

小蚂蚁说:
“过无人区” 、“Made in China” 、“反哺”是GeaBase的几个耀眼标签。每年的支付宝春节红包、每一笔交易的反洗钱识别等等,背后的技术都少不了它的身影。
如今,GeaBase这款广泛应用于蚂蚁金服风控、社交、推荐等技术场景的中国第一个金融级分布式图数据库,现正处于免费公测期,复制下方网址至浏览器中打开即可查看:
https://www.cloud.alipay.com/products/geabase

引子:一个值钱的难题
2015年下半年之后,各大超级App已基本把移动互联网的高价值流量瓜分殆尽,按照这几年颇为流行的增长黑客方法,互联网企业如果想继续获得增长,就需要提升重度用户的客单价和潜在用户的转化率,而两者都离不开利用各种推荐算法发现用户社交关系和兴趣点的病毒式营销方案。
解法看起来简单,实现起来却并不简单。如果把你的大学同学作为一度人脉的话,那么你大学同学的高中同学就属于你的二度人脉,而你同学高中同学的配偶就是你的三度人脉。如果要实现推荐二度人脉甚至五度人脉的推荐功能,应该如何实现?
相信有一定数据库基础的工程师,都可以实现一个推荐二度人脉的数据库表设计和代码实现。只要建立一个包含用户表user,好友关系表user_friends,用于表示好友之间的关系就可以实现了。但如果我们需要实现查一个五度范围内和我一样在某家天猫店消费过,并留下点评的用户时,难度就来了——这绝不仅是要先把所有的五度范围内的人脉找出来,然后再搜索一下有过该店消费记录的用户那么简单!
实际上,在《Graph Databases》一书中曾以MySQL和Neo4j为例,对比关系型数据库和图数据库之间的性能差异:如下表,第一列的“深度”表示社交朋友之间的关系,深度为1,表明二人为直接好友;深度为2,表明二人为好友的好友,以此类推。由图表可知,当深度达到5时,关系型数据库已无法完成任务,而图数据库的响应时间为2.132秒,在可接受范围内。
深度
关系型数据库(s)
图数据库(Neo4j)
返回个数
2
0.016
0.01
2500
3
30.267
0.168
110,000
4
1543.505
1.359
600,000
5
未完成
2.132
800,000
数据来自《Graph Databases》
那么,什么是Graph Database?它最新的研发、应用场景和商业价值又是怎样的?最近,我和蚂蚁金服GeaBase团队的核心成员,聊了聊他们的故事。
关于图数据库和GeaBase
要理解图数据库,首先得理解它的定义。与笔者首先分享图数据库观点的,是萧河。

何昌华:花名萧河,蚂蚁金服计算存储首席架构师
何昌华,花名萧河,现任蚂蚁金服计算存储首席架构师,斯坦福大学博士,入选为第14批国家“千人计划”专家。2008至2015年供职于Google搜索架构部门,后来加入Airbnb,负责后台系统的应用架构,专注于大规模的分布式系统及大数据架构。2017年,萧河加入蚂蚁金服,带领团队研发并上线了蚂蚁实时智能决策系统,解决了端到端秒级数据实时性,线下模型训练和线上决策数据一致性,以及业务智能化门槛高和开发周期长的问题。目前萧河正聚焦于新一代数据技术架构以及金融级核心计算引擎的自主研发。
在他看来,图数据库是擅长展现“关系”的非关系型数据库,其特点在于,图数据库是以“图”这种数据结构存储和查询数据。图数据库起源于图理论,数据模型主要是以节点和关系(边)来体现,它的优点是能够快速解决复杂的关系问题。
