
JDBC规范与ShardingSphere
ShardingSphere是一种典型的客户端分片解决方案,而客户端分片的实现方式之一就是重写JDBC规范。
JDBC 规范简介
JDBC(Java Database Connectivity)的设计初衷是提供一套用于各种数据库的统一标准,而不同的数据库厂家共同遵守这套标准,并提供各自的实现方案供应用程序调用。JDBC规范具有完整的架构体系,如下图:
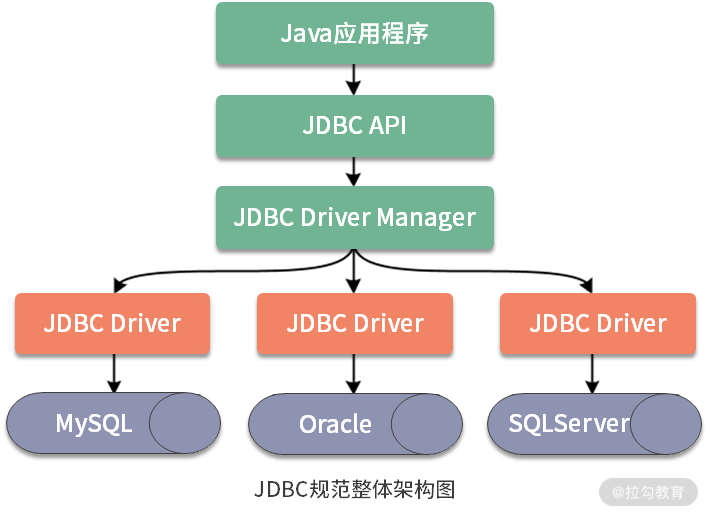
对于开发人员而言,JDBC API是我们访问数据库的主要途径,也是ShardingSphere重写JDBC规范并添加分片功能的入口。 JDBC开发一个访问数据库的处理流程,常见的代码风格如下:
// 创建池化的数据源
PooledDataSource dataSource = new PooledDataSource ();
// 设置MySQL Driver
dataSource.setDriver ("com.mysql.jdbc.Driver");
// 设置数据库URL、用户名和密码
dataSource.setUrl ("jdbc:mysql://localhost:3306/test");
dataSource.setUsername ("root");
dataSource.setPassword ("root");
// 获取连接
Connection connection = dataSource.getConnection();
// 执行查询
PreparedStatement statement = connection.prepareStatement ("select * from user");
// 获取查询结果应该处理
ResultSet resultSet = statement.executeQuery();
while (resultSet.next()) {
…
}
// 关闭资源
statement.close();
resultSet.close();
connection.close();
DataSource
DataSource 在JDBC规范中代表的是一种数据源,核心作用是获取数据库连接对象Connection。在JDBC规范中,实际可以通过DriverManager获取Connection。我们知道获取Connection的过程需要建立与数据库之间的连接,而这个过程会产生较大的系统开销。
为了提高性能,通常会建立一个中间层,该中间层将DriverManager生成的Connection存放到连接池中,然后从池中获取Connection,可以认为,DataSource就是这样一个中间层。在日常开发过程中,我们通常都会基于DataSource来获取Connection。而在ShardingSphere中,暴露给业务开发人员的同样是一个经过增强的DataSource对象。DataSource接口的定义是这样的:
public interface DataSource extends CommonDataSource, Wrapper {
Connection getConnection() throws SQLException;
Connection getConnection(String username, String password)
throws SQLException;
}
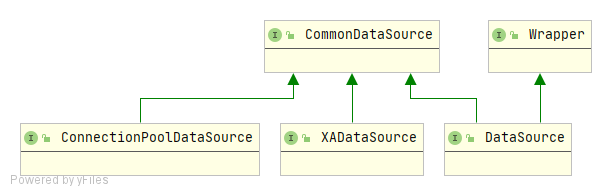
其中,DataSource是官方定义的获取Connection的基础接口,ConnectionPoolDataSource是从连接池ConnectionPool中获取的Connection接口。而XADataSource则用来实现在分布式事务环境下获取Connection。
DataSource 接口同时还继承了一个 Wrapper 接口。从接口的命名上看,可以判断该接口应该起到一种包装器的作用,事实上,由于很多数据库供应商提供了超越标准 JDBC API 的扩展功能,所以,Wrapper 接口可以把一个由第三方供应商提供的、非 JDBC 标准的接口包装成标准接口。以 DataSource 接口为例,如果我们想要实现自己的数据源 MyDataSource,就可以提供一个实现了 Wrapper 接口的 MyDataSourceWrapper 类来完成包装和适配:

在JDBC规范中,除了DataSource之外,Connection、Statement、ResultSet等核心对象也都继承了这个接口。显然,ShardingSphere提供的就是非JDBC 标准的接口,所以也应该会用到这个Wrapper接口,并提供了类似的实现方案。
