
[TOC]
**来源: ** [nusr/hacker-laws-zh](https://github.com/nusr/hacker-laws-zh)
这是[hacker-laws](https://github.com/dwmkerr/hacker-laws) 的中文翻译,对开发人员有用的定律,理论,原则和模式(Laws, Theories, Principles and Patterns that developers will find useful.)。
为了方便阅读,维基百科增加了中文链接!
英文链接表示 hacker-laws 项目尚未完成。
中国无法访问维基百科说明
喜欢点 star ,关注点 watch,贡献点 fork 。
介绍
当谈论到开发时,人们会谈到许多定律。 这个仓库收录了一些最常见的定律。请分享这个仓库并提交 PR !
❗: 这个仓库包含对一些定律、原则以及模式的解释,但不提倡其中任何一个。 它们的应用始终存在着争论,并且很大程度上取决于你正在做什么。
定律
现在我们开始吧!
阿姆达尔定律 (Amdahl's Law)
阿姆达尔定律是一个显示计算任务潜在加速能力的公式。这种能力可以通过增加系统资源来实现。 通常用于并行计算中,它可以预测增加处理器数量的实际好处。增加处理器数量会受到程序并行性的限制。
举例说明:如果程序由两部分组成,部分 A 必须由单个处理器执行,部分 B 可以并行运行,那么我们向执行程序的系统添加多个处理器只能获得有限的好处。 它可以极大地提升部分 B 的运行速度,但部分 A 的运行速度将保持不变。
下图展示了运行速度的潜能:
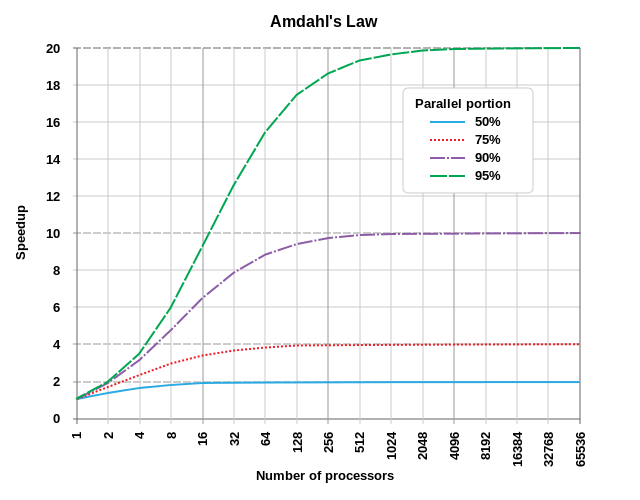
(图片来源: By Daniels220 at English Wikipedia, Creative Commons Attribution-Share Alike 3.0 Unported, https://en.wikipedia.org/wiki/File:AmdahlsLaw.svg)
可以看出,50% 并行化的程序仅仅受益于 10 个处理单元,而 95% 并行化的程序可以通过超过一千个处理单元显著提升速度。
随着摩尔定律减慢,以及单个处理器的速度增加缓慢,并行化是提高性能的关键。 图形编程是一个很好的例子,现代着色器可以并行渲染单个像素或片段。这也是为什么现代显卡通常具有数千个处理核心(GPU 或着色器单元)的原因。
参见:
- 布鲁克斯法则
- 摩尔定律
布鲁克斯法则 (Brooks's Law)
布鲁克斯是《人月神话》的作者。
软件开发后期,添加人力只会使项目开发得更慢。
这个定律表明,在许多情况下,试图通过增加人力来加速延期项目的交付,将会使项目交付得更晚。 布鲁克斯也明白,这是一种过度简化。但一般的推理是,新资源的增加时间和通信开销,会使开发速度减慢。 而且,许多任务是不可分的,比如更多的资源容易分配,这也意味着潜在的速度增加也更低。
谚语 九个女人不能在一个月内生一个孩子 与布鲁克斯法则同出一辙,特别是某些不可分割或者并行的工作。
参见:
- Death March
康威定律 (Conway's Law)
系统的技术边界受制于组织的结构。在改进组织时,通常会提到它。康威定律表明,如果一个组织被分散成许多小型、无联系的单元,那么它开发的软件也是小而分散的。 如果一个组织更多地垂直建立在特性或服务周围,那么软件系统也会反映这一点。
参见:
- The Spotify Model
侯世达定律 (Hofstadter's Law)
即使考虑到侯世达定律,它也总是比你预期的要长。
