
自 LinkedIn 2011 年创建了 Apache Kafka 后,这款消息系统一度成为大规模消息系统的唯一选择。为什么呢?因为这些消息系统每天需要传递数百万条消息,消息规模确实很庞大(2018 年 Twitter 推文平均每天 500 万条,用户数平均每天为 1 亿)。那时,我们没有 MOM 系统来处理基于大量订阅的流数据能力。所以,很多大牌公司,像 LinkedIn、Yahoo、Twitter、Netflix 和 Uber,只能选择 Kafka。
如今到了 2019 年,世界发生了巨变,每天的消息增量高达数十亿,支持平台也需要相应扩展,以满足持续增长的需要。因此,消息系统需要在不影响客户的情况下持续地无缝扩展。Kafka 在扩展方面存在诸多问题,系统也难以管理。Kafka 的粉丝对此说法可能颇有微词,然而这并非个人偏见,我本身也是 Kafka 的粉丝。客观的说,随着世界的发展和创新,新工具比旧工具更加方便易用,我们自然会感觉原来的工具漏洞百出,很难使用。自然发展,一直如此。
这时,一款新的产品应运而生——它就是“Apache Pulsar”!

2013 年雅虎创建了 Pulsar,并于 2016 年把 Pulsar 捐给了 Apache 基金会。Pulsar 现已成为 Apache 的顶级项目,获得举世瞩目的认可。雅虎和 Twitter 都在使用 Pulsar,雅虎每天发送 1000 亿条消息,两百多万个主题。这样的消息量,听起来很不可思议吧,但确实是真的!
接下来我们了解下 Kafka 痛点以及 Pulsar 对应的解决方案。
Kafka 很难进行扩展,因为 Kafka 把消息持久化在 broker 中,迁移主题分区时,需要把分区的数据完全复制到其他 broker 中,这个操作非常耗时。
当需要通过更改分区大小以获得更多的存储空间时,会与消息索引产生冲突,打乱消息顺序。因此,如果用户需要保证消息的顺序,Kafka 就变得非常棘手了。
如果分区副本不处于 ISR(同步)状态,那么 leader 选取可能会紊乱。一般地,当原始主分区出现故障时,应该有一个 ISR 副本被征用,但是这点并不能完全保证。若在设置中并未规定只有 ISR 副本可被选为 leader 时,选出一个处于非同步状态的副本做 leader,这比没有 broker 服务该 partition 的情况更糟糕。
使用 Kafka 时,你需要根据现有的情况并充分考虑未来的增量计划,规划 broker、主题、分区和副本的数量,才能避免 Kafka 扩展导致的问题。这是理想状况,实际情况很难规划,不可避免会出现扩展需求。
Kafka 集群的分区再均衡会影响相关生产者和消费者的性能。
发生故障时,Kafka 主题无法保证消息的完整性(特别是遇到第 3 点中的情况,需要扩展时极有可能丢失消息)。
使用 Kafka 需要和 offset 打交道,这点让人很头痛,因为 broker 并不维护 consumer 的消费状态。
如果使用率很高,则必须尽快删除旧消息,否则就会出现磁盘空间不够用的问题。
众所周知,Kafka 原生的跨地域复制机制(MirrorMaker)有问题,即使只在两个数据中心也无法正常使用跨地域复制。因此,甚至 Uber 都不得不创建另一套解决方案来解决这个问题,并将其称为 uReplicator 。
要想进行实时数据分析,就不得不选用第三方工具,如 Apache Storm、Apache Heron 或 Apache Spark。同时,你需要确保这些第三方工具足以支撑传入的流量。
Kafka 没有原生的多租户功能来实现租户的完全隔离,它是通过使用主题授权等安全功能来完成的。
当然,在生产环境中,架构师和工程师有办法解决上述问题;但是在平台/解决方案或站点可靠性上,这是个让人头疼的问题,这并不像在代码中修复逻辑,然后将打包的二进制文件部署到生产环境中那么简单。
现在,我们来聊聊 Pulsar,这个竞争领域中的领跑者。
什么是 Apache Pulsar?
