
本文通俗地介绍了Lucene全文检索的内容及工作原理,以及索引的结构,旨在让以前未了解过Lucene的读者在能在短时间内对Lucene有简单认知,未介绍具体代码,读完本文可知道Lucene是什么,有哪些具体应用,我们一直说的索引是什么。
Lucene介绍及应用
Apache Lucene是当下最为流行的开源全文检索工具包,基于JAVA语言编写。
目前基于此工具包开源的搜索引擎,成熟且广为人知的有Solr和Elasticsearch。2010年后Lucene和Solr两个项目由同一个Apache软件基金会的开发团队制作,所以通常我们看到的版本都是同步的。二者的区别是Lucene是工具包,而Solr是基于Lucene制作的企业级搜索应用。另外,我们常用的Eclipse,帮助系统的搜索功能也是基于Lucene实现的。
Lucene的两项工作
我们的生活物品中,汉语字典与全文索引是很相似的。我们拿拼音查字法举例,首先我们通过拼音找到我们要查字的页数,然后翻到该页,阅读这个字的详细解释。
在上面的例子中,我们提到了两个要素:一个是字典,另一个是查字的过程。对应到Lucene的功能上,一个是我们要建立一个字典,这个过程叫做建立索引,另一个是根据搜索词基于索引进行查询。
建立索引
1. 文档的准备(Document)
文档就是指我们要去搜索的原文。
2. 分词组件(Tokenizer)
将第一步的文档进行词语切割,去除标点,去除无用词,比如“是”,“的”等。常用的开源中文分词组件有MMSEG4J、IKAnalyzer等。切割后的词语我们称为词元(Token)。
3. 语言处理(Linguistic Processor)
将上一步的获得的词元进行处理,比如英文的大写转小写,复数变单数,过去时分词转原形等。此时得到的结果,被称作词(Term)
4. 索引组件
索引组件将上步得到的词,生成索引和词典,存储到磁盘上。索引组件先将Term变成字典,然后对字典进行排序,排序后对相同的词进行合并,形成倒排列表。每个词在列表中存储了对应的文档Id(Document Frequency)以及这个词在这个文档中出现了几次(Term Frequency)。
搜索
**1. 输入查询词
**
2. 词法分析及语言处理
对输入的词进行拆分,关键字识别(AND,NOT)等。对拆分的词元进行语言处理,与建立字典时语言处理的过程相同。由关键字与处理后的词生成语法树。
3. 搜索索引,获得符合语法树的文档
如A and B not C形成的语法树,则会搜索包含A B C的文档列表,然后用A和B的文档列表做交集,结果集与C做差集,得到的结果,就是符合搜索条件的文档列表
4. 根据相关性,对搜索结果排序
通过向量空间模型的算法,得到结果的相关性。比较简单的实现描述如下:在建立索引的时候,我们得到了Document Frequency和Term Frequency,Term Frequency越高,说明文档的相关性越高;Document Frequency越高,说明相关性越弱。这个算法可以自己进行实现。
5. 根据上面的排序结果,返回文档。
索引结构
Lucene的索引结构是有层次结构的。我们以下图为例
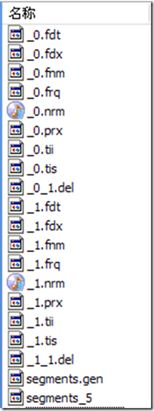
索引(Index)
如果拿数据库做类比,索引类似于数据库的表。
在Lucene中一个索引是放在一个文件夹中的。所以可以理解索引为整个文件夹的内容。
段(Segment)
如果拿数据库做类比,段类似于表的分区。
索引下面引入了Segment 的概念,一个索引下可以多个段。当flush或者commit时生成段文件。截图中有0,1两个段。segments.gen和segments_5是段的元数据文件,它们保存了段的属性信息。其他的文件对应的就是各段的文件,稍后会详细说明各文件的用处。
索引的写入是顺序的,只能被追加,不能被修改。当索引要删除时,在.del文件中写入对应的docId。查询的时候会过滤到此docId。另外索引的修改,是对Document进行删除后做的追加。这种设计保证了高吞吐量。
分段的设计能保证查询的高效,当段太大时,查询会产生很大的IO消耗。段太小,则需要查询的段太多。所以lucene对段进行了合并,另外删除的数据也是在合并过程中过滤掉的。4.0之前的默认的合并策略为LogMergePolicy,这个策略会合并小于指定值的相邻段,如果两个相邻段,一个大小为1G,一个大小为1k,则会重写1G的文件会占用很大资源。4.0之后默认策略改为了TieredMergePolicy,这个策略会先按分段大小进行排序,对段进行删除比计算,优先合并小的分段。当系统闲暇的时候,才对大分段进行合并。
文档(Document)
如果拿数据库做类比,文档类似于数据的一行。
Document是索引的基本单位。一个段可以有多个Document
域(Field)
如果拿数据库做类比,域相当于表的字段。
Doument里可以有多个Field。Lucene提供多种不同类型的Field,例如StringField、TextField、LongFiled或NumericDocValuesField等。
词(Term)
Term是索引的最小单位。Term是由Field经过Analyzer(分词)产生。
段的文件说明
第三小节详细描述了段的设计和合并策略,以下详细讲解一些段文件的内容。
segments_N保存了此索引包含多少个段,每个段包含多少篇文档。
*.fnm
保存了此段包含了多少个域,每个域的名称及索引方式。
*.fdx,*.fdt
保存了此段包含的所有文档,每篇文档包含了多少域,每个域保存了那些信息。
*.tvx,*.tvd,*.tvf
保存了此段包含多少文档,每篇文档包含了多少域,每个域包含了多少词,每个词的字符串,位置等信息。
*.tis,*.tii
保存了词典(Term Dictionary),也即此段包含的所有的词按字典顺序的排序。
*.frq
保存了倒排表,也即包含每个词的文档ID列表。
*.prx
保存了倒排表中每个词在包含此词的文档中的位置
*.del
前面讲段的时候有提到,用来是存储删掉文档id的。
-END-
热门招聘
宜信技术研发中心正在快速成长中,欢迎更多优秀的大数据运维工程师和产品经理的加入,对宜信感兴趣的小伙伴可以将简历发到邮箱:Yixin-HR@creditease.cn,我们会在第一时间跟您取得联系,期待您的关注~~
◆ ◆ ◆ ◆ ◆
发现文章有错误、对内容有疑问,都可以通过关注宜信技术学院微信公众号(CE_TECH),在后台留言给我们。我们每周会挑选出一位热心小伙伴,送上一份精美的小礼品。快来扫码关注我们吧!

本文分享自微信公众号 - 宜信技术学院(CE_TECH)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。