Connection
DataSource的目的是获取Connection对象,我们可以把Connection理解为一种会话(Session)机制。 Connection 代表一个数据库连接,负责完成与数据库之间的通信。所有 SQL 的执行都是在某个特定 Connection 环境中进行的,同时它还提供了一组重载方法,分别用于创建 Statement 和 PreparedStatement。另一方面,Connection 也涉及事务相关的操作,为了实现分片操作,ShardingSphere 同样也实现了定制化的 Connection 类 ShardingConnection。
statement
JDBC 规范中的 Statement 存在两种类型,一种是普通的 Statement,一种是支持预编译的 PreparedStatement。所谓预编译,是指数据库的编译器会对 SQL 语句提前编译,然后将预编译的结果缓存到数据库中,这样下次执行时就可以替换参数并直接使用编译过的语句,从而提高 SQL 的执行效率。当然,这种预编译也需要成本,所以在日常开发中,对数据库只执行一次性读写操作时,用 Statement 对象进行处理比较合适;而当涉及 SQL 语句的多次执行时,可以使用 PreparedStatement。
如果需要查询数据库中的数据,只需要调用 Statement 或 PreparedStatement 对象的 executeQuery 方法即可,该方法以 SQL 语句作为参数,执行完后返回一个 JDBC 的 ResultSet 对象。当然,Statement 或 PreparedStatement 中提供了一大批执行 SQL 更新和查询的重载方法。在 ShardingSphere 中,同样也提供了 ShardingStatement 和 ShardingPreparedStatement 这两个支持分片操作的 Statement 对象。
ResultSet
一旦通过 Statement 或 PreparedStatement 执行了 SQL 语句并获得了 ResultSet 对象后,那么就可以通过调用 Resulset 对象中的 next() 方法遍历整个结果集。对于分库分表操作而言,因为涉及从多个数据库或数据表中获取目标数据,势必需要对获取的结果进行归并。因此,ShardingSphere 中也提供了分片环境下的 ShardingResultSet 对象。
总结
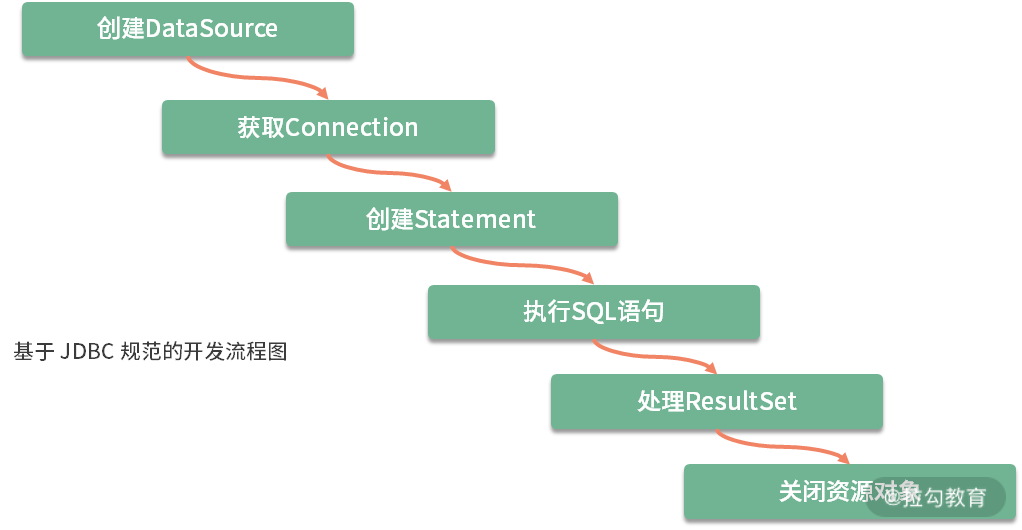
基于JDBC规范进行数据库访问的开发流程图。
基于适配器模式的JDBC重写实现方案
在 ShardingSphere 中,实现与 JDBC 规范兼容性的基本策略就是采用了设计模式中的适配器模式(Adapter Pattern)。适配器模式通常被用作连接两个不兼容接口之间的桥梁,涉及为某一个接口加入独立的或不兼容的功能。
作为一套适配 JDBC 规范的实现方案,ShardingSphere 需要对上面介绍的 JDBC API 中的 DataSource、Connection、Statement 及 ResultSet 等核心对象都完成重写。虽然这些对象承载着不同功能,但重写机制应该是共通的,否则就需要对不同对象都实现定制化开发,显然,这不符合我们的设计原则。为此,ShardingSphere 抽象并开发了一套基于适配器模式的实现方案,整体结构是这样的,如下图所示:
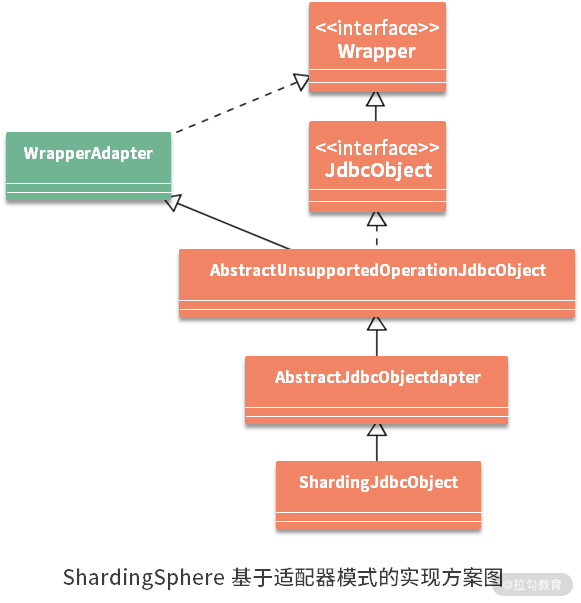
首先,我们看到这里有一个JdbcObject 接口,这个接口泛指JDBC API 中的 DataSource、Connection、Statement等核心接口。 这些接口都继承自包装器Wrapper接口。ShardingSphere为这个Wrapper接口提供了一个实现类WrapperAdapter。
ShardingSphere基于适配器模式的实现方案图的底部,有一个ShardingJdbcObject类的定义。这个类也是一种泛指,代表ShardingSphere中用于分片的ShardingDataSource、ShardingConnection、ShardingStatement等对象。