Apache Pulsar 是一个开源分布式发布-订阅消息系统,最初由雅虎创建。如果你了解 Kafka,可以认为 Pulsar 在本质上和 Kafka 类似。
Pulsar 性能

Pulsar 表现最出色的就是性能,Pulsar 的速度比 Kafka 快得多,美国德克萨斯州一家名为 GigaOm 的技术研究和分析公司对 Kafka 和 Pulsar 的性能做了比较,并证实了这一点。
与 Kafka 相比,Pulsar 的速度提升了 2.5 倍,延迟降低了 40%。(来源在这里)。
请注意,该性能比较是针对 1 个分区的 1 个主题,其中包含 100 字节消息。而 Pulsar 每秒可发送 220,000+ 条消息,如下所示。
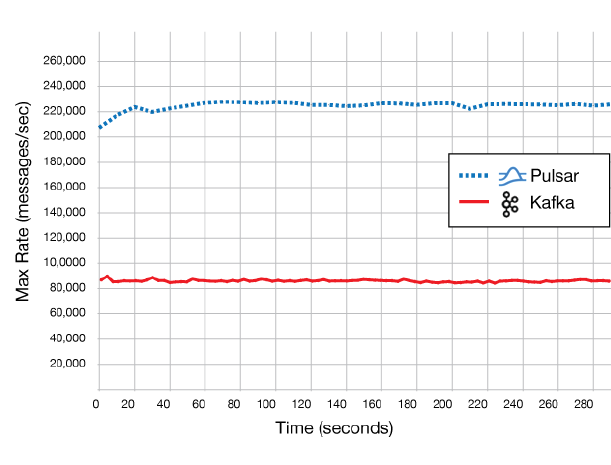
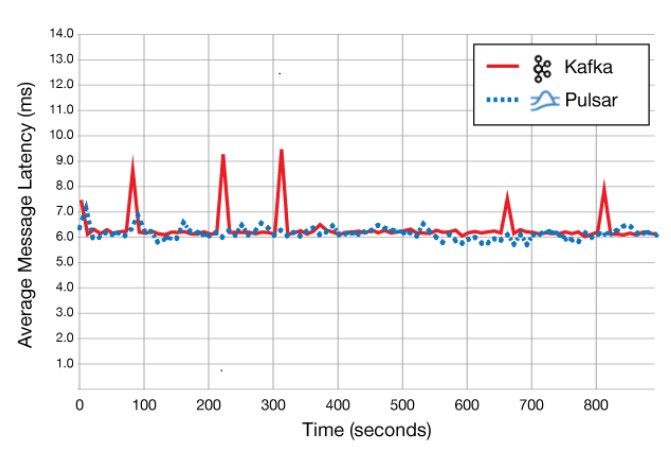
这点 Pulsar 做的确实很棒!
就冲这一点,放弃 Kafka 而转向 Pulsar 绝对很值,接下来,我会详细剖析 Pulsar 的优势和特点。
Apache Pulsar 的优势和特点
Pulsar 既支持作为消息队列以 Pub-Sub 模式使用,又支持按序访问(类似 Kafka 基于 Offset 的阅读),这给用户提供了极大的灵活性。
针对数据持久化,Pulsar 的系统架构和 Kafka 不同。Kafka 在本地 broker 中使用日志文件,而 Pulsar 把所有主题数据存储在 Apache BookKeeper 的专用数据层中。简单地说,BookKeeper 是一种高可扩展、强容灾和低延时的存储服务,并且针对实时持久的数据工作负载进行了优化。因此,BookKeeper 保证了数据的可用性。而 Kafka 日志文件驻留在各个 broker 以及灾难性服务器故障中,所以 Kafka 日志文件可能出现问题,不能完全确保数据的可用性。这个有保证的持久层(guaranteed persistence layer)给 Pulsar 带来了另一个优势,即“broker 是无状态的”。这与 Kafka 有本质的区别。Pulsar 的优势在于 broker 可以无缝地水平扩展以满足不断增长的需求,因为它在扩展时不需要移动实际数据。
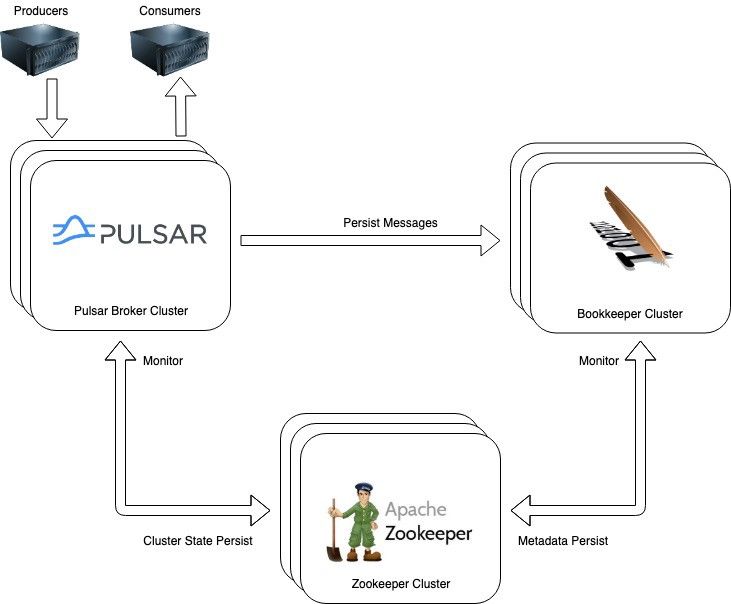
如果一个 Pulsar broker 宕机了怎么办?主题会被立即重新分配给另一个 broker。由于 broker 的磁盘中没有主题数据,服务发现会自行处理 producer 和 consumer。
Kafka 需要清除旧数据才能使用磁盘空间;与 Kafka 不同,Pulsar 把主题数据存储在一个分层结构中,该结构可以连接其他磁盘或 Amazon S3,这样就可以无限扩展和卸载主题数据的存储量。更酷的是,Pulsar 向消费者无缝地显示数据,就好像这些数据在同一个驱动器上。由于不需要清除旧数据,你可以把这些组织好的 Pulsar 主题用作“数据湖(Data Lake)”,这个用户场景还是很有价值的。当然,需要的时候,你也可以通过设置,清除 Pulsar 中的旧数据。
Pulsar 原生支持在主题命名空间级别使用数据隔离的多租户;而 Kafka 无法实现这种隔离。此外,Pulsar 还支持细粒度访问控制功能,这让 Pulsar 的应用程序更加安全、可靠。
Pulsar 有多个客户端库,可用于 Java、Go、Python、C++ 和 WebSocket 语言。
Pulsar 原生支持功能即服务(FaaS),这个功能很酷,就和 Amazon Lambda 一样,可以实时分析、聚合或汇总实时数据流。使用 Kafka,还需要配套使用像 Apache Storm 这样的流处理系统,这会额外增加成本,维护起来也很麻烦。在这点上,Pulsar 就远远胜过 Kafka。截至目前,Pulsar Functions 支持 Java、 Python 和 Go 语言,其他语言将在以后的版本中陆续得到支持。
Pulsar Functions 的用户案例包括基于内容的路由(content based routing)、聚合、消息格式化、消息清洗等。
