前言:
《凹凸数读》新文章已发,可以先看数据分析结果再回来看过程:
《2000万直播数据看20万游戏主播能否月入100万>>>>》
2019年7月17日游戏直播平台斗鱼在美国纳斯达克股票交易所成功上市,成为继虎牙直播之后第二家赴美上市的国内直播平台。
7月底斗鱼因为平台主播“乔碧萝殿下”事件再次被推上热搜。
段子手们纷纷调侃成为主播的门槛之低:只需要变声软件+盗图+超级美颜。
那么直播行业真的如同网友们所说的这么简单吗?
主播们的真实生存现状如何?
分析一下。
获取数据
打开斗鱼直播界面,连续点击翻页
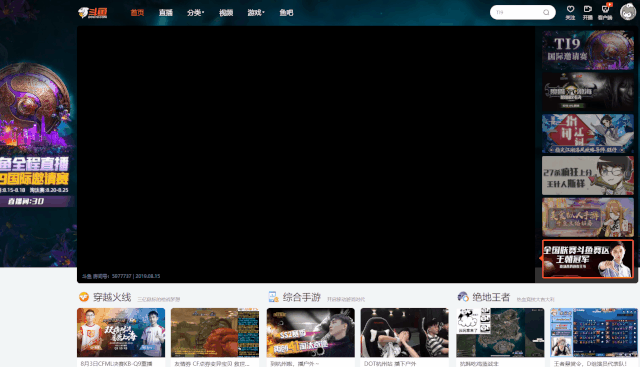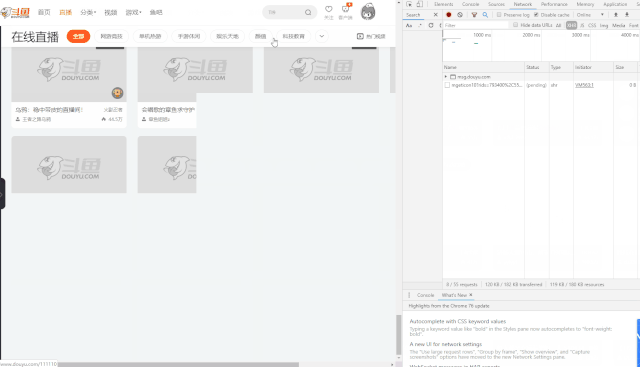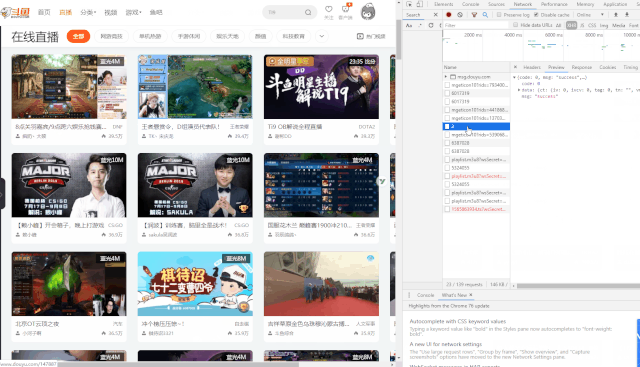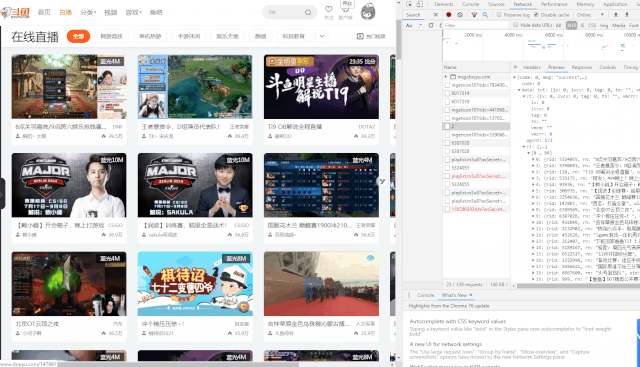
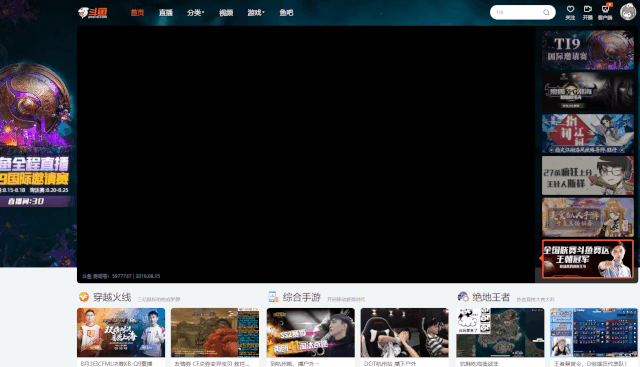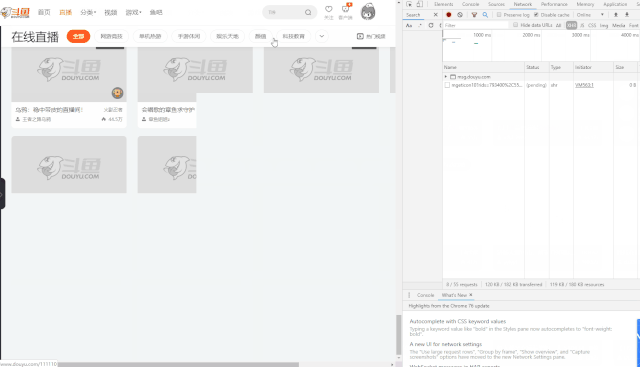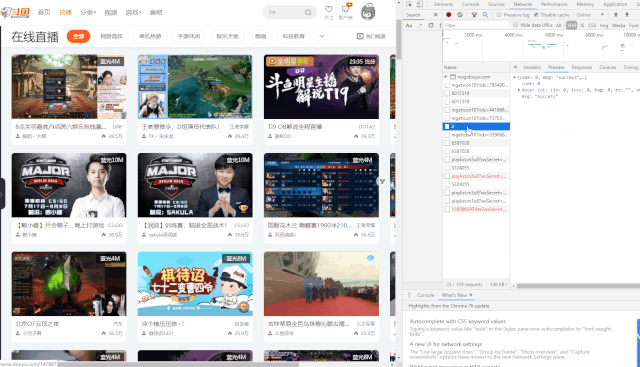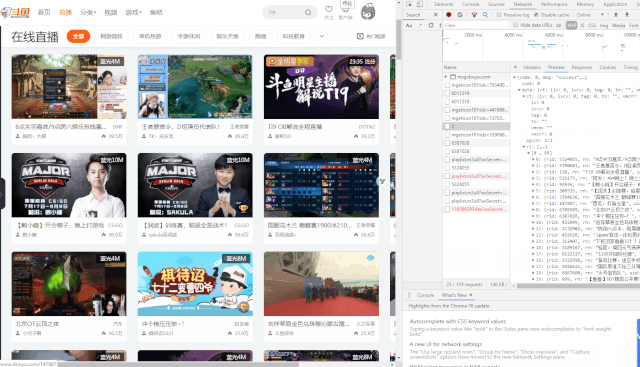
Network查看异步请求XHR,找到对应的URL
get。
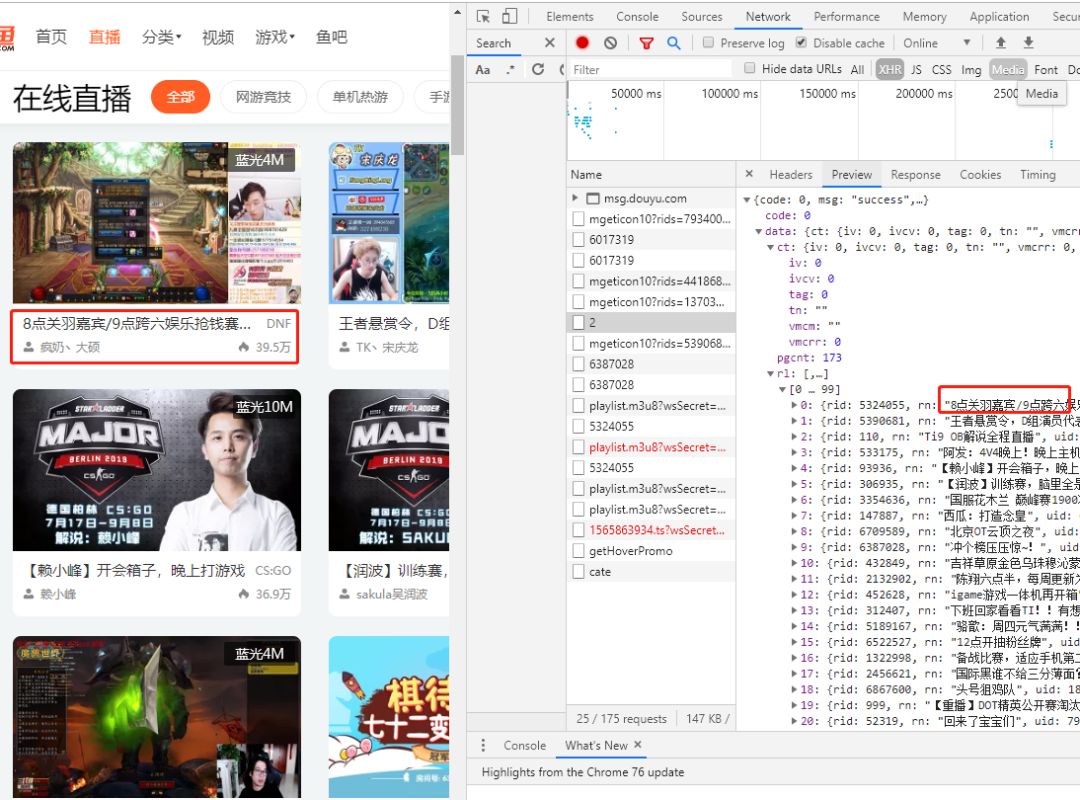
成功获取到对应的URL。
