

概述
容器化技术在当前云计算、微服务等体系下大行其道,而 Docker 便是容器化技术的典型,对于容器化典型的技术,我们有必要弄懂它,所以这篇文章,我会来分析下 Docker 是如何实现隔离技术的,Docker 与虚拟机又有哪些区别呢?接下来,我们开始逐渐揭开它的面纱。
从运行一个容器开始
我们开始运行一个简单的容器,这里以busybox镜像为例,它是一个常用的Linux工具箱,可以用来执行很多Linux命令,我们以它为镜像启动容器方便来查看容器内部环境。 执行命令:
docker run -it --name demo_docker busybox /bin/sh
这条命令的意思是:启动一个busybox镜像的 Docker 容器,-it参数表示给容器提供一个输出/输出的交互环境,也就是TTY。/bin/sh表示容器交互运行的命令或者程序。
进程的隔离
执行成功后我们就会进入到了 Docker 容器内部,我们执行ps -ef 查看进程
/ # ps -ef
PID USER TIME COMMAND
1 root 0:00 /bin/sh
8 root 0:00 ps -ef
使用top命令查看进程资源
Mem: 1757172K used, 106080K free, 190676K shrd, 129872K buff, 998704K cached
CPU: 0.0% usr 0.2% sys 0.0% nic 99.6% idle 0.0% io 0.0% irq 0.0% sirq
Load average: 0.00 0.01 0.05 2/497 9
PID PPID USER STAT VSZ %VSZ CPU %CPU COMMAND
1 0 root S 1300 0.0 1 0.0 /bin/sh
9 1 root R 1292 0.0 3 0.0 top
而我们在宿主机查看下当前执行容器的进程ps -ef|grep busybox
root 5866 5642 0 01:19 pts/4 00:00:00 /usr/bin/docker-current run -it --name demo_docker busybox /bin/sh
root 5952 5759 0 01:20 pts/11 00:00:00 grep --color=auto busybox
这里我们可以知道,对于宿主机 docker run 执行命令启动的只是一个进程,它的pid是5866。而对于容器程序本身来说,它被隔离了,在容器内部都只能看到自己内部的进程,那 Docker 是如何做到的呢?它其实是借助了Linux内核的Namespace技术来实现的,这里我结合一段C程序来模拟一下进程的隔离。
#define _GNU_SOURCE
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/wait.h>
#include <stdio.h>
#include <sched.h>
#include <signal.h>
#include <unistd.h>
#include <sys/mount.h>
/* 定义一个给 clone 用的栈,栈大小1M */
#define STACK_SIZE (1024 * 1024)
static char container_stack[STACK_SIZE];
char* const container_args[] = {
"/bin/bash",
NULL
};
int container_main(void* arg)
{
printf("容器进程[%5d] ----进入容器!\n",getpid());
mount("proc", "/proc", "proc", 0, NULL);
/**执行/bin/bash */
execv(container_args[0], container_args);
printf("出错啦!\n");
return 1;
}
int main()
{
printf("宿主机进程[%5d] - 开始一个容器!\n",getpid());
/* 调用clone函数 */
int container_pid = clone(container_main, container_stack+STACK_SIZE, CLONE_NEWPID | CLONE_NEWNS | SIGCHLD, NULL);
/* 等待子进程结束 */
waitpid(container_pid, NULL, 0);
printf("宿主机 - 容器结束!\n");
return 0;
}
考虑到很多同学对C语言不是很熟悉,我这里简单解释下这段程序,这段程序主要就是执行clone()函数,去克隆一个进程,而克隆执行的程序就是我们的container_main函数,接着下一个参数就是栈空间,然后CLONE_NEWPID和CLONE_NEWNS 表示Linux NameSpace的调用类别,分别表示创建新的进程命名空间和 挂载命名空间。
CLONE_NEWPID会让执行的程序内部重新编号PID,也就是从1号进程开始CLONE_NEWNS会克隆新的挂载环境出来,通过在子进程内部重新挂载proc文件夹,可以屏蔽父进程的进程信息。
我们执行一下这段程序来看看效果。
编译
gcc container.c -o container
执行
[root@host1 luozhou]# ./container
宿主机进程[ 6061] - 开始一个容器!