图数据库的发展和大数据的发展有着密切的联系。大数据之所以受到广泛关注,其本质在于对海量数据的统计、汇总,从中可以发现一些规律。在2000年左右,大数据应用的主要方向还是数据统计,但随着人工智能、知识图谱的兴起,人们开始更加关注数据和数据之间的联系,但这是传统关系型数据库很难展现出来的。
以电影知识图谱为例,其两大主体为电影和人。人和电影之间可能存在导演关系,某人是某部电影的导演;可能存在演员关系,某人为某部电影的演员,这两种关系均可通过外键表示。但是,上述关系通过关系型数据库展现时,整个E-R图非常复杂。通过图数据库展现时,电影和人为两大主体,其之间的关系只存在演员和导演两种,演员中将主演特征标注出来即可。

当需要描述大量关系时,传统关系型数据库通常会变得不堪重负,甚至无法返回结果。正如文章开头的例子,图数据模型非常适合用来表达现实世界里面的数据。在很多场景中,相比于数据本身,其实我们更加关注数据背后所表达的一些信息,以及信息之间的关联。图数据模型能够更加直观、自然的展现这种关联,对于用户来说,和数据的交互方式、使用数据的方式,通过图的方式也要更加直接。
实际上,得益于这种能够展现数据之间“关系”的特性,图数据库在金融风控、知识图谱等众多领域有着广泛的应用空间。例如,反欺诈是金融行业一个核心应用,通过图数据库可以对不同的个体、团体做关联分析,从人物的亲友关系和可信关系,历史行为数据(比如在指定时间内的行为,去过地方的IP地址、曾经使用过的MAC地址,包括手机端、PC端、WIFI等),地理位置信息(比如同一时间点是否曾经在同一地理位置附近出现过),以及银行账号之间是否有历史交易信息等进行关联分析。
图数据库的应用场景越来越广泛,而另一方面,随着关系型数据库使用场景的不断扩大,也暴露出一些无法解决的问题,其中最主要的是数据建模中的一些缺陷、以及在大数据量和多服务器之上进行水平伸缩的限制。在应对这些趋势时,关系型数据库产生了更多的不适应性,从而导致大量解决这些问题中某些特定方面的不同技术出现,一定程度上促进了图数据库的快速发展。
DB-Engines数据显示,最近十年,图数据库已经成为关注度最高、也是发展趋势最明显的数据库类型。蚂蚁金服看到了这一趋势,从2015年开始组建GeaBase团队,自研图数据库。
他们做成了中国首个金融级分布式图数据库
2015年GeaBase团队刚组建的时候,只有两个阿里巴巴过来的从事过图计算研究的两个老员工,后来招了很多新人,绝大多数基本上都是刚毕业不久的。但就是这样一支开始只有“三五个人、七八条枪”的年轻团队,用了不到四年时间,打造出了中国首个金融级分布式图数据库。
“GeaBase现在给我们提供的不仅仅是一个图数据库,而是作为整个图的数据这样的一个大的底盘,在它上面我们会有更多的计算,然后会更好的支持业务”,萧河解释说。
萧河在加入这个团队之前,作为核心技术负责人之一,萧河和当时的同事一起开发了谷歌新一代咖啡因搜索引擎,并获得公司最高技术奖项。之后在萧河在Airbnb工作了两年,负责后台系统的应用架构,专注于大规模的分布式系统及大数据架构。
十几年的硅谷经历,让萧河成长为硅谷华人圈儿最年轻的顶级工程师之一,但这样的履历和光环并没有阻碍萧河归国加入蚂蚁金服。“有很多人都问过我为什么回国加入蚂蚁金服,在硅谷工作是一种比较平稳的状态,但是缺少了真正看到自己的天花板在哪、能够做成什么样的事业的机会”,萧河说。
