
阿里妹导读:2018年12月下旬,由阿里巴巴集团主办的Flink Forward China在北京国家会议中心举行。Flink Forward是由Apache软件基金会授权的全球范围内的Flink技术大会,2015年开始在德国柏林举办,今年第一次进入中国。
今天,计算平台事业部的资深技术专家莫问,将带领我们重温这场大数据技术的饕餮盛宴,感受Apache Flink 作为下一代大数据计算引擎的繁荣生态。
Flink Forward China 大会邀请到了来自阿里巴巴、腾讯、华为、滴滴、美团点评、字节跳动、爱奇艺、去哪儿、Uber、DellEMC、DA(Flink 创始公司)等国内外知名企业以及Apache软件基金会的嘉宾为大家分享了Apache Flink的成长历程、应用场景和发展趋势。
Flink Forward China 2018 嘉宾PPT及演讲视频:
https://github.com/flink-china/flink-forward-china-2018
参与有道,如何更“好”地贡献 Apache 项目
上午大会由Apache软件基金会的秘书长Craig Russell开场,Craig首先分享了Apache开源之道,以及开源社区的精神和体制,然后以Apache Flink项目的成长经历为背景,向大家介绍了如何创建以及管理一个Apache开源项目,如何为Apache开源项目做贡献,并跟随开源项目一起成长和收获。

通过Craig的分享,我们也更详细地了解到了Apache Flink的发展经历。Flink早期起源于德国柏林工业大学的一个研究项目Stratosphere,并于2014年4月捐献给Apache软件基金会,同时重新定位品牌为Flink,经过8个月孵化期,在2014年12月成功从Apache软件基金会毕业,成为Apache顶级项目,从此开始在大数据领域航行。经过最近4年的持续快速发展,Apache Flink社区已经培养出了42名Committer和19名PMC Member,不断加入的新鲜血液为Apache Flink社区持续贡献代码,并推动社区健康快速的发展。

云上计算普惠科技

在Craig分享后,阿里巴巴集团副总裁、搜索事业部与计算平台事业部负责人周靖人进行了主题演讲。靖人首先向大家介绍了阿里巴巴大数据云上计算的现状和趋势,让大家看到了阿里巴巴大数据业务场景的超大规模,以及未来更大的挑战。

为了更好地支持阿里巴巴未来大数据的发展,阿里大数据发展策略一方面要进一步提升计算力和智能化,增强企业级服务能力。同时也要加强技术的生态化建设,大力支持并推动开源技术社区的发展,兼容行业生态标准,发展生态伙伴联盟,推动生态建设。
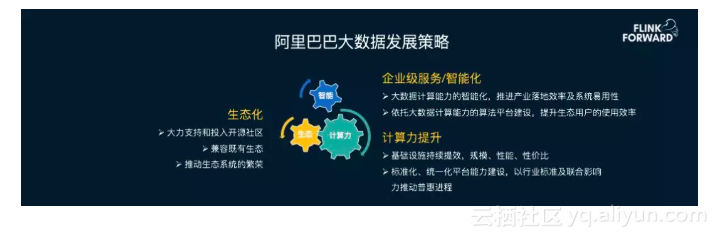
目前阿里巴巴已经参与贡献230+开源项目,具备8000+合作伙伴和2000+ ISV,云上生态也已经突破1000,000开发人员。在大数据领域,阿里巴巴最近几年对Apache Flink社区进行了持续大力的投入,贡献超过15w行代码,主导建立了Flink China中文社区,加速Flink在国内的生态建设,并于今年开始在北京、杭州、上海、深圳等地多次组织Flink Meetup,促进国内Flink技术人员更方便的分享交流。

靖人在分享的最后宣布了阿里巴巴内部Flink版本(Blink)将于2019年1月正式开源,本次开源内部版本的目标主要是希望让广大Flink用户能提前享受到阿里巴巴对Flink的改进和贡献。阿里巴巴同时会尽快将Blink中对Flink的各项改进和优化贡献给Flink社区,坚持对Apache Flink一个社区的拥抱和支持。