在估计需要多长时间时,您可能会听到此定律。软件开发中似乎不言而喻,我们往往不能准确地估计需要多长时间才能完成。
技术成熟度曲线 (The Hype Cycle & Amara's Law)
我们倾向于过高估计技术在短期内的影响,并低估长期效应。
(罗伊阿马拉)
技术成熟度曲线是高德纳咨询公司最初制作的技术兴起和发展的直观表现。一图顶千言:
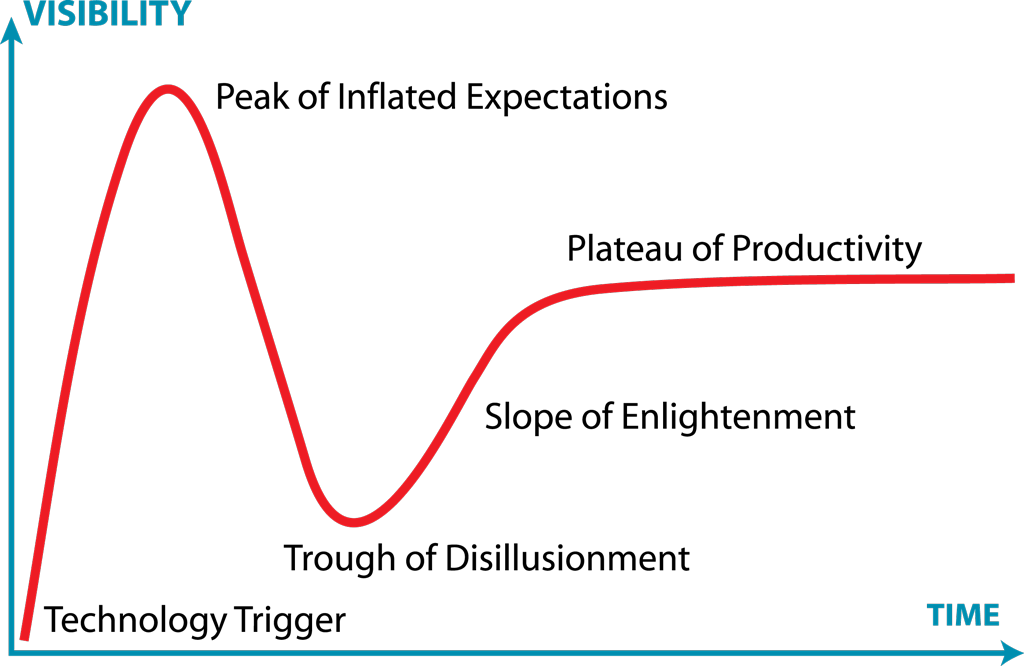
(图片来源: By Jeremykemp at English Wikipedia, CC BY-SA 3.0, https://commons.wikimedia.org/w/index.php?curid=10547051)
简而言之,这个周期表明,新技术及其潜在影响通常会引发一阵浪潮。 团队快速使用这些新技术,有时会对结果感到失望。 这可能是因为该技术还不够成熟,或者现实应用还没有完全实现。 经过一段时间后,技术的能力提高了,使用它的实际机会会增加,最终团队可以提高工作效率。 罗伊·阿马拉简洁地总结了这一点:我们倾向于高估技术短期内的影响,并低估长期效应。
隐式接口定律 (Hyrum's Law)
有足够数量 API 的用户, 你在合同中的承诺并不重要: 你系统的所有可观察行为 将取决于某人。
(Hyrum Wright)
隐式接口定律表明,当你拥有足够数量的 API 用户时,API 的所有行为(即使那些未被定义为公共说明的一部分)最终都会被某人所依赖。 一个简单的例子,例如 API 的响应时间这种非功能性因素。 一个更微妙的例子是:用户使用正则表达式判断错误信息的类型。 即使 API 的公共说明没有说明消息的内容,来指示用户错误的类型。一些用户可能会使用该消息,并且更改消息,实际上会破坏用户的 API。
参见:
- 漏洞抽象定律
摩尔定律 (Moore's Law)
集成电路中的晶体管数量大约每两年翻一番。
通常用于说明半导体和芯片技术提高的绝对速度。从 20 世纪 70 年代到 21 世纪后期,摩尔的预测被证明是高度准确的。 近年来,这种趋势略有变化,部分原因受到[量子隧穿效应](https://zh.wikipedia.org/wiki/%E9%87%8F%E5%AD%90%E7%A9%BF%E9%9A%A7%E6%95%88%E6%87%89)影响。 然而,并行化计算的进步以及半导体技术和量子计算潜在的革命性变化,可能意味着摩尔定律在未来几十年内继续保持正确。
帕金森定理 (Parkinson's Law)
在工作能够完成的时限内,工作量会一直增加,直到所有可用时间都被填充为止。
基于官僚机构的研究背景,该定律被应用于软件开发中。该理论认为,团队在截止日期之前效率低下,然后在截止日期前赶紧完成工作,从而使实际截止日期有些随意。
将这个定理与[侯世达定律](#侯世达定律)相结合,则会获得更加悲观的观点: 工作将扩大以填补所需时间,并且需要比预期更长的时间。
参见:
- 侯世达定律
普特定律 (Putt's Law)
技术由两类人主导,一类是管理人员, 一类是技术人员。
普特定律常常遵循普特推论:
每个技术层次都会发展地逆转。
这些结论表明,由于各种选择标准和群体组织的趋势,技术组织的工作层面将有一些技术人员,以及一些不了解复杂性和挑战的管理人员。 这种现象可能是由于 The Peter Principe 或者 Dilbert's Law 造成的。
但是,应该强调的是,诸如此类的定律是一种广泛的概括,可能适用于某些类型的组织,而不适用于其他组织。
参见:
- The Peter Principe