在萧河看来,蚂蚁金服承载着巨大的用户量,支付宝等产品已经深入的影响了人们的日常生活,已经成为社会的基础设施,影响深远。相比在硅谷,在蚂蚁金服从事的工作对于人们的生活来说更重要,也更有想象力。“每个人都想试一下你的极限在哪儿,我觉得在这里才真正能够尝试能不能够做到一个极限。”
加入蚂蚁金服后,萧河带领团队研发并上线了蚂蚁实时智能决策系统,对金融诈骗和洗钱等行为实现了实时判断。更重要的一项工作是,作为蚂蚁金服计算存储首席架构师,萧河领导计算存储基础技术团队,研发新一代数据技术架构以及金融级核心计算引擎,为蚂蚁金服的所有业务提供计算存储支撑“底盘”。
不仅是萧河,蚂蚁金服GeaBase团队汇集了一大批顶尖的工程师,比如浩壹(付志嵩)等人。

付志嵩:花名浩壹,蚂蚁金服图计算及存储技术团队高级专家
浩壹是2015年加入蚂蚁金服的,现任蚂蚁金服图计算及存储技术团队高级专家。浩壹作为主要架构设计和研发人员参与了实时金融级分布式图数据库GeaBase的开发,实现了对超大规模关系网络毫秒级的复杂查询及变更。
前方,无人区
在蚂蚁金服,自主研发是一件再正常不过的事情。如今,从服务器、网络、存储等基础设施层的资源管理,到分布式数据库和中间件、大数据、移动开发框架等系统平台,再到智能风控、生物识别等金融专属技术,蚂蚁金服已经形成了完整的自研技术栈。
蚂蚁金服选择自研技术的初衷其实很简单,那就是开源或是商用产品已经无法满足蚂蚁金服的巨大业务量和发展速度。在一次关于中国自主创新的论坛上,蚂蚁金服副CTO、阿里巴巴最年轻的合伙人胡喜曾回忆说,2007年蚂蚁金服(当时还是支付宝的时候)的应用程序大部分还是开源的,后来随着业务飞速发展变得过于复杂,不便于扩展和维护,技术团队干脆就从零开始coding。
 胡喜:花名阿玺,蚂蚁金服副CTO、副总裁、首席架构师
胡喜:花名阿玺,蚂蚁金服副CTO、副总裁、首席架构师
“被业务倒逼”是蚂蚁金服选择自主研发的一个主要驱动力。支付宝也曾采用IOE架构,但到了2011年的“双11”,集中式的IOE架构已经完全不能满足需求。当时有两条路,一是继续采用昂贵的IOE技术,另一条是选择自研数据库,自己趟出一条路。
“自研,前面就是无人区”,胡喜说。尽管一路荆棘,但蚂蚁金服还是创造了奇迹,七年苦修,蚂蚁金服成功自研了金融级的分布式关系型数据库OceanBase,顶住了2017年“双11”高达25.6万笔/秒的支付峰值,以分布式架构在普通硬件上实现了金融级高可用性。
而金融级分布式图数据库GeaBase的诞生,也有着鲜明的蚂蚁金服特色,同样是“被业务倒逼出来的”。
“过去很长一段时间图数据库一直停留在学术研究阶段,行业应用场景不多,是因为没有强的场景驱动,所以市场没有太多发展”,萧河指出。但是反过来看,图数据库近年来热度不断攀升,其核心原因是因为强场景的驱动,特别是金融场景。
而蚂蚁金服GeaBase的自研路,也是从金融业务场景的需求开始。
据浩壹回忆,蚂蚁金服在2014年左右就开始跟进社区的图计算的研究,当时的风控团队感觉图计算、图数据库在风控上应该能有很大的应用场景,于是在一些产品上尝试了开源的图数据库产品,做了之后发现效果很好,图数据库能够很好地和风控结合起来。
2015年初,蚂蚁金服和一家商业图数据库公司合作过,做了两个项目的POC测试,结果在这个过程中发现了很多的问题。