https://www.douyu.com/gapi/rkc/directory/0_0/2
翻页只变动末尾的最后一个数字。
采用requests+pyquery来爬取。
部分爬虫代码如下。
def get_datas(url):
data = []
doc = get_json(url)
jobs=doc['data']['rl']
for job in jobs:
dic = {}
dic['user_name']=jsonpath.jsonpath(job,'$..nn')[0] #用户名
dic['user_id']= jsonpath.jsonpath(job,'$..uid')[0] #用户ID
dic['room_name']=jsonpath.jsonpath(job,'$..rn')[0] #房间名
dic['room_id']=jsonpath.jsonpath(job,'$..rid')[0] #房间ID
dic['redu']=jsonpath.jsonpath(job,'$..ol')[0] #热度
dic['c2name']=jsonpath.jsonpath(job,'$..c2name')[0] #分区
dic['time']= stampToTime(time.time())
data.append(dic)
return data 剩下就是连续爬取,我设置的是10分钟爬取一次。
将爬取得到的数据存入Mysql中。
#存到Mysql
from sqlalchemy import create_engine
engine = create_engine('mysql+mysqldb://root:***密码***@localhost:3306/demo?charset=utf8mb4')
final_result.to_sql('data_douyu',con=engine, index=False, index_label=False,if_exists='append', chunksize=1000)
连续爬取了大概七天多时间,最终得到2062万条直播数据。
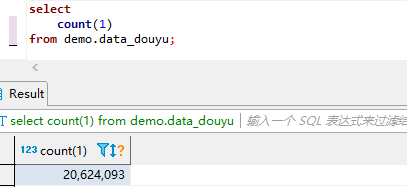
数据分析
将数据导入python。
去重,其实爬虫部分已经设置去重,这里为了保险再来一次,不过事实证明确实没有重复。
因为实际爬取时间是0731下午到0808上午,为了方便后文计算,这里选取0801-0807这连续七天的直播数据。
#去重
data = data[['c2name', 'redu', 'room_id', 'room_name', 'time','user_id', 'user_name']].drop_duplicates()
#筛选时间
data = data.loc[(data['time'] <= '2019-08-07') & (data['time'] >= '2019-08-01')]我们还需要对主播按照id分组汇总。
先利用groupby分类汇总,再计算增加新列。