- Dilbert's Law.
复杂性守恒定律 (The Law of Conservation of Complexity)
该定律表明系统中存在着一定程度的复杂性,并且不能减少。
系统中的某些复杂性是无意的。 这是由于结构不良,错误或者糟糕的建模造成的。 可以减少以及消除无意的复杂性。 然而,由于待解决问题固有的复杂性,某些复杂性是内在的。 这种复杂性可以移动,但不能消除。
一个该定律的有趣元素是,即使简化整个系统,内在的复杂性也不会降低。它会移动到用户,并且用户必须以更复杂的方式行事。
漏洞抽象定律 (The Law of Leaky Abstractions)
在某种程度上,所有非平凡的抽象都是漏洞。
(乔尔斯 波尔斯基)
该定律指出,通常用于简化复杂系统的抽象,某些情况下将在底层系统有漏洞,这使得抽象表现为意外的方式。
例如加载文件并读取其内容。 文件系统 API 是较低级别内核系统的抽象,它们本身是与磁盘(或 SSD 的闪存)上的数据更改相关的物理过程抽象。 在大多数情况下,处理文件(如二进制数据流)的抽象将起作用。 但是,对于磁盘驱动器,顺序读取数据将比随机访问快得多(由于页面错误的开销增加)。但对于 SSD 驱动器,此开销不会出现。 需要理解基础细节来处理这种情况(例如,数据库索引文件的良好结构可以减少随机访问的开销),开发人员需要合理的抽象,来处理不同的细节。
当引入的抽象更多时,上面的例子会变得更复杂。 Linux 操作系统允许通过网络访问文件,但在本地表示为普通文件。 如果存在网络故障,这种抽象将有漏洞。 如果开发人员将这些文件视为普通文件,而不考虑它们可能会受到网络延迟和故障的影响,那么解决方案就会出错。
描述该定律的文章表明,过度依赖抽象,加上对底层过程的理解不足,实际上使得问题在某些情况下更加复杂。
参见:
- 隐式接口定律
真实的例子:
- Photoshop 启动缓慢 。我过去遇到过一个问题,就是 Photoshop 启动非常慢,有时需要几分钟。 问题好像是 Photoshop 启动时,会读取当前默认打印机的一些信息。 但是,如果该打印机实际上是一台网络打印机,则可能需要很长的时间。 将网络打印机与本地打印机当作同样的抽象,导致连接不良的情况下出现问题。
帕金森琐碎定理 (The Law of Triviality)
该定理显示,群体将给予更多的时间和注意力来处理琐碎的问题,而不是用来处理严肃而实质性的问题。
常见的虚构例子是委员会批准核电站的计划,他们大部分时间都在讨论自行车棚的结构,而不是电厂本身等更为重要的设计。 如果没有大量的专业知识或者准备,很难给非常大的复杂主题讨论提供宝贵的意见。 但是,人们希望看到宝贵的意见。 因此,倾向于将过多的时间集中在小细节上,这很容易推理,但不一定特别重要。
上面的虚构例子导致使用Bike Shedding这个词,作为在琐碎细节上浪费时间的表达。
Unix 哲学 (The Unix Philosophy)
Unix 哲学是软件组件应该很小,并专注于做一件特定的事情。 将小型、简单以及定义良好的单元组合在一起,而不是使用大型、复杂以及多用途程序,可以更轻松地构建系统。
像微服务架构这种现代实践可以被认为是这种哲学的应用,其中服务很小,集中于做一件特定的事情,由简单的构建块组成复杂的行为。
Spotify 模型 (The Spotify Model)
Spotify 模型是团队和组织结构的一种方法,已被 Spotify 实验室推广。 在此模型中,团队围绕功能而非技术进行组织。
Spotify 模型还普及了部落、行会以及章节的概念,这些是其组织结构的其他组成部分。
