
点击上方蓝色字体,选择“设为星标”
回复”资源“获取更多资源


点击右侧关注,大数据开发领域最强公众号!


大数据真好玩
点击右侧关注,大数据真好玩!

近日,有状态函数(Stateful Functions , statefun.io )宣布开源,它可以极大降低构建和编排分布式有状态应用程序的复杂性,集成了 Apache Flink 和函数即服务(Function-as-a-Service,FaaS)的流处理优点,为下一代事件驱动架构提供了强大的抽象能力。这篇博客将为开发者介绍有状态函数产生的原因、概念以及如何使用。
问题:有状态应用仍然很难
在 Kubernetes 和 FaaS 等技术的推动下,无状态计算的编排已经取得了长足进步,但是由于大多数产品主要关注的是计算,而不是状态,所以当涉及到有状态的分布式应用程序时,这些技术仍然不能很好得满足要求。此外,函数之间的交互仍然会为开发的整体易用性和分布式数据的一致性带来挑战。
Stateful Functions 是专门为突破这些限制而构建的,它让开发者能够定义松耦合、独立的函数,这些函数占用空间很小,可以在共享资源池中进行一致且可靠的交互。该框架由实现“Stateful Functions”的抽象 API(图 1)和基于 Apache Flink 用于分布式协调、通信和状态管理的运行时组成。
Stateful Functions API
该 API 基于 Stateful Functions,封装了业务逻辑的小功能片段,有点类似于 actors 。这些函数以虚拟实例的形态存在,虚拟实例通常是指应用程序中的每个实体(例如,每个用户都有一个虚拟实例),并且这些函数分布在碎片上,从而使应用程序具有开箱即用的水平可伸缩性。每个函数在局部变量中都有持久的用户定义状态,并且可以随意向其他函数(包括它自己)发送消息,并能保证只发送一次。
运行时(Runtime)
支持 Stateful Functions 的运行时是基于 Apache Flink 流处理的。状态保存在流处理引擎中,与计算位于同一位置,并能提供快速且一致的状态访问。状态的持久性和容错性是建立在 Flink 具有鲁棒性的分布快照模型上的。
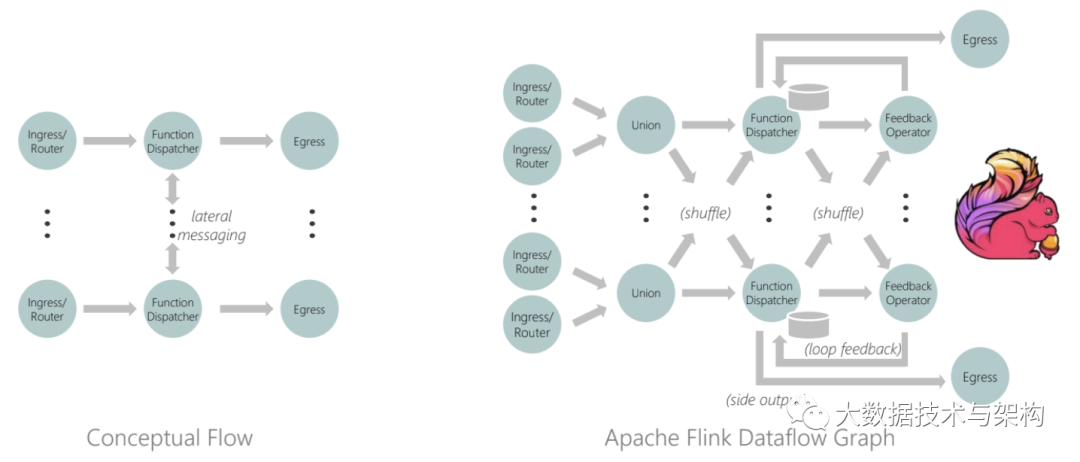
图 1
计算状态,而不是根据状态计算
该框架不是为了替代 FaaS 或者 Serverless,相反,Stateful Functions 的目的是提供一组类似于 Serverless 计算属性的功能,但这些功能是用于解决以状态为中心的问题。
以状态为中心(State-centric)
有状态函数主要用于衡量状态和不同状态与事件之间的交互,以促进这些交互的逻辑作为计算的主要焦点。事件驱动的应用程序需要处理交互状态机并且记录上下文信息,这非常适合以状态为中心的范例。