容器进程[ 1] ----进入容器!
这里我们看到输出在宿主机看来,这个程序的PID是6061,在克隆的子进程来看,它的PID是1,我们执行ps -ef 查看一下进程列表
[root@host1 luozhou]# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 01:46 pts/2 00:00:00 /bin/bash
root 10 1 0 01:48 pts/2 00:00:00 ps -ef
我们发现确实只有容器内部的进程在运行了,再执行top命令
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1 root 20 0 115576 2112 1628 S 0.0 0.1 0:00.00 bash
11 root 20 0 161904 2124 1544 R 0.0 0.1 0:00.00 top
结果也只有2个进程的信息。
这就是容器隔离进程的基本原理了,Docker主要就是借助 Linux 内核技术Namespace来做到隔离的,其实包括我后面要说到文件的隔离,资源的隔离都是在新的命名空间下通过mount挂载的方式来隔离的。
文件的隔离
了解完进程的隔离,相信你们已经对 Docker 容器的隔离玩法就大概的印象了,我们接下来看看,Docker 内部的文件系统如何隔离,也就是你在 Docker 内部执行 ls 显示的文件夹和文件如何来的。
我们还是以前面的 Docker 命令为例,执行ls
bin dev etc home proc root run sys tmp usr var
我们发现容器内部已经包含了这些文件夹了,那么这些文件夹哪里来的呢?我们先执行docker info 来看看我们的 Docker 用到的文件系统是什么?
Server Version: 1.13.1
Storage Driver: overlay2
我的版本是1.13.1,存储驱动是overlay2,不同的存储驱动在 Docker 中表现不一样,但是原理类似,我们来看看 Docker 如何借助overlay2来变出这么多文件夹的。我们前面提到过,Docker都是通过mount 去挂载的,我们先找到我们的容器实例id.
执行docker ps -a |grep demo_docker