蚂蚁金服有着巨大的数据量,需要以分布式架构来支撑高并发的大数据量和大吞吐量,但当时无论是开源还是商业数据库产品都只是单机版,都难以适应蚂蚁金服如此大的数据量和复杂的环境。此外,在金融领域,图数据库将会是一个非常核心的技术,蚂蚁金服希望能够完完全全的掌握,实现自主可控。
既然没有合适的产品,那就选择自研。但自研不像请客吃饭那么容易,如同胡喜所说,自研,前面就是无人区,前途到底如何,谁也不知道。
当时的图数据库团队显得有些“悲壮”,面对几乎不可能完成的任务,唯有信心才是支撑团队继续做下去的动力。
从阿里输入到反哺集团
2015年7月,组建不久的图数据库团队就开始正式写代码。但万事开头难,蚂蚁金服其他产品的开发语言主要是Java,整套的研发体系、工具也是围绕Java的,唯有OceanBase和GeaBase团队采用C++。各种环境的搭建,包括各种辅助的工具的制作,全部都得从头开始。
尽管当时时间紧任务重,团队依旧对每一环都保持着严格的要求,尤其在代码质量上追求完美。所谓“磨刀不误砍柴工”,一开始打好基础,对于产品的稳定性、日后的维护都有着重要的意义。
比如,团队所有代码必须要通过review,保证每个人写出来代码的风格都差不多,这样的好处在于对今后的维护会变得非常的方便。又如,团队代码提交必须都要有单元测试,否则不能提交。“当时是花了很多时间去写这个单元。但是好处在于,后面你做一些重构等,有单元测试保护话,你就不会担心我的重构是不是跟原来的语义不一样。”团队负责人如是说。
就像一个武者的成长,经过“冬练三九、夏练三伏”的苦修,不难练就一身技艺。但这还远远不够,只有经过不断的实战磨练之后,才能成长为真正的武林高手。
经过大半年的闭门苦研,GeaBase第一个版本在2016年初就可以发布了。当时正赶上支付宝史上最大的一次改版,原来的模块化功能被替换成信息流,大大强化了社交属性,自然而然就联系到了图计算,这就给当时的GeaBase团队一个很好的机会,可以到实战中去磨练。
2016年2月,春节之后,GeaBase团队开始介入支付宝,花了大概三个多月时间,在这个过程中不断磨练产品。
浩壹还记得当时的工作状态:压测持续了几个月,每天都是从晚上12点开始,以降低对用户的影响。由于压力测试的顺序是自上而下,先压测上层的产品,再到下层。GeaBase处于最底层,每次轮到GeaBase压测的时候基本都要到凌晨四点钟,压测之后天都快亮了。这段时间是GeaBase团队压力最大,也最煎熬的一段。
但GeaBase团队的付出没有白费,压测顺利,新版支付宝在2016年6月份正式上线,GeaBase的成熟度也迈进了一大步。接下来,GeaBase在蚂蚁金服内部推广了很多的应用场景,后来甚至从2016年下半年开始,GeaBase还被推广到了阿里巴巴集团,应用于淘宝等场景。Geabase作为蚂蚁金服反哺集团的多个技术之一,让该团队十分自豪。
故事尚未结束。经过支付宝大改版的磨练之后,GeaBase团队很快又迎来一次重大的挑战,让浩壹他们这些亲历者仍旧记忆犹新。
从2016年开始,除夕夜看春晚、收集“五福卡”、抢红包成为过年的固定节目,支付宝与央视春晚的联手打造了一种全新的娱乐互动形式。2017年春节,支付宝五福卡引入了更多的社交功能,GeaBase团队也全部投入了项目之中。
这是GeaBase第一次面对这么大的挑战,由于是春节,与央视合作,并且肩负着无数中国人的抢红包“重任”,这次项目只许成功不许失败。
