

点击右侧关注,大数据开发领域最强公众号!


点击右侧关注,暴走大数据!

共同点
定性上讲,三者均为 Data Lake 的数据存储中间层,其数据管理的功能均是基于一系列的 meta 文件。meta 文件的角色类似于数据库的 catalog/wal,起到 schema 管理、事务管理和数据管理的功能。与数据库不同的是,这些 meta 文件是与数据文件一起存放在存储引擎中的,用户可以直接看到。这种做法直接继承了大数据分析中数据对用户可见的传统,但是无形中也增加了数据被不小心破坏的风险。一旦某个用户不小心删了 meta 目录,表就被破坏了,想要恢复难度非常大。
Meta 文件包含有表的 schema 信息。因此系统可以自己掌握 Schema 的变动,提供 Schema 演化的支持。Meta 文件也有 transaction log 的功能(需要文件系统有原子性和一致性的支持)。所有对表的变更都会生成一份新的 meta 文件,于是系统就有了 ACID 和多版本的支持,同时可以提供访问历史的功能。在这些方面,三者是相同的。
下面来谈一下三者的不同。
Hudi
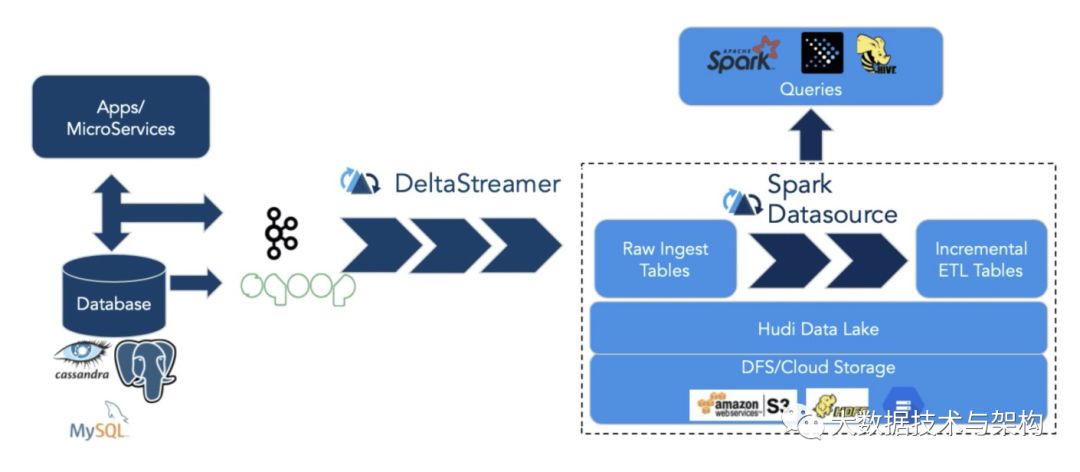
先说 Hudi。Hudi 的设计目标正如其名,Hadoop Upserts Deletes and Incrementals(原为 Hadoop Upserts anD Incrementals),强调了其主要支持 Upserts、Deletes 和 Incremental 数据处理,其主要提供的写入工具是 Spark HudiDataSource API 和自身提供的 DeltaStreamer,均支持三种数据写入方式:UPSERT,INSERT 和 BULK_INSERT。其对 Delete 的支持也是通过写入时指定一定的选项支持的,并不支持纯粹的 delete 接口。
其典型用法是将上游数据通过 Kafka 或者 Sqoop,经由 DeltaStreamer 写入 Hudi。DeltaStreamer 是一个常驻服务,不断地从上游拉取数据,并写入 hudi。写入是分批次的,并且可以设置批次之间的调度间隔。默认间隔为 0,类似于 Spark Streaming 的 As-soon-as-possible 策略。随着数据不断写入,会有小文件产生。对于这些小文件,DeltaStreamer 可以自动地触发小文件合并的任务。
在查询方面,Hudi 支持 Hive、Spark、Presto。