c0afd574aea7 busybox "/bin/sh" 42 minutes ago Up 42 minutes
我们再根据我们的容器ID 去查找挂载信息,执行cat /proc/mounts | grep c0afd574aea7
shm /var/lib/docker/containers/c0afd574aea716593ceb4466943bbd13e3a081bf84da0779ee43600de0df384b/shm tmpfs rw,context="system_u:object_r:container_file_t:s0:c740,c923",nosuid,nodev,noexec,relatime,size=65536k 0 0
这里出现了一个挂载信息,但是这个记录不是我们的重点,我们需要找到overlay2的挂载信息,所以这里我们还需要执行一个命令:cat /proc/mounts | grep system_u:object_r:container_file_t:s0:c740,c923
overlay /var/lib/docker/overlay2/9c9318031bc53dfca45b6872b73dab82afcd69f55066440425c073fe681109d3/merged overlay rw,context="system_u:object_r:container_file_t:s0:c740,c923",relatime,lowerdir=/var/lib/docker/overlay2/l/FWESUOVO6DYTXBBJIQBPUWLN6K:/var/lib/docker/overlay2/l/XPKQU6AMUX3AKLAX2BR6V4JQ3R,upperdir=/var/lib/docker/overlay2/9c9318031bc53dfca45b6872b73dab82afcd69f55066440425c073fe681109d3/diff,workdir=/var/lib/docker/overlay2/9c9318031bc53dfca45b6872b73dab82afcd69f55066440425c073fe681109d3/work 0 0