Apache Flink,如何重新定义计算?
在靖人宣布阿里巴巴开源内部Flink版本(Blink)后,阿里巴巴集团研究员蒋晓伟分享了Apache Flink在阿里巴巴内部的成长路线以及技术演进之路。
阿里巴巴从2015年开始调研Flink,并于2016年第一次在搜索场景中上线Flink,在经过搜索大数据场景的检验后,2017年Flink开始在阿里巴巴集团范围内支持各项实时计算业务, 到目前为止阿里巴巴基于Flink打造的实时计算平台,已经支持了包括淘宝、天猫、支付宝、高德、飞猪、优酷、菜鸟、饿了么等所有阿里巴巴集团下的所有子公司的数据业务,并通过阿里云向中小企业提供一站式实时计算服务。在2018年的双11中,阿里实时计算平台已经实现了峰值每秒17亿次,当天万亿级的消息处理能力。

Apache Flink目前在阿里巴巴内部最典型的业务场景是实时BI,阿里巴巴内部有着海量的在线交易以及用户数据,实时看到各个维度的数据统计可以及时地感知并指导阿里巴巴的运营。下图是一个典型的阿里实时BI流程,阿里的在线服务系统和数据库会实时产生大量日志数据并进入消息队列,FlinkJob会从消息队列中实时读取处理这些数据,然后将各种统计分析结果实时更新到KV/Table存储系统中,例如:HBase,终端用户可以通过Dashboard实时看到各种维度的数据统计分析结果。

在双11当天,各种维度的实时数据报表是指导双11决策的依据,其中最为关键的就是全球直播的实时GMV成交额。Flink已经连续两年支持阿里巴巴双11实时GMV大屏,一个看似简单的数字,其背后实际上需要大量Flink计算任务平稳、精准地运行支撑。

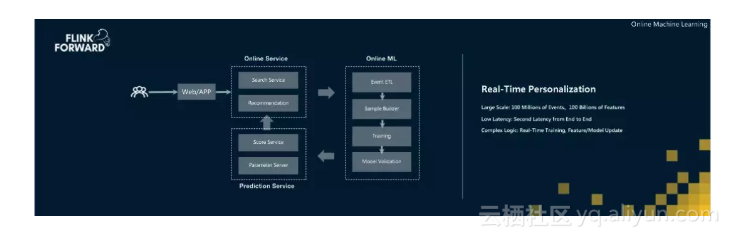
Flink在阿里巴巴另一个典型的应用场景是在线机器学习,传统的离线机器学习方法需要T+1的分析用户历史行为,训练出模型,当第二天模型上线后就已经是过去式,用户当前的需求和预期可能已经完全改变。为了给用户更好的购物消费体验,阿里巴巴的机器学习系统早已经进化到在线学习时代,例如:当一个用户在搜索完一个Query,浏览结果页时,或者点击查看部分商品时,阿里巴巴的在线学习系统已经可以利用这个间隙了解到这个用户当时的意图和偏好,并在下次用户Query时给出更好的排序,并向用户推荐更合适的商品,这种方式不仅可以进一步提升业务效率,同时也能为用户带来更好的产品体验,尤其是在双11这种大促场景,用户的行为时效性都是很短的,只有通过实时在线学习方式,才能做出更加精确的个性化预测和推荐。
在线学习系统的优势在于可以实时收集并处理用户的行为数据,从而进行实时流式的特征计算和在线训练,并将模型的增量更新实时同步回在线系统,形成数据闭环,通过不断迭代自动优化系统效率和用户体验。在阿里的业务规模下,整个在线学习流程将会面对海量的用户数据规模、和极其复杂的计算挑战,但在Flink的驱动下,整个流程可以在秒级完成。
通过以上两种经典场景可以看出阿里巴巴实时业务场景在各方面的挑战都很大,直接将Flink社区版本在阿里上线使用是不现实的,因此阿里巴巴实时计算团队这两年也对Flink进行了全面的优化、改进和功能扩展,其中有些功能和改进已经推回到了Flink社区。
在Flink Runtime领域,阿里巴巴贡献了:
全新的分布式系统架构:一方面对Flink的Job调度和资源管理进行了解耦,使得Flink可以原生运行在YARN,K8S之上;另一方面将Flink的Job调度从集中式转为了分布式,使得Flink集群规模可以更大的扩展。
完善的容错机制:Flink默认在任何task和master失败后,都会整个Job 重启,阿里巴巴提出的region-based failover策略以及job manager failover/ha机制,让Flink可以运行地更加可靠稳定;
大量的性能优化:Flink早期只提供全量Checkpoint机制,这在阿里巴巴大规模State场景下无法正常运行,阿里巴巴提出了增量Checkpoint机制,让Flink即使在TB级State场景下也可以高效运行;Flink Job经常在内部算子或者UDF中访问外部存储系统,例如:mysql,hbase,redis等,一旦出现个别query被卡住,整个task就被卡住,并通过反压影响到整个job,阿里巴巴提出了async IO机制,大幅降低了同步IO访问带来的影响。 此外,阿里巴巴贡献了credit-based的全新网络流控机制,使得Flink网络数据传输性能得到了显著提升。
在Flink SQL领域,阿里巴巴贡献了全新的Streaming SQL语义和功能。例如:Agg Retraction,UDX支持,DDL支持和大量的Connector适配。