沃德勒定律 (Wadler's Law)
任何语言设计中,讨论下面列表中某个要素所花费的总时间与其位置上的两个要素成正比。
- 语义
- 语法
- 词法
- 评论词法
(简而言之,对于语义上花费的每一个小时,将在评论词法上花费 8 小时)。
与 帕金森琐碎定理 类似, 沃德勒定律指出,在设计语言时,与这些特征的重要性相比,花在语言结构上的时间相当多。
参见:
- 帕金森琐碎定理
原则
原则通常是与设计相关的准则。
鲁棒性原则 (The Robustness Principle)
对自己所做的事情要保守,对自己接受的人要宽容。
通常应用于服务器应用程序开发中,该原则指出,你发送给其他人的内容应尽可能小且符合要求,并且处理不符合要求的输入。
该原则的目标是构建稳健的系统。如果可以理解意图,它们可以处理不良的输入。 但是,接受错误格式的输入可能存在安全隐患,特别是此类的输入未经过充分测试。
SOLID
这是一个缩写,指的是:
- S:单一功能原则 (The Single Responsibility Principle)
- O:开闭原则 (The Open/Closed Principle)
- L:里氏替换原则 (The Liskov Substitution Principle)
- I:接口隔离原则 (The Interface Segregation Principle)
- D:依赖反转原则 (The Dependency Inversion Principle)
这些是 Object-Oriented Programming 的关键原则。 诸如此类的设计原则能够帮助开发人员构建更易于维护的系统。
单一功能原则 (The Single Responsibility Principle)
每个模块或者类只应该有一项功能。
SOLID 的第一个原则。 这个原则表明模块后者类只应该做一件事。 实际上,这意味着对程序功能的单个小更改,应该只需要更改一个组件。 例如,更改密码验证复杂性的方式应该只需要更改程序的一部分。
理论上讲,这使代码更健壮,更容易更改。 知道正在更改的组件只有一个功能,这意味着测试更改更容易。 使用前面的例子,更改密码复杂性组件应该只影响与密码复杂性相关的功能。 变更具有许多功能的组件可能要困难得多。
参见:
- Object-Orientated Programming
- SOLID
开闭原则 (The Open/Closed Principle)
实体应开放扩展并关闭修改。
SOLID 的第二个原则。 这个原则指出实体(可以是类,模块,函数等)应该能够使它们的行为进行扩展,但是它们的扩展行为不应该被修改。
举一个假设的例子,想象一个能够将 Markdown 转换为 HTML 的模块。 如果可以扩展模块以处理新的 markdown 特征,而无需修改内部模块,则可以认为是开放扩展。 如果用户不能修改模块以处理现有的 Markdown 特征,那么它被认为是关闭修改。
这个原则与面向对象编程紧密相关,我们可以设计对象以便于扩展,但是可以避免以意想不到的方式改变其现有对象的行为。
参见:
- Object-Orientated Programming
- SOLID
里氏替换原则 (The Liskov Substitution Principle)
可以在不破坏系统的情况下,用子类型替换类型。
SOLID 的第三个原则。 该原则指出,如果组件依赖于类型,那么它应该能够使用该类型的子类型,而不会导致系统失败或者必须知道该子类型的详细信息。