shm /var/lib/docker/containers/c0afd574aea716593ceb4466943bbd13e3a081bf84da0779ee43600de0df384b/shm tmpfs rw,context="system_u:object_r:container_file_t:s0:c740,c923",nosuid,nodev,noexec,relatime,size=65536k 0 0
这里overlay挂载并没有和容器id关联起来,所以我们直接根据容器id是找不到 overlay挂载信息的,这里借助了context 去关联的,所以我们通过context就找到了我们挂载的地址啦。我们进入目录看看结果
[root@host1 l]# ls /var/lib/docker/overlay2/9c9318031bc53dfca45b6872b73dab82afcd69f55066440425c073fe681109d3/merged
bin dev etc home proc root run sys tmp usr var
我们发现这个和我们容器的目录是一致的,我们在这个目录下创建一个新的目录,然后看看容器内部是不是会出现新的目录。 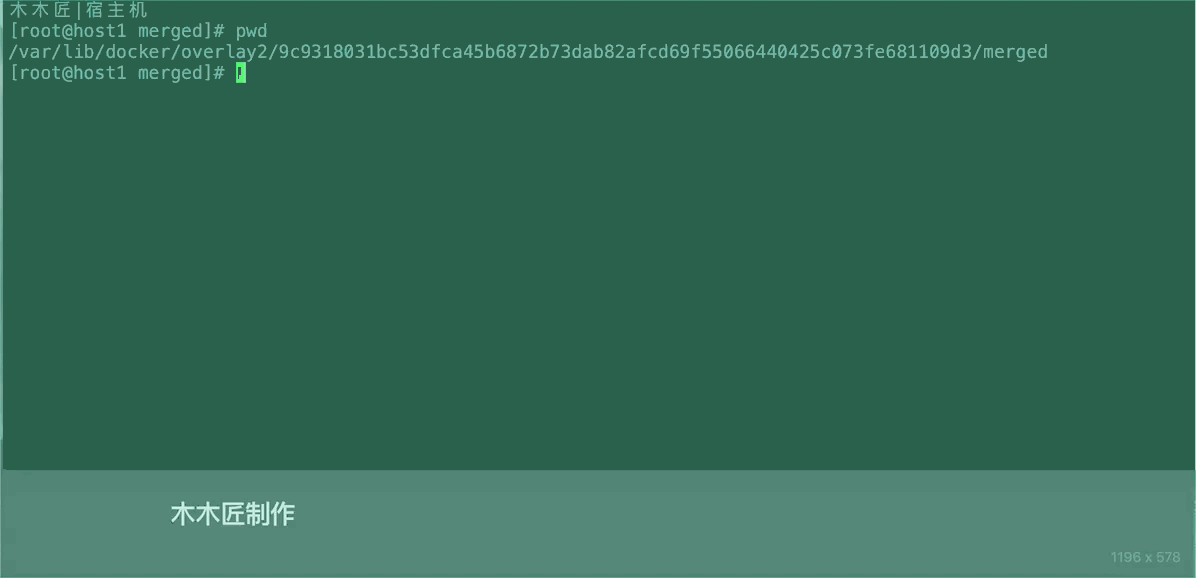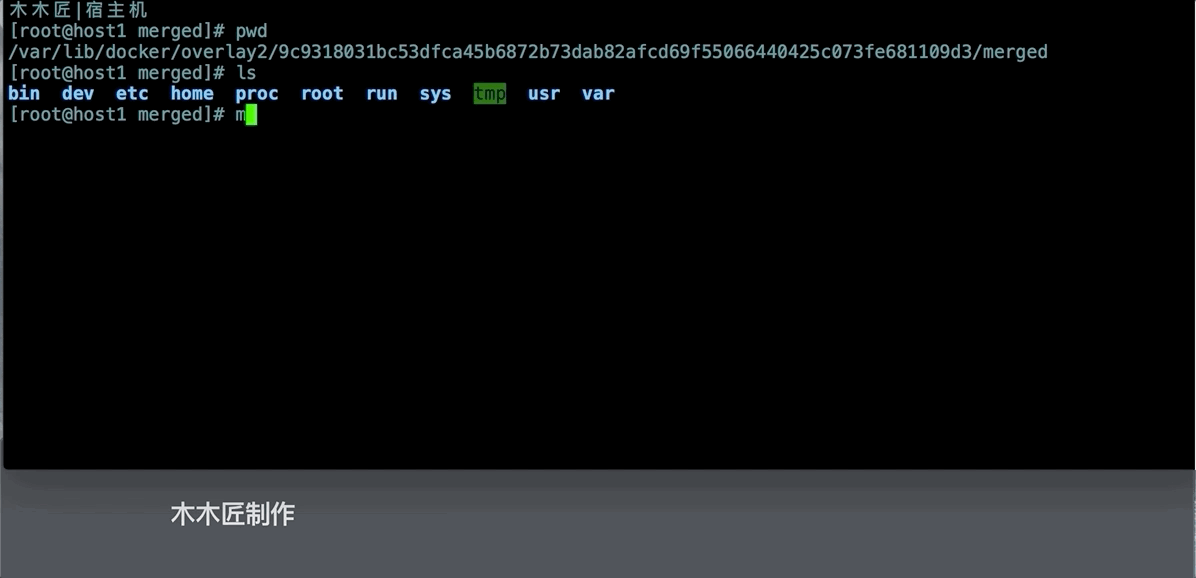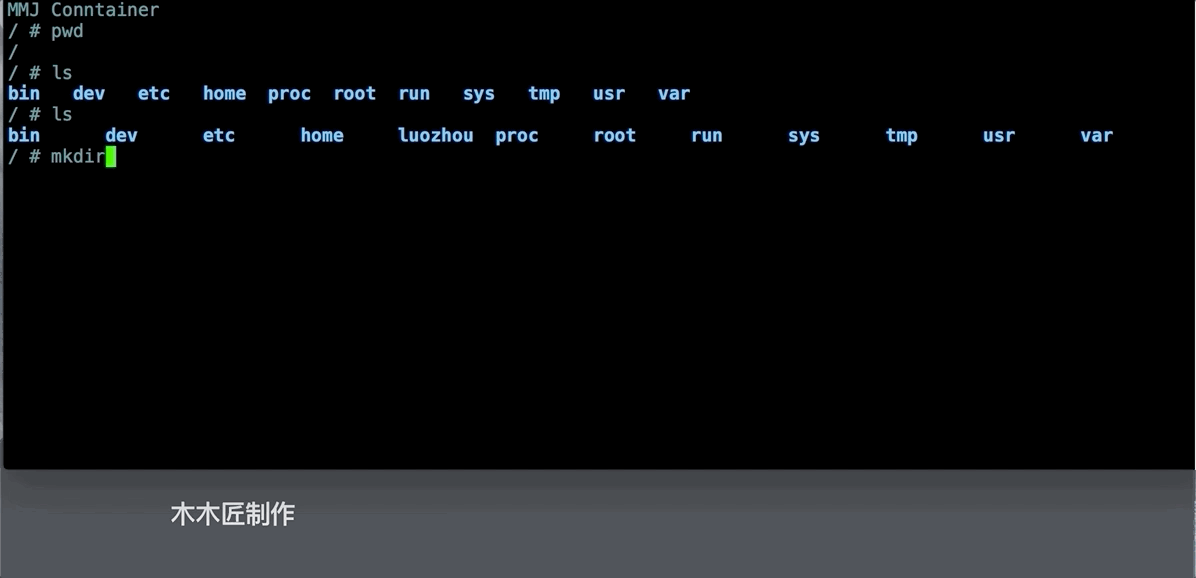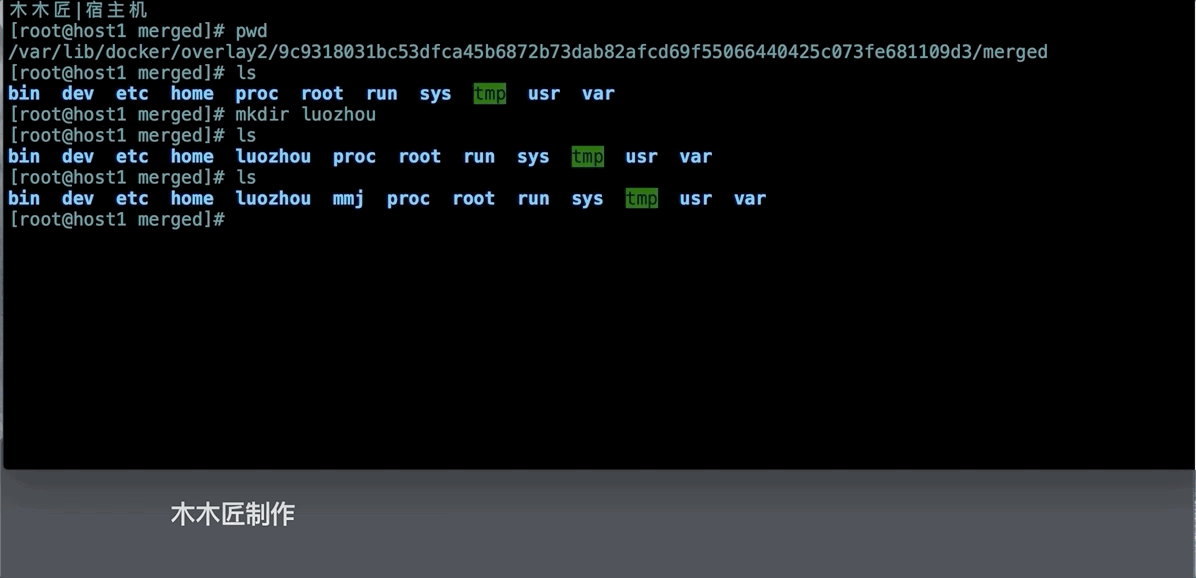
上面的图片验证了容器内部的文件内容和挂载的/var/lib/docker/overlay2/ID/merged下是一致的,这就是Docker文件系统隔离的基本原理。
资源的限制
玩过 Docker 的同学肯定知道,Docker 还是可以限制资源使用的,比如 CPU 和内存等,那这部分是如何实现的呢? 这里就涉及到Linux的另外一个概念Cgroups技术,它是为进程设置资源限制的重要手段,在Linux 中,一切皆文件,所以Cgroups技术也会体现在文件中,我们执行mount -t cgroup 就可以看到Cgroups的挂载情况
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd)
cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,devices)
cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,net_prio,net_cls)
cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,hugetlb)
cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,perf_event)
cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,freezer)
cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,blkio)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,cpuacct,cpu)
cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,pids)
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,memory)
cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,cpuset)
我们看到上面挂载的目录有包括 cpu和memory 那我们猜测大概就是在这个文件夹下面配置限制信息的了。我们跑一个容器来验证下,执行命令:
docker run -d --name='cpu_set_demo' --cpu-period=100000 --cpu-quota=20000 busybox md5sum /dev/urandom
这个命令表示我们需要启动一个容器,这个容器一直产生随机数进行md5计算来消耗CPU,--cpu-period=100000 --cpu-quota=20000表示限制 CPU 使用率在20%,关于这两个参数的详细说明可以点击这里
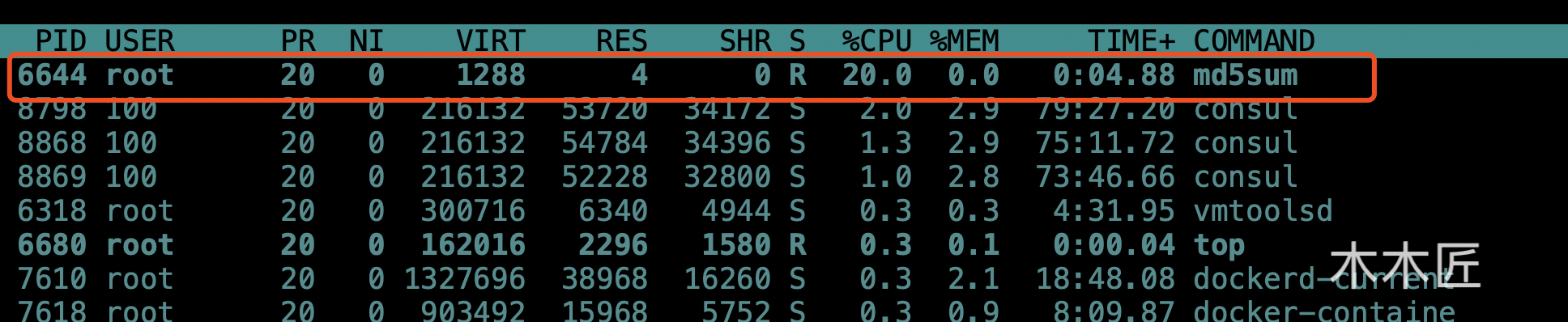