如下是字数计算示例。
package org.example.functions;import org.apache.pulsar.functions.api.Context;import org.apache.pulsar.functions.api.Function;import java.util.Arrays;public class WordCountFunction implements Function<String, Void> { // This is invoked every time messages published to the topic @Override public Void process(String input, Context context) throws Exception { Arrays.asList(input.split(" ")).forEach(word -> { String counterKey = word.toLowerCase(); context.incrCounter(counterKey, 1); }); return null; }}
Pulsar 支持多个数据接收器(data sink),用于为主要产品(如 Pulsar 主题本身、Cassandra、Kafka、AWS Kinesis、弹性搜索、Redis、Mongo DB、Influx DB 等)路由处理过的消息。
此外,还可以把处理过的消息流持久化到磁盘文件。
Pulsar 使用 Pulsar SQL 查询历史消息,使用 Presto 引擎高效查询 BookKeeper 中的数据。Presto 是用于大数据解决方案的高性能分布式 SQL 查询引擎,可以在单个查询中查询多个数据源的数据。如下是使用 Pulsar SQL 查询的示例。
show tables in pulsar."public/default"
Pulsar 内置强大的跨地域复制机制,可在不同区域的不同集群之间即时同步消息,以维护消息的完整性。在 Pulsar 主题上生成消息时,消息首先保留在本地集群中,然后异步转发到远程集群。在 Pulsar 中,启用跨地域复制是基于租户的。只有创建的租户可以同时访问两个集群时,这两个集群之间才能启用跨地域复制。
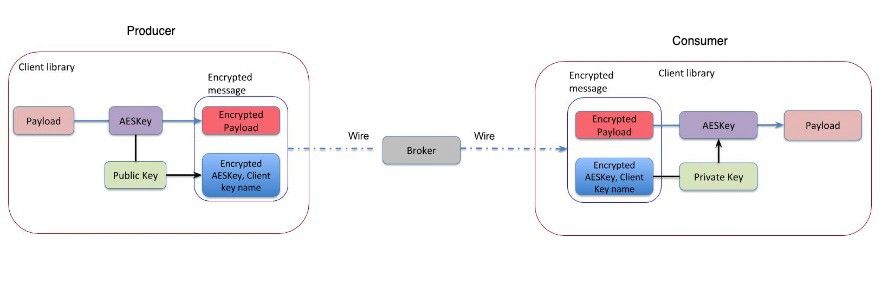
对于消息传递通道安全,Pulsar 原生支持基于 TLS 和基于 JWT token 的授权机制。因此,你可以指定谁可以发布或使用哪些主题的消息。此外,为了提高安全性,Pulsar Encryption 允许应用程序在生产者端加密所有消息,并在 Pulsar 传递加密消息到消费者端时解密。Pulsar 使用应用程序配置的公钥/私钥对执行加密。具有有效密钥的消费者才能解密加密消息。但这会带来性能损失,因为每条消息都需要加密和解密才能进行处理。
目前在使用 Kafka 并且希望迁移到 Pulsar 的用户大可放心,Pulsar 原生支持通过连接器(connector)直接使用 Kafka 数据,或者你可以把现有的 Kafka 应用程序数据导入到 Pulsar,这个过程也相当容易。
总结
这篇文章并不是说大规模消息处理平台不能使用 Kafka,只能选择 Pulsar。我要强调的是,Kafka 的痛点 Pulsar 已经有了很好的解决方案,这对任何工程师或架构师来说都是一件好事。另外,在体系架构方面 Pulsar 在大型消息传递解决方案中的速度要快得多,随着雅虎和 Twitter(以及许多其他公司)把 Pulsar 部署到生产环境,说明 Pulsar 稳定性足以支撑任何生产环境。虽然从 Kafka 转到 Pulsar,会经历一个小小的学习曲线,但相应的投资回报率还是很客观的!
— THE END —

本文分享自微信公众号 - 大数据技术与架构(import_bigdata)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。