在阿里巴巴,我们发现很多经典的业务场景都是同时具备实时流处理和离线批处理两种需求,而且流处理和批处理中的业务逻辑几乎是一样的,但用户需要开发两套代码,两套集群资源部署,导致额外的成本。例如阿里巴巴的商品搜索索引构建流程,白天需要将商品的更新信息流式同步到搜索引擎中,让用户可以在搜索引擎中看到实时的商品信息,晚上需要将全量的阿里巴巴商品进行批处理构建全量索引,这就是传统的Lambda架构。
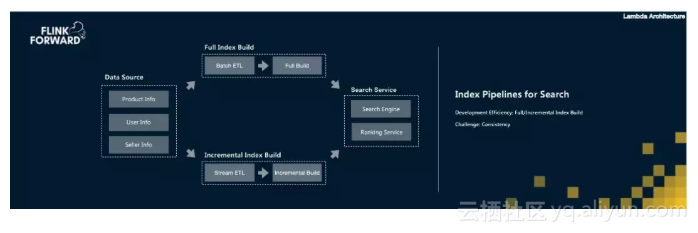
阿里巴巴的解法是希望提供一套批流融合计算引擎,让用户只需开发一套业务代码,就可以在实时和离线两种场景下复用,这也是在2015年阿里巴巴选择Flink作为未来大数据引擎的初衷。 Flink基于流处理机制实现批流融合相对Spark基于批处理机制实现批流融合的思想更自然,更合理,也更有优势,因此阿里巴巴在基于Flink支持大量核心实时计算场景的同时,也在不断改进Flink的架构,使其朝着真正批流融合的统一计算引擎方向前进。
在Flink Runtime领域,阿里巴巴提出了全新的Operator Framework/API设计,使其能够同时适应批流两种算子特性;同时在Job调度和网络Shuffle两种核心机制上,都实现了灵活的插件化机制,使其能够适应批流不同场景的需求。
在Flink SQL领域,阿里巴巴提出了全新的Query Execution和Optimizer架构,利用高效的二级制数据结构,更加合理的内存利用方式,更细粒度的Codegen机制以及更加丰富的优化器策略,使得Streaming 和Batch SQL都有了非常大的性能提升。

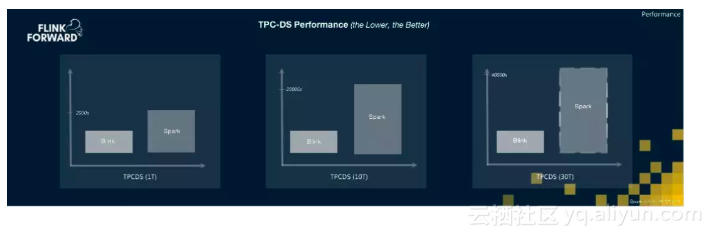
经过大量架构改进和性能优化后,阿里巴巴内部Flink版本(Blink)在批处理上也实现了重大成果突破,在1T,10T和30T的TPC-DS的Benchmark中,Blink的性能数据均明显超出Spark,并且性能优势在数据量不断增加的趋势下越来越明显,这也从结果上验证了Flink基于流做批的架构优势。
目前,阿里巴巴的内部Flink版本(Blink)已经开始支持内部批流融合的应用场景,例如阿里巴巴的搜索推荐算法平台,流式和批量的特征以及训练流程都已经统一基于Flink在运行。