data_abc['av_redu'] = data_abc['redu']/data_abc['time_num']
data_abc['hour'] = data_abc['time_num']/ 42 #每十分钟一次,七天
data_abc.head()
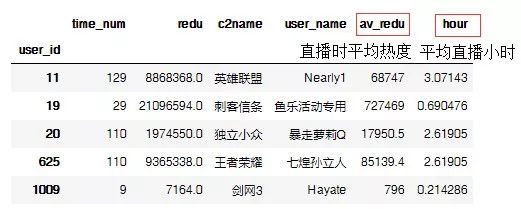
这样我们就又构建了一组以主播为索引的数据。
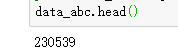
也就是说这七天之内,直播过的主播共有23万余人,那么下文让我们看看他们的生存现状吧。
数据可视化
将这23万主播按照平均直播时长和平均直播热度绘制一个散点图。
import seaborn as sns
import matplotlib as mpl #配置字体
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
mpl.rcParams['axes.unicode_minus']
plt.figure(figsize=(8,8))
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)
sns.scatterplot(data_test["hour"],data_test["av_redu"],hue=data_test["c2name"])
结果如下图所示。
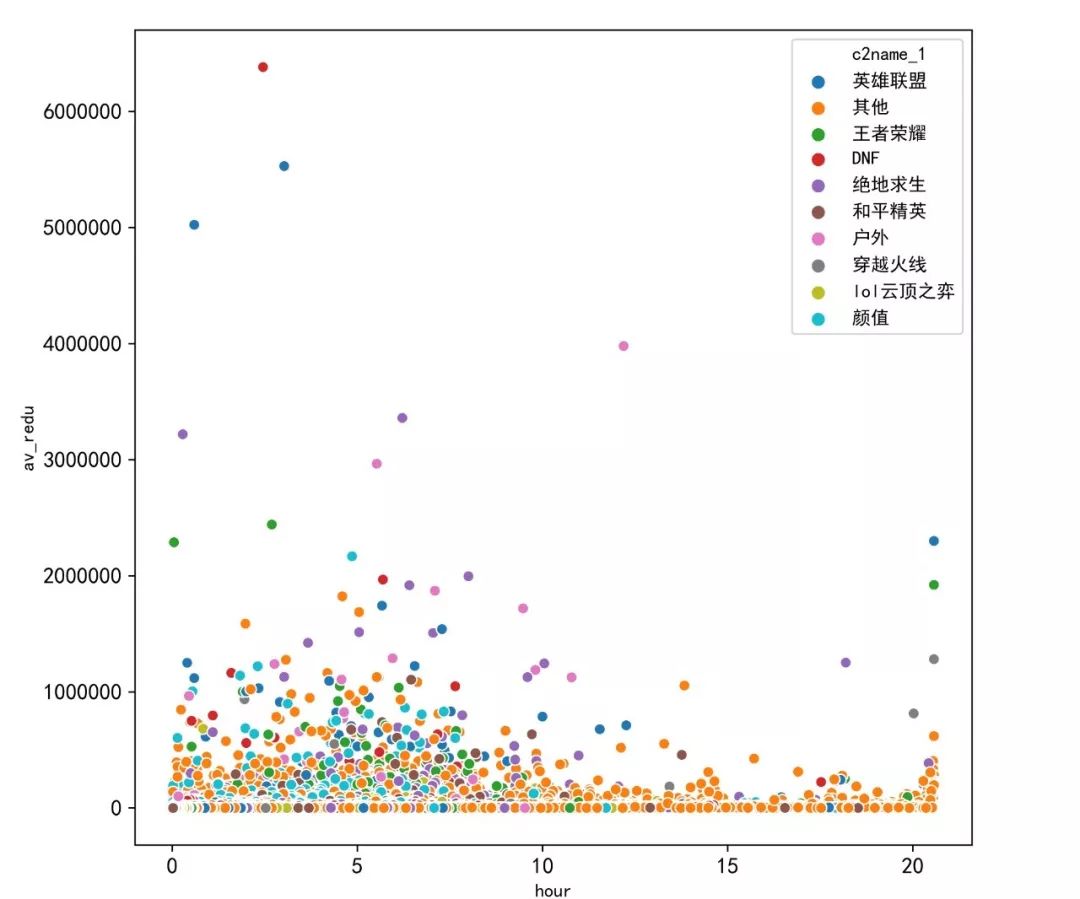