当时GeaBase团队还只有十几个人,白天要开发,还要保障其他业务的运维正常。晚上就开始投入春节红包项目的压力测试,基本上是24小时连轴转。“春节时候我们还要值班,当时很辛苦,但是很有收获感和成就感”,浩壹回忆说。
结果,2017年春节,GeaBase团队成功顶住了压力,为春晚支付宝红包提供了稳健的支撑。当天,蚂蚁金服为GeaBase团队准备了火锅,作为年夜饭也是庆功宴,但GeaBase团队也只能轮流吃,像流水席一样。“痛并快乐着,虽然辛苦,但大家都觉得特别有意义,干的也特别有激情。”
经过2016年中支付宝大改版和2017年初春晚红包的洗礼,在实战中不断得到升华的GeaBase基本已经成型,进入了相对成熟的时期,也让GeaBase在整个阿里巴巴集团打响了知名度,获得了越来越多的应用场景。“2017年的时候,基本上不用我们去找业务,而是业务都来找我们了”。
还有一个收获是,经历过两次大的磨练,GeaBase团队开始慢慢变得有信心,凝聚力也在不断增强,大家觉得图数据库非常有做头,是未来方向之一。GeaBase团队也非常稳定,自2015年组建以来,没有一个转岗的。
GeaBase,中国造
不到四年时间,从头开始,蚂蚁金服GeaBase从几个人的小团队起步,最终做出了中国第一个自主研发的金融级分布式图数据库,不仅具备高性能、高扩展、高可用等优势,拥有自研的高效查询语言,更已成熟应用于在线查询/离线计算的四十多个金融级应用场景,包括支付、风控、财富、会员、营销、口碑等,几乎覆盖了蚂蚁金服所有的业务线。同时,阿里巴巴集团的近二十个产品,如淘宝、天猫、高德、UC、菜鸟、阿里妈妈、天猫精灵等都在使用GeaBase。
GeaBase在性能上做到了极致。如下图示,GeaBase与开源分布式数据库Titan在分布式环境下的性能对比,以及与商业图数据库Neo4j(不支持水平扩展版本)在单机上的性能对比,GeaBase的性能大概是Titan的10-20倍,是Neo4j的3倍左右。
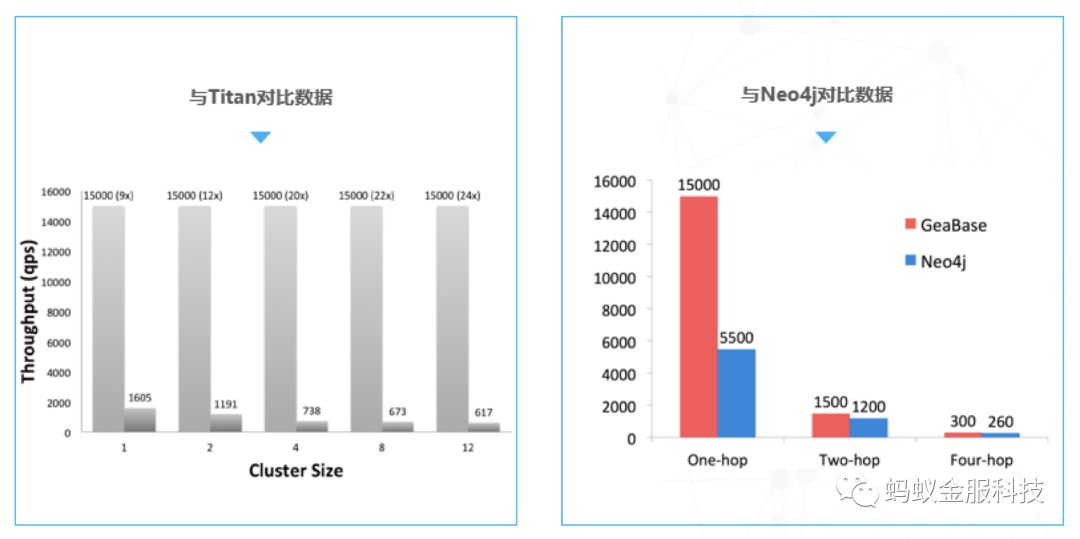
“GeaBase最大的一个优势就是可扩展性,GeaBase整个系统是完完全全为海量数据而建的”,萧河说,GeaBase在蚂蚁金服的应用场景下已经用到了百亿个点、千亿条边,它的计算的查询的能力都达到了非常高的水平,可以处理极大量的数据,而很多图数据库,水平扩展支持不是很好,能够处理的数据量非常小。
GeaBase还引入了多集群和多方位的监控体系来保证整个系统的高可用性,配备了严谨的分布式架构容灾方案,可以做到多副本、多机房、多地部署,实现自动容灾,出现故障秒级自动切换。
值得一提的是,GeaBase还自研了查询语言。众所周知,关系型数据库共同的业界标准是SQL,但SQL并不适合图模型查询,常用的图数据库开源查询语言如Gremlin并不能满足蚂蚁金服复杂的业务环境。
GeaBase自研的查询语言具备四大特性:第一大特性是可扩展性,蚂蚁金服内部业务场景众多,对图查询需求较大,且蚂蚁金服内部业务变化非常快,因此查询语言的设计开发必须具备可扩展性;蚂蚁金服在扩展性上的解决方案是所有OP完全独立,彼此没有任何关系,可保证随时都可快速开发新的OP支持新业务。第二大特性是自定义函数,用户可灵活使用在不同类型里,比如单条记录或综合记录。第三大特性是集成动态语言编程环境,比如Python、C++。第四大特性是为了和开源结合,支持Gremlin。