蒋晓伟在分享的最后给出了对Flink未来的一些展望,他认为Flink除了批流融合,还有很多新的方向值得去扩展,例如:Flink可以进一步加强在机器学习和图计算生态上的投入,从而在AI浪潮中实现新的突破。
此外,Flink天然具备基于事件驱动的处理思想,天然的反压和流控机制,以及自带状态管理和弹性扩缩容的能力,这些优势都在促使基于Flink构建微服务框架成为一种新的思想和解决方案。
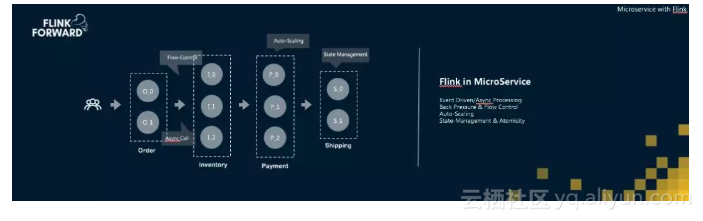
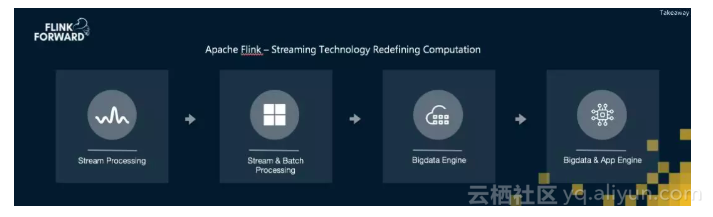
总结蒋晓伟老师的分享,Apache Flink过去虽然在流计算领域已经获得很大的成功,但Flink并没有停滞,而是正在不断在突破自己的边界,Flink不仅仅是Streaming Engine,也不仅仅是Bigdata Engine,未来更希望努力成为Application Engine。
流处理即未来
接下来来自DA(Flink创始公司)的CTO - Stephan Ewen也对Flink的发展趋势给出类似的观点。Stephan认为“Streaming Takes on Everything”即流处理是一切计算的基础, Flink一方面需要朝着离线方向发展,实现批流融合大数据计算能力,另一方面也需要朝着更加实时在线方向发展,支持Event-Driven Application。前面已经重点阐述了Flink在批流融合计算方面的进展,接下来我们重点介绍下Flink在Event-Driven Application方向的思路。

