
1. B站博人传评论数据爬取简介
今天想了半天不知道抓啥,去B站看跳舞的小姐姐,忽然看到了评论,那就抓取一下B站的评论数据,视频动画那么多,也不知道抓取哪个,选了一个博人传跟火影相关的,抓取看看。网址: https://www.bilibili.com/bangumi/media/md5978/?from=search&seid=16013388136765436883#short 在这个网页看到了18560条短评,数据量也不大,抓取看看,使用的还是scrapy。
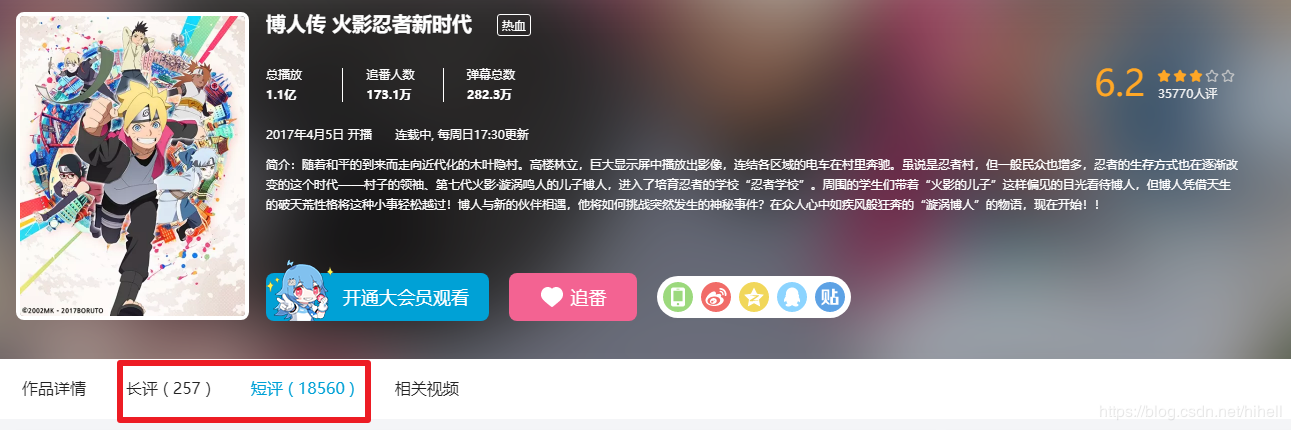
2. B站博人传评论数据案例---获取链接
从开发者工具中你能轻易的得到如下链接,有链接之后就好办了,如何创建项目就不在啰嗦了,我们直接进入主题。 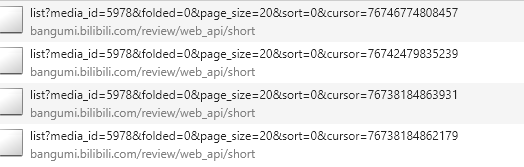
我在代码中的parse函数中,设定了两个yield一个用来返回items 一个用来返回requests。 然后实现一个新的功能,每次访问切换UA,这个点我们需要使用到中间件技术。
class BorenSpider(scrapy.Spider):
BASE_URL = "https://bangumi.bilibili.com/review/web_api/short/list?media_id=5978&folded=0&page_size=20&sort=0&cursor={}"
name = 'Boren'
allowed_domains = ['bangumi.bilibili.com']
start_urls = [BASE_URL.format("76742479839522")]
def parse(self, response):
print(response.url)
resdata = json.loads(response.body_as_unicode())
if resdata["code"] == 0:
# 获取最后一个数据
if len(resdata["result"]["list"]) > 0:
data = resdata["result"]["list"]
cursor = data[-1]["cursor"]
for one in data:
item = BorenzhuanItem()
item["author"] = one["author"]["uname"]
item["content"] = one["content"]
item["ctime"] = one["ctime"]
item["disliked"] = one["disliked"]
item["liked"] = one["liked"]
item["likes"] = one["likes"]
item["user_season"] = one["user_season"]["last_ep_index"] if "user_season" in one else ""
item["score"] = one["user_rating"]["score"]
yield item
yield scrapy.Request(self.BASE_URL.format(cursor),callback=self.parse)
3. B站博人传评论数据案例---实现随机UA
第一步, 在settings文件中添加一些UserAgent,我从互联网找了一些
USER_AGENT_LIST=[
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
第二步,在settings文件中设置 “DOWNLOADER_MIDDLEWARES”
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
#'borenzhuan.middlewares.BorenzhuanDownloaderMiddleware': 543,
'borenzhuan.middlewares.RandomUserAgentMiddleware': 400,
}
第三步,在 middlewares.py 文件中导入 settings模块中的 USER_AGENT_LIST 方法
from borenzhuan.settings import USER_AGENT_LIST # 导入中间件
import random
class RandomUserAgentMiddleware(object):
def process_request(self, request, spider):
rand_use = random.choice(USER_AGENT_LIST)
if rand_use:
request.headers.setdefault('User-Agent', rand_use)
好了,随机的UA已经实现,你可以在parse函数中编写如下代码进行测试
print(response.request.headers)
4. B站博人传评论数据----完善item
这个操作相对简单,这些数据就是我们要保存的数据了。!