GeaBase目前可以实现两大类应用场景,其一是在线查询,如实时风控、实时营销、知识图谱等;其二是离线计算,如风控模型计算、可信预测/团伙识别等图模型计算等。
举几个例子。图数据的最典型应用之一就是进行风险识别和诈骗识别,比如在资金关系网络中,如果我们发现资金的流动形成一个闭环,这就很可能是一个洗钱行为的讯号。
GeaBase里存储着蚂蚁账户标签、账户间资金关系、好友关系等图结构数据。通过GeaBase多路通道分析出与指定账户关系较为密切的账户,并以此作为洗钱判定的参考依据之一。利用到的相关指标数据包括基于客户的基本属性和资金量等指标数据、与客户有资金往来密切的客户关系以及其资金内容、好友等亲密关系。不同通道的召回关系层数以及客户数等都可以由系统做到轻松配置,以保证业务的敏捷和精确。
GeaBase还能进行团伙识别,比如,当发现某人在反洗钱黑名单中时,通过对他的整个社交网络、资金网络和设备网络使用机器学习计算节点之间的距离,特征映射到向量的方式。同时,使用离线图计算算法将整个大图分成众多小社区,最后计算出该人所在的社区,以打击整个团伙。
基于GeaBase的另外一个典型应用是推荐算法,在蚂蚁金服的产品线中,无论是好友推荐、内容推荐还是商品推荐都能找到其用武之地。以蚂蚁财富App为例,GeaBase的主要应用场景包括头条金融财经资讯的个性化推荐、社区问答内容推荐、财富号问答推荐,帮助提升社区的内容质量和用户体验。
而在风控应用中,GeaBase能够将用户社交关系、可信关系、交易关系等数据进行融合并提供实时多维多度分析能力,使得用户打扰率大大下降,这些分析是用其他数据库无法实时完成的。例如,通过GeaBase,风控系统可以实时查询用户的社交关系以及其所有可信设备,当发现此手机为配偶可信设备时,风控系统将不再打扰用户。这个分析用其他数据库需要秒级才能完成,无法满足用户体验要求,而GeaBase只需要毫秒级就能完成。
数据显示,在转账到账户、转账到卡、手机号充值、新春红包等场景中,GeaBase每日可为 2.2万用户优化打扰率,直接降低打扰1.5+万笔/日,降低打扰 36%。
随着GeaBase产品的不断成熟,有越来越多的场景在接入进来,为了给客户提供更强大的功能和更好的应用体验,GeaBase也将继续打磨产品,精益求精。
浩壹介绍,GeaBase团队目前正在做离线计算和在线查询的融合,提供一个一站式的图处理服务。原因在于,现在有很多应用场景,既有离线计算的需求,也有一些在线的图查询、图分析的业务场景,这两个平台之前是不在一起的。
“两个平台的话,对于用户来说是不友好的”,浩壹表示,所以,GeaBase团队希望把这两个平台融合起来,为用户在数据视角提供一致的体验。
另外,GeaBase希望推动图查询语言标准的建立。因为到目前为止,图查询语言并没有一个标准。如今,应用图数据库的场景越来越多,大家都意识到了图查询语言没有标准会造成很大的麻烦,对图数据库的通用性和推广普及都非常不利。
“所以,GeaBase团队也在试图和外界的其他公司去合作,看看能不能够建立一个生态联盟,能够把图查询语言这个标准建立起来”,浩壹说,这也是图数据库发展的一个趋势,预计未来几年,业内应该会出现一个较为通用的图查询语言出来,大家都能支持这个查询语言,这将是GeaBase团队未来的一个努力方向。
Think Next, 商业化和技术输出