最后发现 ShardingJdbcObject 继承自一个 AbstractJdbcObjectAdapter,而 AbstractJdbcObjectAdapter 又继承自 AbstractUnsupportedOperationJdbcObject,这两个类都是抽象类,而且也都泛指一组类。两者的区别在于,AbstractJdbcObjectAdapter 只提供了针对 JdbcObject 接口的一部分实现方法,这些方法是我们完成分片操作所需要的。而对于那些我们不需要的方法实现,则全部交由 AbstractUnsupportedOperationJdbcObject 进行实现,这两个类的所有方法的合集,就是原有 JdbcObject 接口的所有方法定义。
ShardingSphere重写JDBC规范示例:ShardingConnection
ShardingSphere 的分片引擎中提供了一系列 ShardingJdbcObject 来支持分片操作,包括 ShardingDataSource、ShardingConnection、ShardingStatement、ShardingPreparedStament 等。这里以最具代表性的 ShardingConnection 为例,来讲解它的实现过程。请注意,今天我们关注的还是重写机制,不会对 ShardingConnection 中的具体功能以及与其他类之间的交互过程做过多展开讲解。
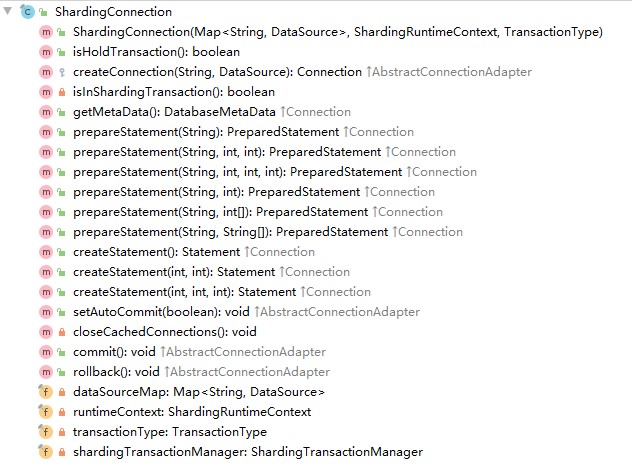
ShardingConnection 类的一条类层结构支线就是适配器模式的具体应用,这部分内容的类层结构与前面介绍的重写机制的类层结构是完全一致的,如下图所示: 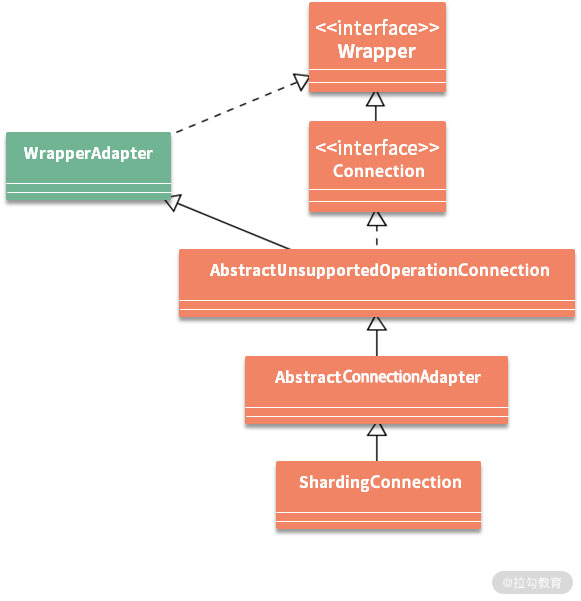
AbstractConnectionAdapter
我们首先来看看 AbstractConnectionAdapter 抽象类,ShardingConnection 直接继承了它。在 AbstractConnectionAdapter 中发现了一个 cachedConnections 属性,它是一个 Map 对象,该对象其实缓存了这个经过封装的 ShardingConnection 背后真实的 Connection 对象。如果我们对一个 AbstractConnectionAdapter 重复使用,那么这些 cachedConnections 也会一直被缓存,直到调用 close 方法。可以从 AbstractConnectionAdapter 的 getConnections 方法中理解具体的操作过程:
public final List<Connection> getConnections(final ConnectionMode connectionMode, final String dataSourceName, final int connectionSize) throws SQLException {
// 获取DataSource
DataSource dataSource = getDataSourceMap().get(dataSourceName);
Preconditions.checkState(null != dataSource, "Missing the data source name: '%s'", dataSourceName);
Collection<Connection> connections;
// 根据dataSourceName 从cachedConnections中获取connections
synchronized (cachedConnections) {
connections = cachedConnections.get(dataSourceName);
}
List<Connection> result;
// 如果connections多于想要的connectionsSize,则只获取所需部分
if (connections.size() >= connectionSize) {
result = new ArrayList<>(connections).subList(0, connectionSize);
} else if (!connections.isEmpty()) { // 如果connections不够
result = new ArrayList<>(connectionSize);
result.addAll(connections);
// 创建不够的 connections
List<Connection> newConnections = createConnections(dataSourceName, connectionMode, dataSource, connectionSize - connections.size());
