
缓存是什么
缓存是一个到处都存在的用空间换时间的例子。通过使用多余的空间,我们能够获取更快的速度。
我们通常意义上说的缓存主要包含两部分。第一个是用户浏览器端的缓存,第二个是服务器端为了提高访问速度而加的CDN。
首先,看看没有网站没有接入CDN时,用户浏览器与服务器是如何交互的:
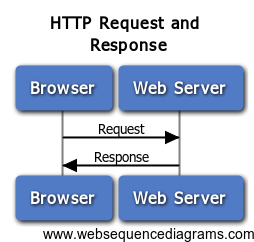
用户在浏览网站的时候,浏览器能够在本地保存网站中的图片或者其他文件的副本,这样用户再次访问该网站的时候,浏览器就不用再下载全部的文件,减少了下载量意味着提高了页面加载的速度。
如果中间加上一层CDN,那么用户浏览器与服务器的交互如下:
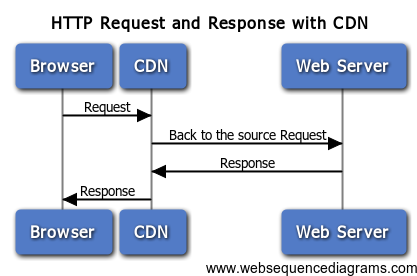
客户端浏览器先检查是否有本地缓存是否过期,如果过期,则向CDN边缘节点发起请求,CDN边缘节点会检测用户请求数据的缓存是否过期,如果没有过期,则直接响应用户请求,此时一个完成http请求结束;如果数据已经过期,那么CDN还需要向源站发出回源请求(back to the source request),来拉取最新的数据。CDN的典型拓扑图如下:
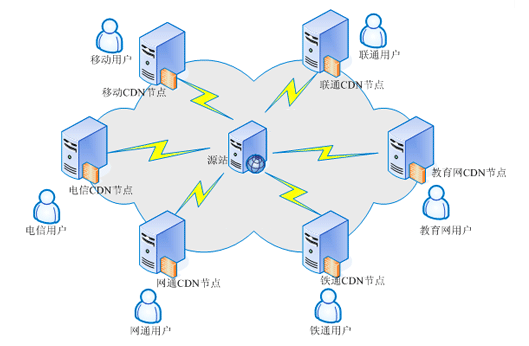
图片来源: http://grefr.iteye.com/blog/2004248
可以看到,在存在CDN的场景下,数据经历了客户端(浏览器)缓存和CDN边缘节点缓存两个阶段,下面分别对这两个阶段的缓存进行详细的剖析。
客户端(浏览器)缓存
客户端缓存的缺点
客户端缓存减少了的服务器请求,避免了文件重复加载,显著地提升了用户地方。但是 当网站发生了更新的时候(如替换了css、js以及图片文件),浏览器本地仍保存着旧版本的文件,从而导致无法预料后果。
曾几何时,一个页面加载出来,页面各元素位置乱飘,按钮点击失效,前端GG都会习惯性地问一句:“缓存清了没?”,然后Ctrl+F5 ,Everything is OK。但有些时候,如果我们是简单地在浏览器地址栏中敲一个回车,或者是仅仅按F5刷新,问题依然没有解决,你可知道这三种不同的操作方式,决定浏览器不同的刷新缓存策略?