下一步,GeaBase将紧随蚂蚁金服整体的金融科技开放战略,逐步走上商业化和技术输出之路。
经过十几年在金融领域的技术沉淀,蚂蚁金服逐渐具备了符合金融级系统标准的技术能力,已经能够提供从基础架构技术、金融专有技术到应用技术的完整金融科技堆栈。去年,蚂蚁金服发布了金融科技开放战略,重新明确了“金融科技公司”的定位,在未来,金融科技开放将成为蚂蚁金服的业务重心。
去年10月11日,蚂蚁金服在ATEC大会上首次公布了“BASIC”战略,即Blockchain (区块链)、Artificial Intelligence(人工智能)、Security(安全风控)、 IoT(物联网)和 Computing(计算)五大领域,这是蚂蚁金服面向未来的技术布局,也是金融科技开放的五大方向。而GeaBase则属于“BASIC”战略中“计算”的范畴。
2017年,GeaBase产品成熟之后,蚂蚁金服开始对外推广,在几个国际会议和金融行业峰会上介绍了产品,当时GeaBase还没有上云,也还没有对外输出的打算。去年年底,蚂蚁金服洽谈了几家银行,每一家银行都对GeaBase感兴趣,因为银行同样有着风控应用场景,和蚂蚁金服很多地方都是共通的。
于是,去年年底,蚂蚁金服将GeaBase的对外开放提上了日程,而今年GeaBase的工作重心之一,就是将GeaBase的能力通过云计算开放给合作伙伴,并摸索出更多的应用场景。
GeaBase,从不自信,到一口气
每家企业都有着不同的气质,而最能体现企业气质的莫过于产品。就像Windows之于微软、iPhone之于苹果。GeaBase上也有着很多鲜明的标签,自研、金融级、分布式…它们描述的不仅仅是一款产品的特色,也在彰显着蚂蚁金服的商业之道,更在诉说着一群中国工程师的技术理想主义和情怀。
GeaBase刚起步的时候,团队本身都对这个产品抱有怀疑,甚至缺乏信心。这样的故事在阿里巴巴和蚂蚁金服并不鲜见,阿里云“飞天”、蚂蚁金服OceanBase,无不是从最初技术评估时候的“不可行”、“不可能”,到成就传奇,其中的曲折和艰难,唯有亲历者才有最真实的体会。
经历风雨,终能见彩虹。但风雨过后,当时的那种波澜壮阔也逐渐变得淡然。如同GeaBase团队的这些工程师,在描述GeaBase诞生过程的时候,就是在讲述一个平凡的故事。对他们来说,当GeaBase抗过了支付宝大升级、春节红包这样的巅峰压力,为阿里巴巴集团和蚂蚁金服满足了十亿级用户需求的时候,曾经的付出就变成了满满的成就感,这也是支撑他们继续走下去的最大动力。
福利放送
如果你想体验中国首个金融级分布式图数据库的过人之处,感受下国人所自主研发的创新技术,了解这个“征服”整个阿里体系的现象级产品,那么机会不容错过。GeaBase现正处于免费公测期,将下方网址复制至浏览器中打开即可体验!
https://www.cloud.alipay.com/products/geabase
GeaBase技****术交流群:

— END —
蚂蚁金服官方唯一对外技术传播渠道
投稿邮箱:anttechpr@service.alipay.com
欢迎留言及个人转发,媒体转载请联系授权







本文分享自微信公众号 - 支付宝技术(Ant-Techfin)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。