result.addAll(newConnections);
synchronized (cachedConnections) {
// 将新创建的connections也放入缓存中进行管理
cachedConnections.putAll(dataSourceName, newConnections);
}
} else {
// 如果缓存中没有对应dataSource的Connections,同样进行创建并放入到缓存中
result = new ArrayList<>(createConnections(dataSourceName, connectionMode, dataSource, connectionSize));
synchronized (cachedConnections) {
cachedConnections.putAll(dataSourceName, result);
}
}
return result;
}
我们主要关注 createConnections方法:
private List<Connection> createConnections(final String dataSourceName, final ConnectionMode connectionMode, final DataSource dataSource, final int connectionSize) throws SQLException {
if (1 == connectionSize) {
Connection connection = createConnection(dataSourceName, dataSource);
replayMethodsInvocation(connection);
return Collections.singletonList(connection);
}
if (ConnectionMode.CONNECTION_STRICTLY == connectionMode) {
return createConnections(dataSourceName, dataSource, connectionSize);
}
synchronized (dataSource) {
return createConnections(dataSourceName, dataSource, connectionSize);
}
}
这段代码涉及了 ConnectionMode(连接模式),这是 ShardingSphere 执行引擎中的重要概念,今天我们先不展开。可以看到 createConnections 方法批量调用了一个 createConnection 抽象方法,该方法需要 AbstractConnectionAdapter 的子类进行实现:
protected abstract Connection createConnection(String dataSourceName, DataSource dataSource) throws SQLException;
同时,我们看到对于创建Connection对象,都需要执行这样一个语句:
replayMethodsInvocation(connection);
这行代码比较难以理解,让我们来看看定义它的地方,即WrapperAdapter类。
WrapperAdapter
从命名上看,WrapperAdapter是一个包装器的适配类,实现了JDBC中的Wrapper接口。我们在该类中找到了这样一对方法定义:
//记录方法调用
public final void recordMethodInvocation(final Class<?> targetClass, final String methodName, final Class<?>[] argumentTypes, final Object[] arguments) {
jdbcMethodInvocations.add(new JdbcMethodInvocation(targetClass.getMethod(methodName, argumentTypes), arguments));
}
//重放方法调用
public final void replayMethodsInvocation(final Object target) {
for (JdbcMethodInvocation each : jdbcMethodInvocations) {