浏览器如何来确定使用本地文件还是使用服务器上的新文件?下面来介绍几种判断的方法。
浏览器缓存策略
Expires
Expires:Sat, 24 Jan 2015 20:30:54 GMT
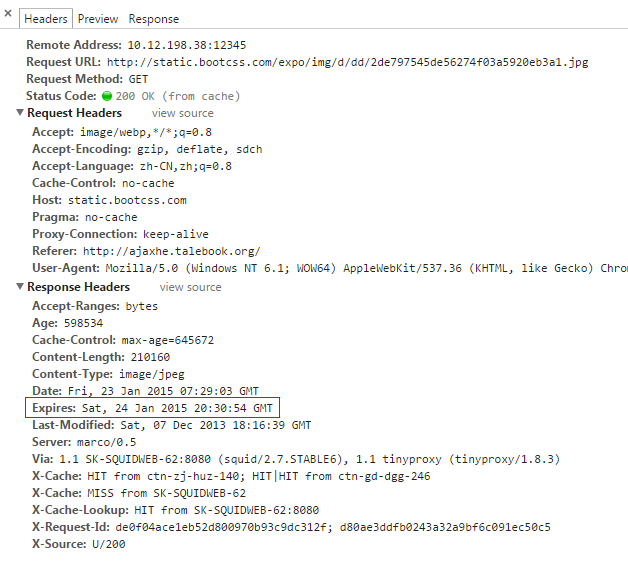
如果http响应报文中设置了Expires,在Expires过期之前,我们就避免了和服务器之间的连接。此时,浏览器无需想浏览器发出请求,只需要自己判断手中的材料是否过期就可以了,完全不需要增加服务器的负担。
Cache-control: max-age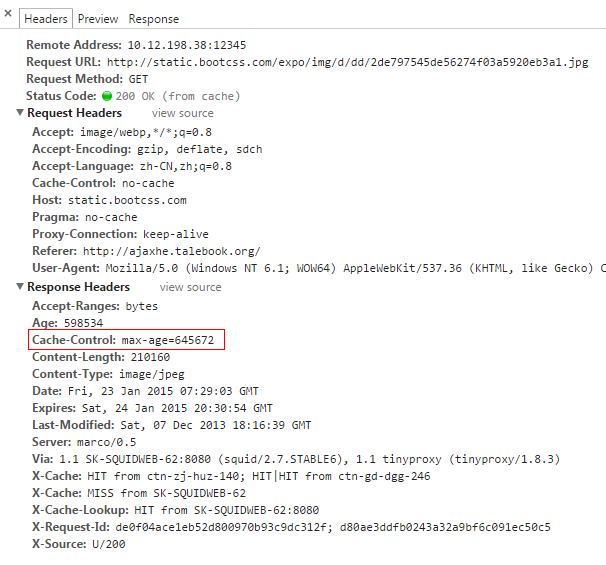
Expires的方法很好,但是我们每次都得算一个精确的时间。max-age 标签可以让我们更加容易的处理过期时间。我们只需要说,这份资料你只能用一个星期就可以了。
Max-age 使用秒来计量,如:
Cache-Control:max-age=645672
指定页面645672秒(7.47天)后过期。
Last-Modified
服务器为了通知浏览器当前文件的版本,会发送一个上次修改时间的标签,例如:
Last-Modified:Tue, 06 Jan 2015 08:26:32 GMT
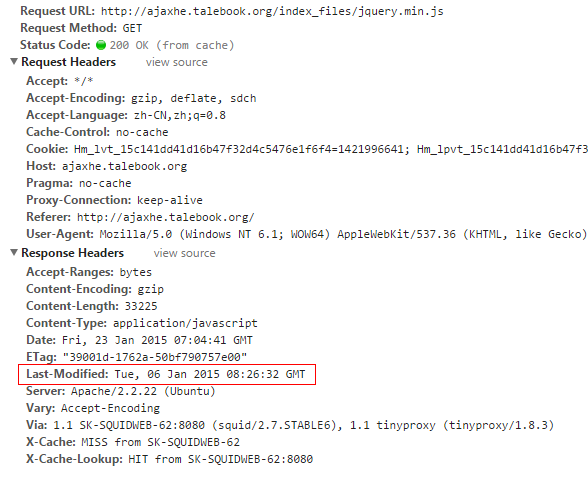
这样浏览器就知道他收到的这个文件创建时间,在后续的请求中,浏览器会按照下面的规则进行验证:
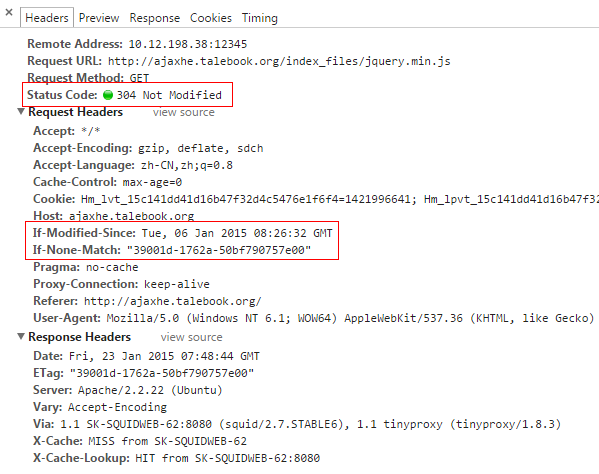
1. 浏览器:Hey,我需要jquery.min.js这个文件,如果是在 Tue, 06 Jan 2015 08:26:32 GMT 之后修改过的,请发给我。
2. 服务器:(检查文件的修改时间)
3. 服务器:Hey,这个文件在那个时间之后没有被修改过,你已经有最新的版本了。
4. 浏览器:太好了,那我就显示给用户了。
在这种情况下,服务器仅仅返回了一个304的响应头,减少了响应的数据量,提高了响应的速度。关于304响应,请参考:
http://www.cnblogs.com/ziyunfei/archive/2012/11/17/2772729.html
下图是按F5刷新页面后,页面返回304响应头。
ETag
通常情况下,通过修改时间来比较文件是可行的。但是在一些特殊情况,例如服务器的时钟发生了错误,服务器时钟进行修改,夏时制DST到来后服务器时间没有及时更新,这些都会引起通过修改时间比较文件版本的问题。