以计算为中心(Compute-centric)
另一方面,FaaS 和 Serverless 应用程序框架主要擅长弹性扩展专用计算资源。与状态和其他函数的交互,整合的不是很好,当然这也不是它们的核心优势。拟合用例中一个很好的例子是经典的“使 AWS Lambda 实现镜像的伸缩”。
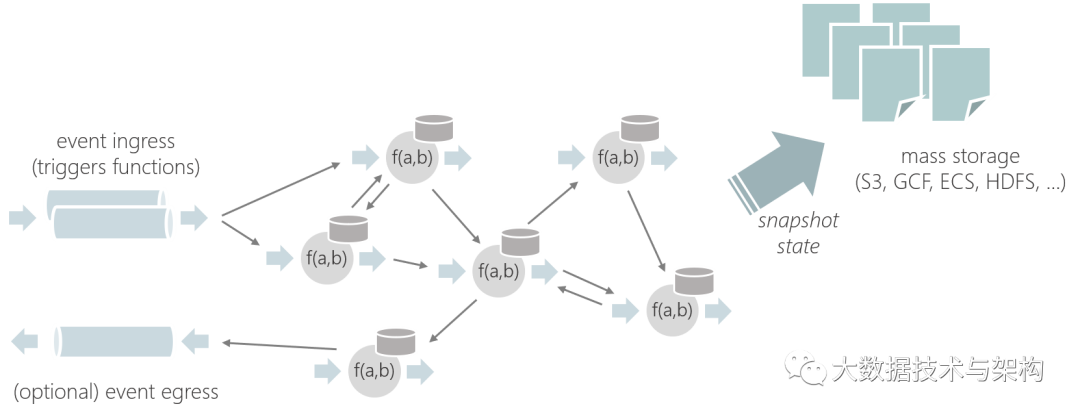
图 2
为了实现这一点,Stateful Functions API 下的运行时依赖于 Apache Flink 的流处理,并且扩展了其强大的状态管理和容错模型。容错模型的主要优点是状态和计算共存于同一网络,这意味着不需要记录每次往返,就可从外部存储系统(如 Cassandra、DynamoDB)中获取状态,也不需要使用特定的状态管理模式来实现一致性(如事件源、CQRS)。其他优点还包括:
不需要管理动态消息,也不需要维护复杂的复制或重新分区策略,因为持久性和为状态快照提供对象存储一样简单;
流(快速实时)处理和批(离线)处理的高吞吐量允许开发者模糊事件驱动应用程序和通用数据处理之间的界限。
Stateful Functions 对计算和存储的划分与经典的两层架构不同,它维护了一个短暂的状态 / 计算层(Apache Flink)和一个简单的持久化 blob 存储层(图 2)。在编程上,持久性是基于持久化值的概念,这使得每个函数实例都能够独立维护和跟踪容错状态。
扩展流处理范围
尽管Stateful Functions API 独立于Flink,但运行时是在Flink 的 DataStream API 之上构建的,并且使用了轻量版的过程函数(即访问状态的低级函数)来实现底层抽象。与vanilla Flink 相比,核心优势在于函数可以任意将事件发送给其他函数,而不仅仅是DAG 的下游。
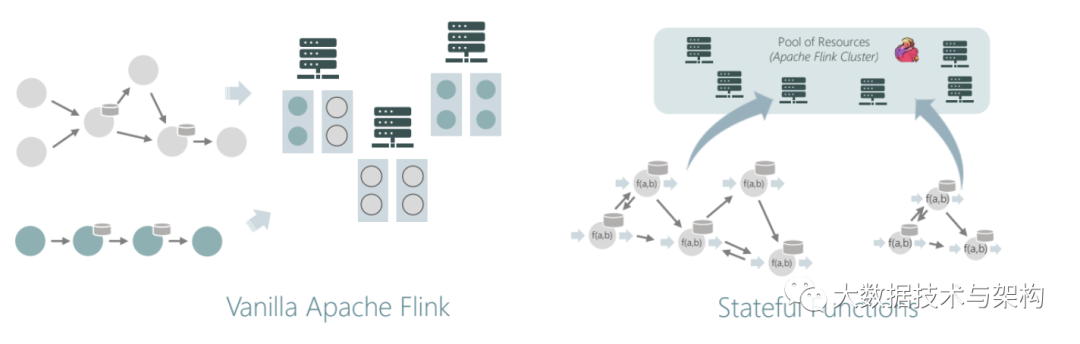
图3
Stateful Functions 应用程序通常是模块化的,包含了多个函数包,这些函数包可以一致且可靠地交互,并复用到一个 Flink 应用程序上(图 3)。这使得许多小工作可以共享相同的资源池,并根据需要加以利用,而无需预订高峰时可能需要的资源。在任何时候,绝大多数虚拟实例都是空闲的,不会消耗任何计算资源。


版权声明:
本文为大数据技术与架构整理,原作者独家授权。未经原作者允许转载追究侵权责任。
编辑|冷眼丶
微信公众号|import_bigdata
欢迎点赞+收藏+转发朋友圈素质三连

文章不错?点个【在看】吧!** 👇**
本文分享自微信公众号 - 大数据技术与架构(import_bigdata)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。