each.invoke(target);
}
}
这两个方法都用到了JdbcMethodInvocation类:
public class JdbcMethodInvocation {
@Getter
private final Method method;
@Getter
private final Object[] arguments;
/**
* Invoke JDBC method.
*
* @param target target object
*/
@SneakyThrows
public void invoke(final Object target) {
method.invoke(target, arguments);
}
}
JdbcMethodInvocation 类中用到了反射技术根据传入的 method 和 arguments 对象执行对应方法。 recordMethodInvocation用于记录需要执行的方法和参数,而replayMethodsInvocation则根据这些方法和参数通过反射技术进行执行。
对于执行 replayMethodsInvocation,我们必须先找到 recordMethodInvocation 的调用入口。通过代码的调用关系,可以看到在 AbstractConnectionAdapter 中对其进行了调用,具体来说就是 setAutoCommit、setReadOnly 和 setTransactionIsolation 这三处方法。这里以 setReadOnly 方法为例给出它的实现:
@Override
public final void setReadOnly(final boolean readOnly) throws SQLException {
this.readOnly = readOnly;
//调用recordMethodInvocation方法记录方法调用的元数据
recordMethodInvocation(Connection.class, "setReadOnly", new Class[]{boolean.class}, new Object[]{readOnly});
//执行回调
forceExecuteTemplate.execute(cachedConnections.values(), new ForceExecuteCallback<Connection>() {
@Override
public void execute(final Connection connection) throws SQLException {
connection.setReadOnly(readOnly);
}
});
}
AbstractUnsupportedOperationConnection
从类层次关系上,可以看到AbstractConnectionAdapter直接继承的是AbstractUnsupportedOperationConnection。在AbstractUnsupportedOperationConnection中都是一组直接抛出异常的方法。这里截取部分代码:
public abstract class AbstractUnsupportedOperationConnection extends WrapperAdapter implements Connection {
@Override
public final CallableStatement prepareCall(final String sql) throws SQLException {
throw new SQLFeatureNotSupportedException("prepareCall");
}
@Override
public final CallableStatement prepareCall(final String sql, final int resultSetType, final int resultSetConcurrency) throws SQLException {
throw new SQLFeatureNotSupportedException("prepareCall");
}
…
}
AbstractUnsupportedOperationConnection 这种处理方式的目的就是明确哪些操作是 AbstractConnectionAdapter 及其子类 ShardingConnection 所不能支持的,属于职责分离的一种具体实现方法。