我们查看进程消耗情况发现 刚刚启动的容器资源确实被限制在20%,说明 Docker 的CPU限制参数起作用了,那对应在我们的cgroup 文件夹下面是怎么设置的呢? 同样,这里的配置肯定是和容器实例id挂钩的,我的文件路径是在/sys/fs/cgroup/cpu/system.slice/docker-5bbf589ae223b347c0d10b7e97cd1461ef82149a6d7fb144e8b01fcafecad036.scope下,5bbf589ae223b347c0d10b7e97cd1461ef82149a6d7fb144e8b01fcafecad036 就是我们启动的容器id了。
切换到上面的文件夹下,查看我们设置的参数:
[root@host1]# cat cpu.cfs_period_us
100000
[root@host1]# cat cpu.cfs_quota_us
20000
发现这里我们的容器启动设置参数一样,也就是说通过这里的文件值来限制容器的cpu使用情况。这里需要注意的是,不同的Linux版本 Docker Cgroup 文件位置可能不一样,有些是在/sys/fs/cgroup/cpu/docker/ID/ 下。
与传统虚拟机技术的区别
经过前面的进程、文件系统、资源限制分析,详细各位已经对 Docker 的隔离原理有了基本的认识,那么它和传统的虚拟机技术有和区别呢?这里贴一个网上的Docker和虚拟机区别的图
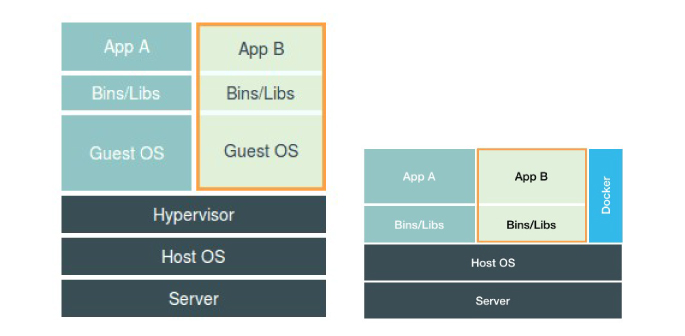
这张图应该可以清晰的展示了虚拟机技术和 Docker 技术的区别了,虚拟机技术是完全虚拟出一个单独的系统,有这个系统去处理应用的各种运行请求,所以它实际上对于性能来说是有影响的。而 Docker 技术 完全是依赖 Linux 内核特性 Namespace 和Cgroup 技术来实现的,本质来说:你运行在容器的应用在宿主机来说还是一个普通的进程,还是直接由宿主机来调度的,相对来说,性能的损耗就很少,这也是 Docker 技术的重要优势。
Docker 技术由于 还是一个普通的进程,所以隔离不是很彻底,还是共用宿主机的内核,在隔离级别和安全性上没有虚拟机高,这也是它的一个劣势。
总结
这篇文章我通过实践来验证了 Docker 容器技术在进程、文件系统、资源限制的隔离原理,最后也比较了虚拟机和 Docker 技术的区别,总的来说 Docker技术由于是一个普通的宿主机进程,所以具有性能优势,而虚拟机由于完全虚拟系统,所以具备了高隔离性和安全性的优势,两者互有优缺点。不过容器化是当下的趋势,相信随着技术的成熟,目前的隔离不彻底的问题也能解决,容器化走天下不是梦。