在性能方面,Hudi 设计了 HoodieKey ,一个类似于主键的东西。 HoodieKey 有 Min/Max 统计,BloomFilter,用于快速定位 Record 所在的文件。在具体做 Upserts 时,如果 HoodieKey 不存在于 BloomFilter,则执行插入,否则,确认 HoodieKey 是否真正存在,如果真正存在,则执行 update。这种基于 HoodieKey + BloomFilter 的 upserts 方法是比较高效的,否则,需要做全表的 Join 才能实现 upserts。对于查询性能,一般需求是根据查询谓词生成过滤条件下推至 datasource。Hudi 这方面没怎么做工作,其性能完全基于引擎自带的谓词下推和 partition prune 功能。
Hudi 的另一大特色是支持 Copy On Write 和 Merge On Read。前者在写入时做数据的 merge,写入性能略差,但是读性能更高一些。后者读的时候做 merge,读性能查,但是写入数据会比较及时,因而后者可以提供近实时的数据分析能力。
最后,Hudi 提供了一个名为 run_sync_tool 的脚本同步数据的 schema 到 Hive 表。Hudi 还提供了一个命令行工具用于管理 Hudi 表。
Iceberg
Iceberg 没有类似的 HoodieKey 设计,其不强调主键。上文已经说到,没有主键,做 update/delete/merge 等操作就要通过 Join 来实现,而 Join 需要有一个 类似 SQL 的执行引擎。Iceberg 并不绑定某个引擎,也没有自己的引擎,所以 Iceberg 并不支持 update/delete/merge。如果用户需要 update 数据,最好的方法就是找出哪些 partition 需要更新,然后通过 overwrite 的方式重写数据。Iceberg 官网提供的 quickstart 以及 Spark 的接口均只是提到了使用 Spark dataframe API 向 Iceberg 写数据的方式,没有提及别的数据摄入方法。至于使用 Spark Streaming 写入,代码中是实现了相应的 StreamWriteSupport ,应该是支持流式写入,但是貌似官网并未明确提及这一点。支持流式写入意味着有小文件问题,对于怎么合并小文件,官网也未提及。我怀疑对于流式写入和小文件合并,可能 Iceberg 还没有很好的生产 ready,因而没有提及(纯属个人猜测)。
在查询方面,Iceberg 支持 Spark、Presto。