author = scrapy.Field()
content = scrapy.Field()
ctime = scrapy.Field()
disliked = scrapy.Field()
liked = scrapy.Field()
likes = scrapy.Field()
score = scrapy.Field()
user_season = scrapy.Field()
5. B站博人传评论数据案例---提高爬取速度
在settings.py中设置如下参数:
# Configure maximum concurrent requests performed by Scrapy (default: 16)
CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 1
# The download delay setting will honor only one of:
CONCURRENT_REQUESTS_PER_DOMAIN = 16
CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
COOKIES_ENABLED = False
解释说明
一、降低下载延迟
DOWNLOAD_DELAY = 0
将下载延迟设为0,这时需要相应的防ban措施,一般使用user agent轮转,构建user agent池,轮流选择其中之一来作为user agent。
二、多线程
CONCURRENT_REQUESTS = 32 CONCURRENT_REQUESTS_PER_DOMAIN = 16 CONCURRENT_REQUESTS_PER_IP = 16
scrapy网络请求是基于Twisted,而Twisted默认支持多线程,而且scrapy默认也是通过多线程请求的,并且支持多核CPU的并发,我们通过一些设置提高scrapy的并发数可以提高爬取速度。
三、禁用cookies
COOKIES_ENABLED = False
6. B站博人传评论数据案例---保存数据
最后在pipelines.py 文件中,编写保存代码即可
import os
import csv
class BorenzhuanPipeline(object):
def __init__(self):
store_file = os.path.dirname(__file__)+'/spiders/bore.csv'
self.file = open(store_file,"a+",newline="",encoding="utf-8")
self.writer = csv.writer(self.file)
def process_item(self, item, spider):
try:
self.writer.writerow((
item["author"],
item["content"],
item["ctime"],
item["disliked"],
item["liked"],
item["likes"],
item["score"],
item["user_season"]
))
except Exception as e:
print(e.args)
def close_spider(self, spider):
self.file.close()
运行代码之后,发现过了一会报错了 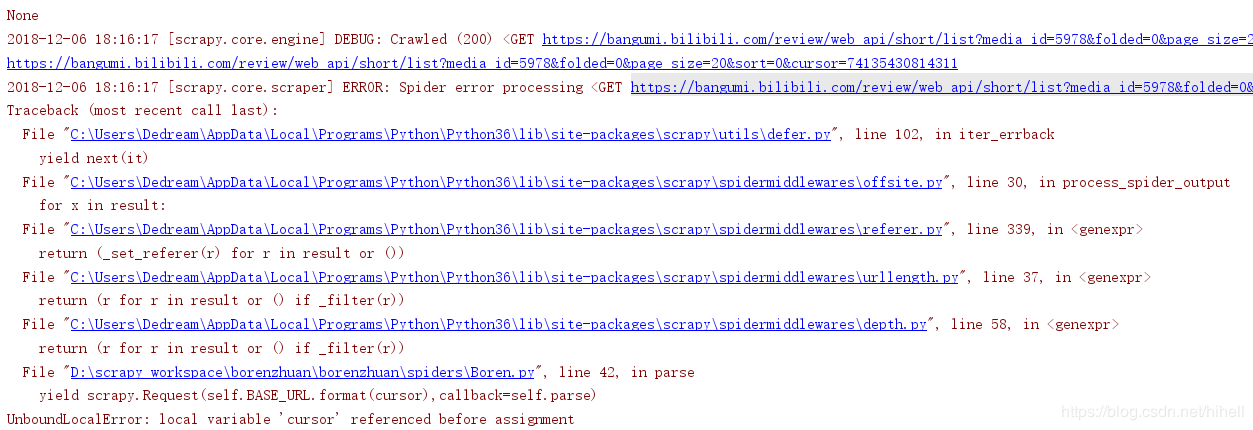
去看了一眼,原来是数据爬取完毕~!!!