举个例子,假设我们有一个方法,读取 XML 文档。 如果该方法使用基类型 file,则从 file 派生的任何内容,都能用在该方法中。 如果 file 支持反向搜索,并且 xml 解析器使用该函数,但是派生类型 network file 尝试反向搜索时失败,则 network file 将违反该原则。
该原则与面向对象编程特别有关,必须仔细建模类型层次,以避免混淆系统用户。
参见
- Object-Orientated Programming
- SOLID
接口隔离原则 (The Interface Segregation Principle)
不应该强迫客户端依赖它不使用的方法。
SOLID 的第四个原则。 该原则指出组件的消费者不应该依赖于它实际上不使用的组件功能。
举一个例子,假设我们有一个方法,读取 XML 文档。 它只需要读取文件中的字节,向前移动或向后移动。 如果由于文件结构不相关(例如更新文件安全性的权限模型),需要更新此方法,则原则已失效。 文件最好实现 搜索流 接口,并让 XML 读取器使用它。
该原则与面向对象编程紧密相关,其中接口,层次结构和抽象类型用于不同组件的 minimise the coupling。 Duck typing 是一种通过消除显式接口来强制执行该原则的方法。
参见
- Object-Orientated Programming
- SOLID
- Duck Typing
- Decoupling
依赖反转原则 (The Dependency Inversion Principle)
高级模块不应该依赖于低级实现。
SOLID 的第五个原则。 该原则指出,更高级别的协调组件不应该知道其依赖关系的细节。
举个例子,假设我们有一个从网站读取元数据的程序。我们假设主要组件必须知道下载网页内容的组件,以及可以读取元数据的组件。如果我们考虑依赖反转,主要组件将仅依赖于可以获取字节数据的抽象组件,然后是一个能够从字节流中读取元数据的抽象组件。主要组件不需要了解 TCP、IP、HTTP、HTML 等。
这个原则很复杂,因为它似乎可以反转系统的预期依赖性(因此得名)。实践中,这也意味着,单独的编排组件必须确保抽象类型的正确实现被使用(例如在前面的例子中,必须提供元数据读取器组件、HTTP 文件下载功能和 HTML 元标签读取器)。然后,这涉及诸如 Inversion of Control 和 Dependency Injection 之类的模式。
参见:
- Object-Orientated Programming
- SOLID
- Inversion of Control
- Dependency Injection
TODO
嗨!如果你读到这里,点击了一个我尚未编写的主题链接,我感到抱歉。 这是正在进行中的工作!
随意提 Issue 获取更多详细信息,或者 Pull Request 提交你提议的主题。
**敲黑板:** 更多干货可关注 公号「大白技术控」,持续输出优质的 技术 文章~
作者简介:Bravo Yeung,计算机硕士,知乎干货答主(获81K 赞同, 38K 感谢, 235K 收藏)。曾在国内 Top3互联网视频直播公司工作过,后加入一家外企做软件开发至今。
如需转载,请加微信 iMath7 申请开白!
欢迎在留言区留下你的观点,一起讨论提高。如果今天的文章让你有新的启发,学习能力的提升上有新的认识,欢迎转发分享给更多人。

文末彩蛋
微信后台回复“asp”,给你:一份全网最强的ASP.NET学习路线图。
回复“cs”,给你:一整套 C# 和 WPF 学习资源!
回复“core”,给你:2019年dotConf大会上发布的.NET core 3.0学习视频!