从上图能看出,绝大部分主播都在底部,能够成为大主播的寥寥无几,且热度较高的主播集中于上述的几个热门分区,其他分区主播发展普遍一般。
由于有20多万的主播集中在下方,很难看出他们平均直播时长的分布。
另一方面,主播分化程度较为严重,为了更直观的展现趋势,我们以1万平均热度为分界,分析不同规模的主播每天平均直播时长。
#头部主播
plt.figure(figsize=(10,6))
plt.xticks(fontsize=13)
plt.yticks(fontsize=13)
sns.distplot(data_abc.loc[(data_abc['av_redu'] > 10000)]["hour"],kde=True,rug=False,color='y')
plt.show()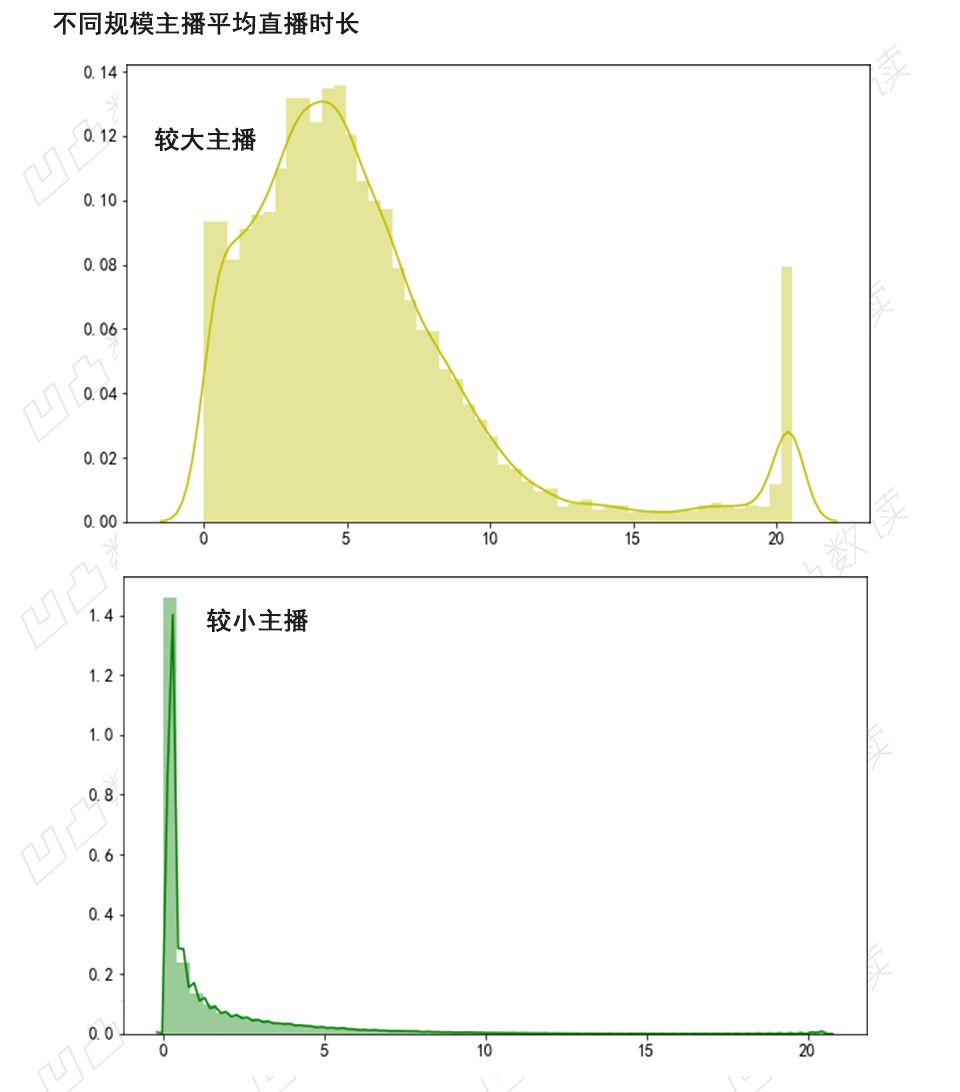
图中可以发现较大的主播每天直播时长集中在5小时左右,这5个小时的游戏并非我们平时玩的那么简单。主播直播时往往既需要全神贯注玩游戏,又要和观众一起互动交流。
而较小主播直播时长则大部分在1小时左右,不能持续直播,导致观众少;观看人数少,主播没动力,久而久之,也就难以出头,形成恶性循环。
上图中有一些异常值,即平均每日直播时长超过20小时的直播间,这样的直播大部分为“一起看”分区,可以24小时连续播放电影电视剧之类的视频,余下都是游戏或者比赛的官方频道,用来循环播放官方视频。
那么主播们大部分在什么时间直播呢?
他们的观众也是同一时间准时观看吗?