ETag可以用来解决这种问题。ETag是一个文件的唯一标志符。就像一个哈希或者指纹,每个文件都有一个单独的标志,只要这个文件发生了改变,这个标志就会发生变化。
服务器返回ETag标签:
ETag:"39001d-1762a-50bf790757e00"
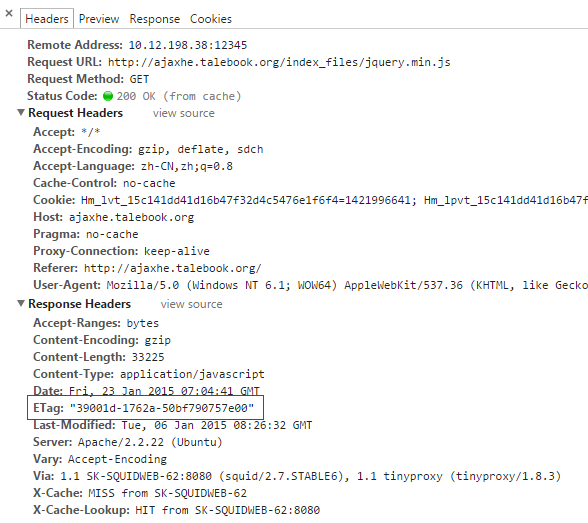
接下来的访问顺序如下所示:
1. 浏览器:Hey,我需要jquery.min.js这个文件,有没有不匹配"39001d-1762a-50bf790757e00"这个串的
2. 服务器:(检查ETag…)
3. 服务器:Hey,我这里的版本也是"39001d-1762a-50bf790757e00",你已经是最新的版本了
4. 浏览器:好,那就可以使用本地缓存了
如同 Last-modified 一样,ETag 解决了文件版本比较的问题。只不过 ETag 的级别比 Last-Modified 高一些。
额外的标签
缓存标签永远不会停止工作,但是有时候我们需要对已经缓存的内容进行一些控制。
l Cache-control: public 表示缓存的版本可以被代理服务器或者其他中间服务器识别。
l Cache-control: private 意味着这个文件对不同的用户是不同的。只有用户自己的浏览器能够进行缓存,公共的代理服务器不允许缓存。
l Cache-control: no-cache 意味着文件的内容不应当被缓存。这在搜索或者翻页结果中非常有用,因为同样的URL,对应的内容会发生变化。
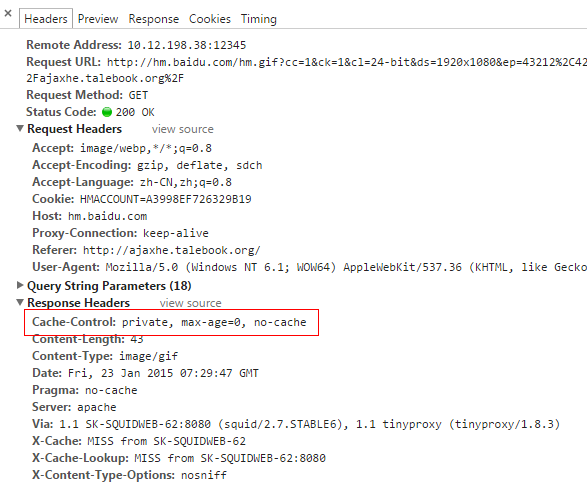
浏览器缓存刷新
1. 在地址栏中输入网址后按回车或点击转到按钮
浏览器以最少的请求来获取网页的数据,浏览器会对所有没有过期的内容直接使用本地缓存,从而减少了对浏览器的请求。所以,Expires,max-age标记只对这种方式有效。
2. 按F5或浏览器刷新按钮
浏览器会在请求中附加必要的缓存协商,但不允许浏览器直接使用本地缓存,它能够让 Last-Modified、ETag发挥效果,但是对Expires无效。
3. 按Ctrl+F5或按Ctrl并点击刷新按钮
这种方式就是强制刷新,总会发起一个全新的请求,不使用任何缓存。
CDN是什么
CDN的全称是Content Delivery Network,即内容分发网络。其基本思路是尽可能避开互联网上有可能影响数据传输速度和稳定性的瓶颈和环节,使内容传输的更快、更稳定。
