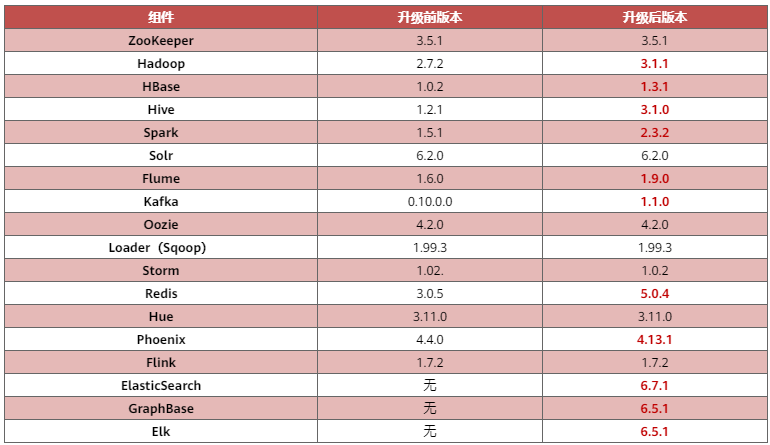
工行本次滚动升级面向的Hadoop集群,部署了ZooKeeper、HDFS、YARN、MapReduce、Spark、Hive、HBase等各类组件,各组件的版本更新必然存在一些适用性、兼容性问题(组件版本变更如表1)。
表1. 组件版本变更表
此外,集群中每日上万作业的执行,也为无感知的滚动升级加大了难度。主要挑战有以下几点:
一是Hadoop 2.X到3.X的跨大版本升级中,社区仅提供了HDFS的滚动升级能力,YARN的社区原生目标版本由于与原版本协议不同,无法支持滚动升级。
二是Hive 1.2到3.1的跨大版本升级中,由于元数据前后格式不兼容、API前后版本有变化、部分语法不兼容等问题,导致社区原生版本无法支持滚动升级。
三是社区原生版本的HDFS在升级过程中,删除的文件并不会物理删除,而是移动到trash目录,这一处理对大容量集群的滚动升级造成存储资源压力,阻碍了剩余信息保护。
四是升级前后由于版本变化,每日上万任务量,如何保障平稳运行,尤其是损益分析、减值测算等核心场景。
五是上千台的物理节点的环境下,需要确保在升级过程中,快速应对硬件(磁盘、内存等)故障,不影响升级。
六是升级过程较为复杂,应对集群升级状态强化监控、告警等运维管理服务,加强关键技术、管理瓶颈的应急响应。
2.2 技术保障
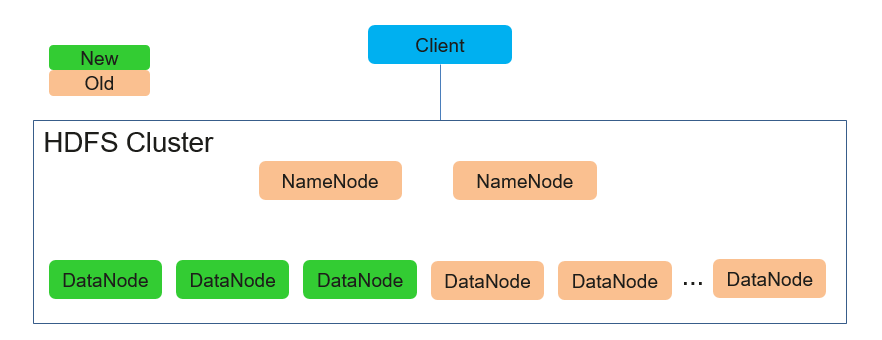
所谓滚动升级,就是借助于Hadoop核心组件的高可用机制,在不影响集群整体业务的情况下,一次升级/重启少量节点。循环滚动,直至集群所有节点升级到新版本。下图为已HDFS组件滚动升级示例:
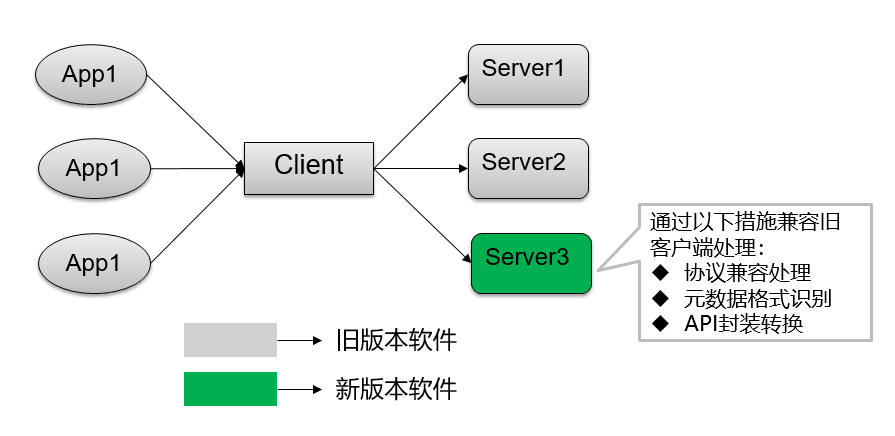
为应对上述技术挑战项目组建了滚动升级小组,由社区PMC、社区Commiter、版本Developer构成,主要执行了以下技术保障:
一是依托协议同步、元数据映射转换、API封装转换等方式,解决了社区协议不同、元数据格式不同、API变化等导致的兼容性问题,保障了滚动升级过程中低版本的组件客户端的正常使用,目前项目组已将发现的通用问题反馈开源社区。
二是针对HDFS社区新版本升级过程中的文件未删除问题,项目组额外实现了trash目录自动清理,将逻辑删除转换为物理删除,并增补了旧版本定期清理trash目录的工具。一方面确保了基础设施资源利用的有效性,降低存储成本;另一方面贯彻了国标、金标等保2.0中的剩余信息保护,确保关键信息存储空间的完全释放。
三是详细评估了各组件升级过程及升级后版本的性能状况,完成了升级时长的预估,针对升级过程中和事后可能出现的瓶颈点,做了相应架构调整及优化,助力实现滚动升级的全局可控、全程无感、全面无误。
为解决上千节点规模集群的调度性能,小组推出了自研Superior调度器,在旧版本的基础上深度优化了调度算法,将一维的调度转换为二维调度,实现调度速率提升至每秒35万个Container。