从同一时间段内主播直播与观众观看在线人数可以看出,有两个时段有差异。
一个是晚上21点后至凌晨6点前,以直播为职业的主播往往已经进行了5-6小时高强度不间断的直播,会选择后半夜好好休息一下,而将看直播作为娱乐的观众则躺在床上看到上头;
另一个时段是下午12点左右到18点,观众都正在上班上学,而很多全职主播中午起床吃饭后,正好下午开始了他们的直播。
2000万条数据能分析的当然不止这些,详情请移步。
《2000万直播数据看20万游戏主播能否月入100万>>>>》
大部分主播并非我们想象的那样,时间自由,赚钱容易。每天在线直播的主播人数以十万甚至百万为单位,但真正赢得观众喜爱和自愿刷大量礼物的事实上寥寥无几。一时的流量换不来观众永远的买账,以噱头博出位后如何用内容留住观众,是每个主播在探索的方向。
随着行业监管的加强,直播平台逐渐褪去“泡沫”,流量红利消失,回归理性。“熊猫”已经远走,行业内的竞争更加集中在剩下的头部平台之间,这些平台也更需要探索更优质的内容和更多元的发展,绝不可寄希望于花几千万签约“知名主播”或是炒作“乔碧萝”之类的噱头。
本文相关爬虫代码,仅供学习交流:
#下载链接
https://t.zsxq.com/iQRjeeY转载请尽量带上二维码或者结尾注明来源,谢谢了。
本文转转自微信公众号凹凸数据原创https://mp.weixin.qq.com/s/dIUNslHuxnd9H_x4fMFEeQ,可扫描二维码进行关注:
 如有侵权,请联系删除。
如有侵权,请联系删除。