
喜欢我们,点击上方AINLPer,关注一下,极品干货即刻送达!
转 载: 哈工大SCIR
各位小伙伴,最近全国各地陆续发现新型冠状病毒感染的肺炎疫情,又赶上春节, 大 家 出门 请 注 意戴口罩,做好 防护 ~~
引言
现有的不流利检测方法大多严重依赖人工标注的数据,而在实践中获取这些数据的成本很高。为了解决训练数据的瓶颈,本文研究了将多个自监督任务相结合的方法。在监督任务中,无需人工标记就可以收集数据。
正文开始
1
First Blood
TILE: Multi-Task Self-Supervised Learning for Disfluency Detection
Contributor : 哈尔滨工业大学
Paper: http://ir.hit.edu.cn/~slwang/AAAI-WangS.1634.pdf
Code: None
文章摘要
本文研究的将多个自监督任务相结合的方法。首先,我们通过随机添加或删除未标记新闻数据中的单词来构建大规模的伪训练数据,并提出了两个自我监督的训练前任务:(1)标记任务来检测添加的噪声单词。(2)对句子进行分类,区分原句和语法错误句。然后我们将这两个任务结合起来共同训练一个网络。然后使用人工标注的不流利检测训练数据对训练前的网络进行微调。在常用的英语交换机测试集上的实验结果表明,与以前的系统(使用完整数据集进行训练)相比,本文的方法只需使用不到1%(1000个句子)的训练数据,就可以获得具有竞争力的性能。
文本顺滑背景介绍
自动语音识别(ASR)得到的文本中,往往含有大量的不流畅现象。这些不流畅现象会对后面的自然语言理解系统(如句法分析,机器翻译等)造成严重的干扰,因为这些系统往往是在比较流畅的文本上训练的。不流畅现象主要分为两部分,一部分是ASR系统本身识别错误造成的,另一部分是speaker话中自带的。NLP领域主要关注的是speaker话中自带的不流畅现象,ASR识别错误则属于语音识别研究的范畴。顺滑 (Disfluency Detection)任务的目的就是要识别出speaker话中自带的不流畅现象。
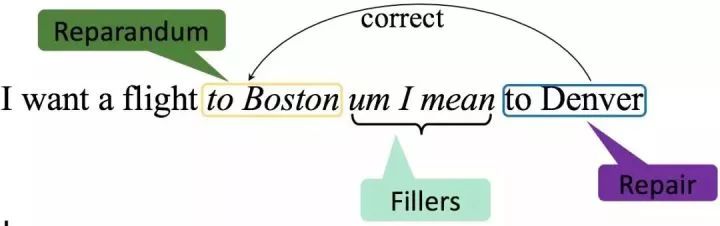
Speaker话中自带的不流畅现象主要分为两大类,分别为Filler类型和Edit类型。以英文为例,Filler类型主要包括“uh”“oh”等语气词,以及“so”“well”等话语标记语。Filler类型的一个特点是其对应的不流畅部分属于一个封闭的短语集合,因此,利用简单的规则或者机器学习模型就可以很好地识别Filler类型。Edit类型主要包括重复,以及被后面的短语所纠正的部分。图1是一个英文顺滑任务的示例。在例句中,“um”“I mean”属于Filler类型,“to Boston”则属于Edit类型,其被后面的“to Denver”所纠正。Edit类型是顺滑任务中最难处理的类型,因为Edit类型的短语长度不固定,出现的位置比较灵活,甚至会出现嵌套的结构。因此,顺滑相关的研究主要集中Edit类型的处理上(后面的内容默认处理的是Edit类型)。对于顺滑任务,目前主要用到的语料是English Switchboard数据,在中文上还没有公开的语料。
**本文研究目标
**
目前大部分在文本顺滑任务上的工作都严重依赖人工标注数据。为了减少对有标注数据的依赖,我们尝试用自监督学习的方法来处理文本顺滑任务。
自监督学习可以看作是一种特殊的有监督学习,跟传统有监督学习方法的主要区别是其用到的标签不是通过人工标注的,而是通过一定的方式自动产生的。例如将一张图片切分成若干个子块,然后将随机打乱顺序的子块作为输入,正确的排列顺序就可以作为有监督的标签。在自然语言处理领域,词嵌入、语言模型学习等都可以归类于自监督学习。受相关研究工作的启发,我们提出了两种针对文本顺滑任务的自监督学习任务,实验结果证明本文的方法****能有效减少对有标注数据的依赖,只利用1%左右的有标注数据就能实现与之前最好方法类似的性能。
论文方法介绍
如下图所示,本文方法主要由三部分组成,第一部分是构造伪数据,第二部分是基于构造的伪数据,对两个自监督任务进行预训练,第三部分则是基于预训练的结果,在人工标注的文本顺滑数据上进行微调。
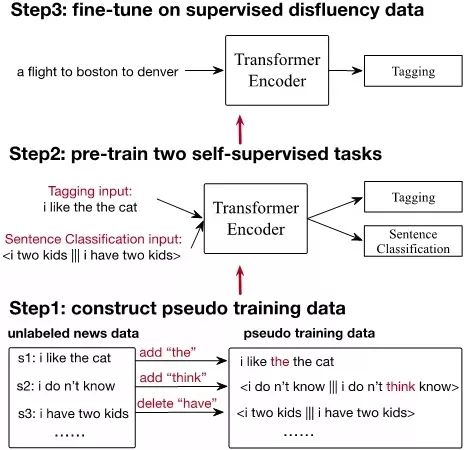
伪数据生成