为解决大规模存储的瓶颈问题,社区推出了联邦解决方案,但不同的命名空间的引入,导致上层业务在开发、数据管理、维护上复杂度提升,为解决这一问题,社区又推出了Router Based Federation特性,但由于在NameNode之上加了一层Router进行交互,导致性能下降。小组提供了如下优化:
- 通过在大集群生产环境中识别关键瓶颈,我们通过合并单次读写流程中的交互次数、使用改良的数据通信压缩算法等技术方案,将性能下降控制在4%以内。
- 为解决不同命名空间之间数据不均衡的问题,我们利用DataMovementTool自动均衡不同命名空间之间的数据,大大降低了集群维护成本。
同时,小组发现Hive的元数据在面对海量表/分区的时候,也面临着非常大的瓶颈。虽然社区推出了Metastore Cache的解决方案,但仅适用于一个MetaStore的场景,多个MetaStore的缓存并不一致,导致此特性无法在实际场景中使用。小组提出使用Redis作为替代方案,同时通过分布式锁、缓存黑白名单机制、缓存生命周期管理等技术手段增强了该特性的可用性。
为保障大规模集群在滚动升级期间的容错能力,小组提供了任务级“断点续传”能力,例如:
Hive不中断业务能力:即当Hive beeline断连、Hive Server因故障重启、MapReduce JobHistory无响应等原因导致Hive任务失败时,任务能够继续重试运行,无需失败从头开始,大大降低了重试成本及任务时长。
AM的断点续传能力:虽然Yarn的Application Master故障后,能够立即在其他节点上被拉起,但之前已执行的计算任务只能从头开始处理。小组提供了AM记录任务执行状态、区分任务执行进度能力,待AM因故障被重启拉起后,可以安装之前的记录状态继续执行,提升了执行效率。
四是运维管理方面,项目组针对性的研发了升级管理服务界面,可以端到端、分步骤地完成滚动升级,便于查看滚动升级状态,实现组件级控制。为了降低在升级过程中对关键任务服务连续性的影响,项目实现了按升级批次暂停的功能,有助于在关键作业或者作业高峰时段,通过暂停升级进行风险规避,确保业务无影响。此外,为快速处理升级过程中可能出现的硬件故障,升级管理服务提供了故障节点隔离能力,在故障发生时,可以跳过对应节点的升级动作,保障了故障处理和升级的同步进行。
2.3 组织保障
本次升级确立了“风险可控、业务无感”的总体目标,由于目标集群规模大、涉及应用广、相关部门多,除了上述技术保障手段,工行还采取了一系列手段,提供组织保障(见图2),具体描述如下:

图2 工行滚动升级项目组织保障
在项目管理方面,如何保证跨多部门高效协同地完成工作,是集群升级过程中一个巨大的挑战。本次滚动升级项目,形成了大数据与人工智能实验室牵头、相关部门配合评审实施的组织形式。前者负责制定了整个项目具体方案和项目流程,通过内部多级评审机制,就总体方案与多部门快速达成共识,同时按照不同的部门职责完成子任务分配,从而保障跨多部门的项目组织架构高效协同工作,平稳推进整体项目进度。