Iceberg 在查询性能方面做了大量的工作。值得一提的是它的 hidden partition 功能。Hidden partition 意思是说,对于用户输入的数据,用户可以选取其中某些列做适当的变换(Transform)形成一个新的列作为 partition 列。这个 partition 列仅仅为了将数据进行分区,并不直接体现在表的 schema 中。例如,用户有 timestamp 列,那么可以通过 hour(timestamp) 生成一个 timestamp_hour 的新分区列。timestamp_hour 对用户不可见,仅仅用于组织数据。Partition 列有 partition 列的统计,如该 partition 包含的数据范围。当用户查询时,可以根据 partition 的统计信息做 partition prune。
除了 hidden partition,Iceberg 也对普通的 column 列做了信息收集。这些统计信息非常全,包括列的 size,列的 value count,null value count,以及列的最大最小值等等。这些信息都可以用来在查询时过滤数据。
Iceberg 提供了建表的 API,用户可以使用该 API 指定表明、schema、partition 信息等,然后在 Hive catalog 中完成建表。
Delta
我们最后来说 Delta。Delta 的定位是流批一体的 Data Lake 存储层,支持 update/delete/merge。由于出自 Databricks,spark 的所有数据写入方式,包括基于 dataframe 的批式、流式,以及 SQL 的 Insert、Insert Overwrite 等都是支持的(开源的 SQL 写暂不支持,EMR 做了支持)。与 Iceberg 类似,Delta 不强调主键,因此其 update/delete/merge 的实现均是基于 spark 的 join 功能。在数据写入方面,Delta 与 Spark 是强绑定的,这一点 Hudi 是不同的:Hudi 的数据写入不绑定 Spark(可以用 Spark,也可以使用 Hudi 自己的写入工具写入)。
在查询方面,开源 Delta 目前支持 Spark 与 Presto,但是,Spark 是不可或缺的,因为 delta log 的处理需要用到 Spark。这意味着如果要用 Presto 查询 Delta,查询时还要跑一个 Spark 作业。更为蛋疼的是,Presto 查询是基于 SymlinkTextInputFormat 。在查询之前,要运行 Spark 作业生成这么个 Symlink 文件。如果表数据是实时更新的,意味着每次在查询之前先要跑一个 SparkSQL,再跑 Presto。这样的话为何不都在 SparkSQL 里搞定呢?这是一个非常蛋疼的设计。为此,EMR 在这方面做了改进,支持了 DeltaInputFormat,用户可以直接使用 Presto 查询 Delta 数据,而不必事先启动一个 Spark 任务。