自监督任务以及微调

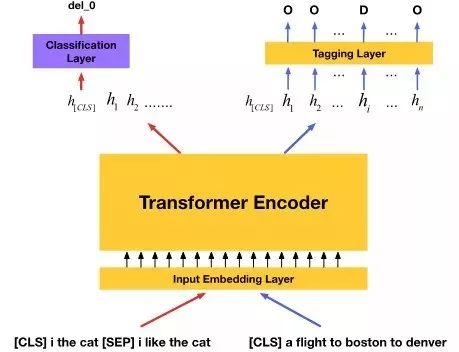
实验结果
实验设置
我们在English Switchboard(SWBD)数据集上测试我们方法的性能。对于伪数据部分,我们总共用到了1200万的数据,其中300万用来训练序列标注任务,900万用来训练句子分类任务。我们将Transformer模型大小设置为512 hidden units, 8 heads, 6 hidden layers。
结果分析
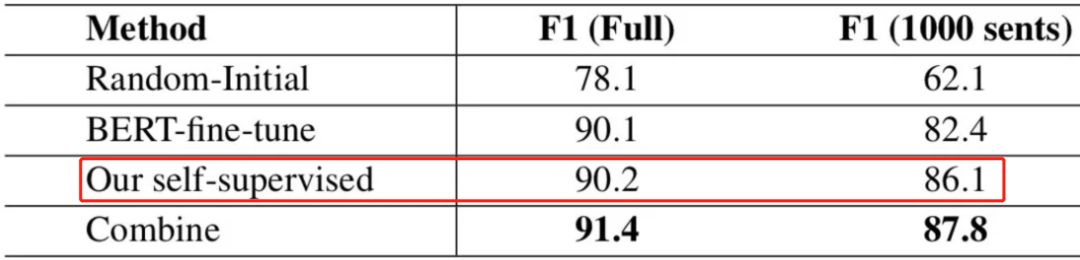
我们与五个目前性能最好的方法进行了比较,这些方法都依赖于大规模的人工标注数据和复杂的人工特征。如表1所示,我们的方法优于之前最好的方法,获得了90.2%的F1分数。特别是,当只用1%(1000句)的人工标注数据的情况下,我们的方法获得了与以前性能最好的方法相接近的F1分数,这表明我们的自监督方法可以大大减少对人工标注数据的依赖。
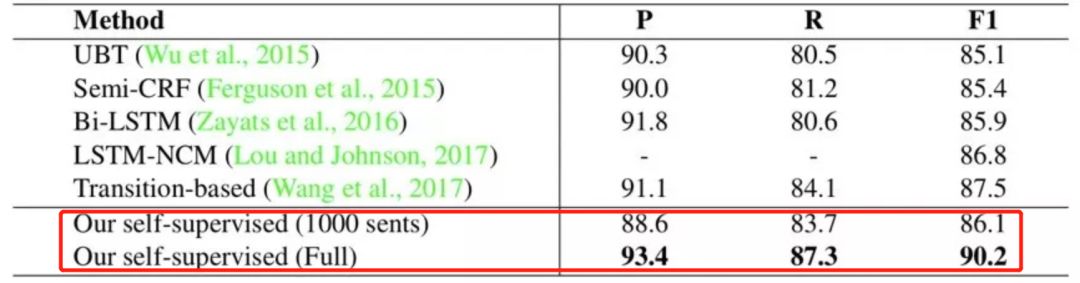
表1 与之前方法对比。 其中“Full”表示所有有标注数据进行微调,“1000sents”表示1%(1000句)有标注数据进行微调
BERT模型对比
与BERT相比,我们的方法可以看作是一个针对特定任务的预训练,本节主要对比我们模型和BERT模型在文本顺滑任务上的性能。结果如表2所示,虽然我们的预训练语料规模和模型参数都比BERT小,但是当用全部人工标注数据进行微调时,我们得到了与BERT相似的结果。特别是当只用1%(1000句)左右人工标注数据进行微调时,我们的方法比BERT要高3.7个点左右。最后,我们尝试将我们模型和BERT模型结合起来,具体做法是在微调时,将我们模型和BERT模型的隐层输出结合起来做序列标注任务,实验结果证明模型结合之后能取得更高的性能,这也证明了我们的模型学习到了BERT之外的对顺滑任务有帮助的信息。
2
往期回顾
学术圈
收藏!「自然语言处理(NLP)」AINLPer 大 盘 点 !!
收藏!「自然语言处理(NLP)」全球学术界”巨佬“信息大盘点(一)!
论文阅读
ICLR 2020必看!「自然语言处理(NLP)」金融情感分析FinBERT模型(含源码)!!
「自然语言处理(NLP)」【爱丁堡大学】基于实体模型的数据文本生成!!
长按识别下方二维码,关注我们吧(づ ̄3 ̄)❤~

资料整理实属不易,点个【在看】再走吧~~

本文分享自微信公众号 - AINLPer(gh_895a8687a10f)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。