升级准备方面,项目组一是完成了升级版本功能性、非功能性评估,重点验证了滚动升级的正确性、完整性、适用性;二是实现了对全行的应用场景的梳理,定制了分级验证机制,为每一个应用场景制定了相应适度的测试、验证方案,并完成了正式邮件的告知,用于百余应用的配合验证。对于分级验证机制中的数十个典型应用,通过行内“任务单”项目管理方式纳入了项目级配合流程,确保对升级过程进行重点验证。
灾备应急设计方面,工行制定了详细的保障方案,包括数据备份策略和回滚策略。对于备份策略,一是在升级之前全量备份集群元数据,排除因元数据丢失而导致丢数的情况;二是对于重点批量数据采用双园区备份,实现双加载以避免主集群升级中的故障风险影响业务。对于回滚策略,一是在技术维度保障了回滚原版本的可行性,保证业务的连续性,二是确立了“无法快速解决的生产故障”、“大规模批量作业中断”两项回滚判定条件。上述的“双加载”是重点业务双活运行方案的一部分,主要涉及监管报送类损益分析、减值测算等多个应用场景,该类作业在备集群同步运行,实现重点批量双园区双活,切实避免因单边园区故障影响业务连续性的情况出现。
升级模拟方面,为了遵循风险可控、循序渐进的原则,工行先后进行了两套较小规模的集群滚动升级。一是2020年3月针对Hadoop批量备集群进行滚动升级,该集群负责同城双活运行的重要批量作业,经生产环境实际验证,升级过程中业务无感知,也未发现集群侧风险;二是2020年4月,工行搭建一套规模更大的Hadoop批量集群,一方面增强批量双活承载能力,另一方面再次验证了滚动升级。两次生产环境模拟之外,开发、测试环境共计10套不同的Hadoop集群陆续完成了滚动升级验证,实现了升级风险的归纳总结和研发修订,为最大规模的集群升级打下坚实基础。
三、总结与展望
中国工商银行联合华为公司完成的本次金融业首家规模超千台的Hadoop集群大版本滚动升级,实现了客户无感知,切实保障了客户的核心利益,标志着工行向金融大数据蓝图迈出了重要的一步,借助于Hadoop核心组件的高可用机制,完成了端到端分步骤的滚动升级,实现了升级过程中的可视化控制和管理。
大数据的高速发展带来的社会经济的“革命”,在广度、深度和速度上都将会是空前的,也将会远远超出工业社会的常识和认知,并且发展所带来的的挑战和困难也将是前所未有的。在此背景下,中国工商银行会继续建立健全企业级大数据平台,进一步提升数据洞察能力和基于场景的数据挖掘能力,充分释放大数据作为基础性战略资源的核心价值,为金融科技应用实践和大数据生态建设建设添砖加瓦。
本文分享自华为云社区《华为云FusionInsight MRS金融行业首个1000+大集群滚动升级成功》,原文作者:Sailing27 。