在查询性能方面,开源的 Delta 几乎没有任何优化。Iceberg 的 hidden partition 且不说,普通的 column 的统计信息也没有。Databricks 对他们引以为傲的 Data Skipping 技术做了保留。不得不说这对于推广 Delta 来说不是件好事。EMR 团队在这方面正在做一些工作,希望能弥补这方面能力的缺失。
Delta 在数据 merge 方面性能不如 Hudi,在查询方面性能不如 Iceberg,是不是意味着 Delta 一无是处了呢?其实不然。Delta 的一大优点就是与 Spark 的整合能力(虽然目前仍不是很完善,但 Spark-3.0 之后会好很多),尤其是其流批一体的设计,配合 multi-hop 的 data pipeline,可以支持分析、Machine learning、CDC 等多种场景。使用灵活、场景支持完善是它相比 Hudi 和 Iceberg 的最大优点。另外,Delta 号称是 Lambda 架构、Kappa 架构的改进版,无需关心流批,无需关心架构。这一点上 Hudi 和 Iceberg 是力所不及的。
总结
通过上面的分析能够看到,三个引擎的初衷场景并不完全相同,Hudi 为了 incremental 的 upserts,Iceberg 定位于高性能的分析与可靠的数据管理,Delta 定位于流批一体的数据处理。这种场景的不同也造成了三者在设计上的差别。尤其是 Hudi,其设计与另外两个相比差别更为明显。随着时间的发展,三者都在不断补齐自己缺失的能力,可能在将来会彼此趋同,互相侵入对方的领地。当然也有可能各自关注自己专长的场景,筑起自己的优势壁垒,因此最终谁赢谁输还是未知之数。
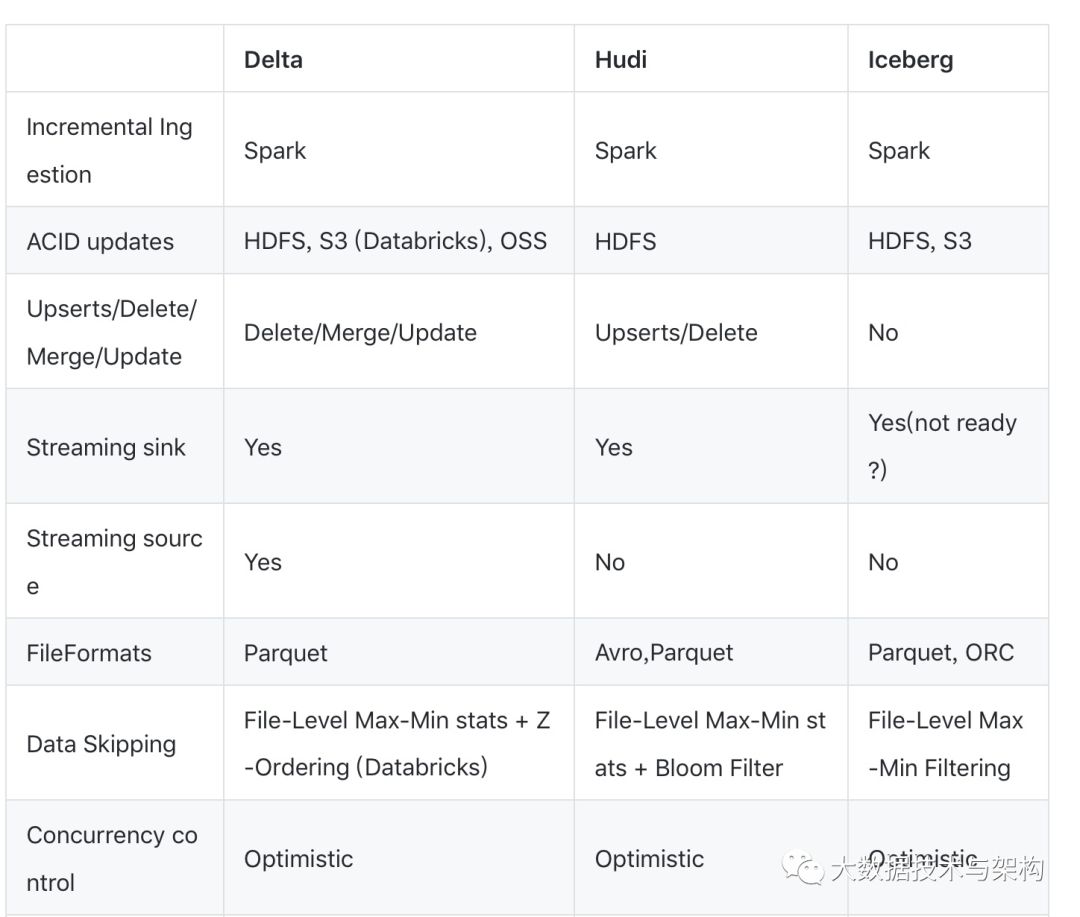
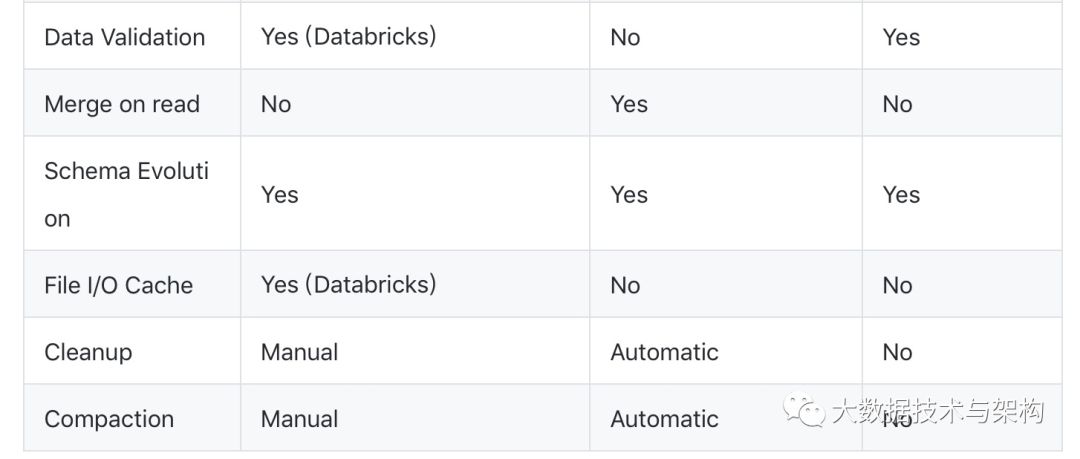
下表从多个维度对三者进行了总结,需要注意的是此表所列的能力仅代表至 2019 年底。
本文来源于云栖社区
https://yq.aliyun.com/articles/743514
作者: xy_xin
欢迎点赞+收藏+转发朋友圈素质三连



文章不错?点个【在看】吧!** 👇**
本文分享自微信公众号 - 大数据技术与架构(import_bigdata)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。