CDN可以理解为一个普通缓存,如代理缓存或者说边缘缓存,即便不关心用户的具体地理位置,也应该考虑使用cdn的代理缓存来提高用户体验。
CDN的作用
可以用8年买火车票的经历来形象比喻:
8年前,还没有火车票代售点一说,12306.cn更是无从说起。那时候火车票还只能在火车站的售票大厅购买,而我所住的小县城并不通火车,火车票都要去市里的火车站购买,而从县城到市里,来回就是4个小时车程,简直就是浪费生命。后来就好了,小县城里出现了火车票代售点,可以直接在代售点购买火车,方便了不少,全市人民再也不用在一个点苦逼的排队买票了。
CDN就可以理解为分布在每个县城的火车票代售点,用户在浏览网站的时候,CDN会选择一个离用户最近的CDN边缘节点来响应用户的请求,这样海南移动用户的请求就不会千里迢迢跑到北京电信机房的服务器(假设源站部署在北京电信机房)上了。
CDN的优势
很明显:
(1)CDN节点解决了跨运营商和跨地域访问的问题,访问延时大大降低;
(2)大部分请求在CDN边缘节点完成,CDN起到了分流作用,减轻了源站的负载。
CDN的缺点
当网站更新时,如果CDN节点上数据没有及时更新,即便用户再浏览器使用Ctrl +F5的方式使浏览器端的缓存失效,也会因为CDN边缘节点没有同步最新数据而导致用户访问异常。
CDN缓存策略
CDN边缘节点缓存策略因服务商不同而不同,但一般都会遵循http标准协议,通过http响应头中的Cache-control: max-age的字段来设置CDN边缘节点数据缓存时间。
当客户端向CDN节点请求数据时,CDN节点会判断缓存数据是否过期,若缓存数据并没有过期,则直接将缓存数据返回给客户端;否则,CDN节点就会向源站发出回源请求,从源站拉取最新数据,更新本地缓存,并将最新数据返回给客户端。
CDN服务商一般会提供基于文件后缀、目录多个维度来指定CDN缓存时间,为用户提供更精细化的缓存管理。
CDN缓存时间会对“回源率”产生直接的影响。若CDN缓存时间较短,CDN边缘节点上的数据会经常失效,导致频繁回源,增加了源站的负载,同时也增大的访问延时;若CDN缓存时间太长,会带来数据更新时间慢的问题。开发者需要增对特定的业务,来做特定的数据缓存时间管理。
CDN缓存刷新
CDN边缘节点对开发者是透明的,相比于浏览器Ctrl+F5的强制刷新来使浏览器本地缓存失效,开发者可以通过CDN服务商提供的“刷新缓存”接口来达到清理CDN边缘节点缓存的目的。这样开发者在更新数据后,可以使用“刷新缓存”功能来强制CDN节点上的数据缓存过期,保证客户端在访问时,拉取到最新的数据。