传统的应用服务架构一般是Online App +Database的架构,Online App负责接收用户Request,然后进行内部计算,最后将Result返回给用户,Application的内部状态数据存储在Database中;在Flink的event-drivenApplication架构中,可以认为Flink Source接收Request, Sink返回Result,JobGraph进行内部计算,状态数据都存储在State中。
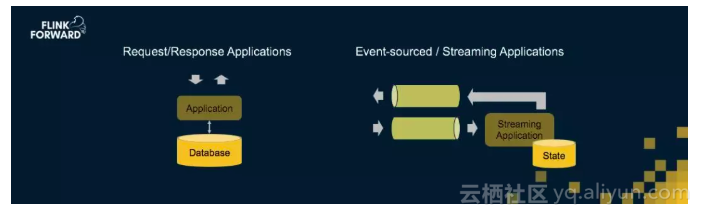
传统应用服务架构需要自己负责分布式和弹性管理,并由Database负责数据一致性管理;而Flink在这两方面是存在天然优势的,因为Flink天然是分布式系统,可以自己管理弹性伸缩,此外Flink内置了状态管理和exactly once一致性语义,因此基于Flink可以更方便、高效实现Transactional Application。
城市级实时计算的力量
在Apache Flink社区大神Stephan Ewen的分享后,来自阿里云的AI首席科学家闵万里向大家分享了实时计算在阿里云智慧城市中发挥的力量,通过分享多个真实应用案例,让大家对实时技术有了更多的体感和认识。
在城市大脑的业务场景中,不仅要能实时处理来自各种传感器收集到的信息,对现实世界发生的事情进行响应,同时也要对未来将要发生的事情进行预测,例如:接下来那里可能要发生交通拥堵,从而提前做出干预,这才是更大的价值。整个城市大脑的架构都运行在阿里云基础设施之上,Apache Flink承担了核心实时计算引擎的角色,负责处理各种结构化和非结构化数据。
在2018年9月的云栖大会上,阿里云发布了杭州城市大脑2.0,覆盖杭州420平方公里,可以监控到超过150万辆在途行驶机动车的实况信息,这个看似简单的事情在过去是很难做到的,现在我们通过1300多个路口的摄像头、传感器以及高德App的实时信息,通过Flink进行三流合一的处理,就可以实时感知到整个城市交通的脉搏信息,并通过进一步分析可以得出延误、安全等交通指数,预测感知城市的态势发展。
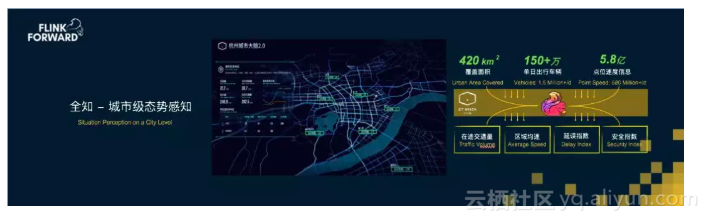
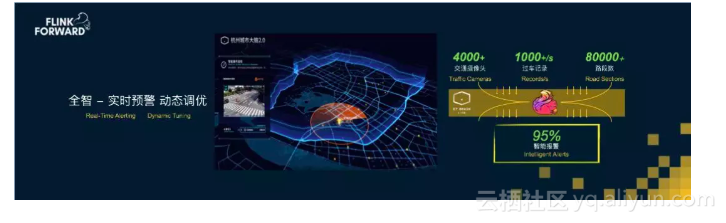
在杭州,城市大脑通过实时分析4000多个交通摄像头采集的视频流,可以实时监控路上车辆的异常事件,例如:车辆超速、逆行和擦碰等,并将这些异常事件实时同步到交警指挥中心进行实时报警,目前杭州的交通事件报警已经有95%来自城市大脑自动通报的,这背后都是通过Flink进行各种复杂的计算逻辑实时算出来的。实时计算让交警处理交通故障的方式从过去的被动等待变成了主动处理,从而大幅提升城市交通的效率,为老百姓带来实实在在的好处。
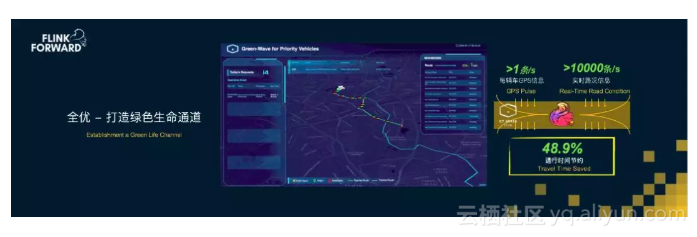
这50%,关乎生死
2018年,城市大脑第一次走出国门,来到马来西亚吉隆坡,基于实时大数据对交通进行智能调度,它可以根据救护车的行驶信息,以及沿途路况信息,智能调整红绿灯,为救护车开辟绿色快速通道,这项技术为救护车节省了近50%的时间到达医院,这50%的时间可能意味着人的生和死,在这里技术显得不再骨感,实时计算的力量也许可以挽救生命。
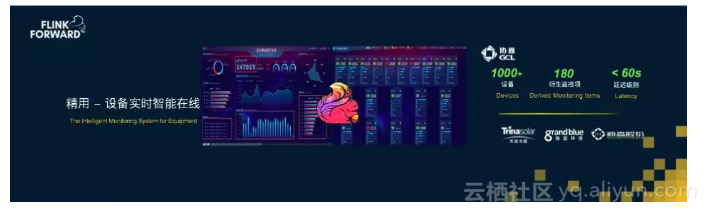
在工业生产IOT场景中,大量设备的传感器都收集了海量的指标数据,这些信息过去都被暂存2个月后丢弃了,唯一的用途就是在出现生产故障时拿来分析用,在有了大数据实时计算能力后,这些指标都可以被实时监控起来,作为及时调控生产流程的依据。协鑫光伏是全球最大的光伏切片企业,阿里云利用实时设备监控,帮助其提高了1%的良品率,每年可以增加上亿元的收入。
滴滴实时计算平台架构与实践
Keynote最后一位嘉宾是来自滴滴出行的研究员罗李,大家都知道滴滴出行是一个实时出行平台和交易引擎,它的数据和场景天然是实时的,各种网约车服务产生的数据都需要实时处理和分析。
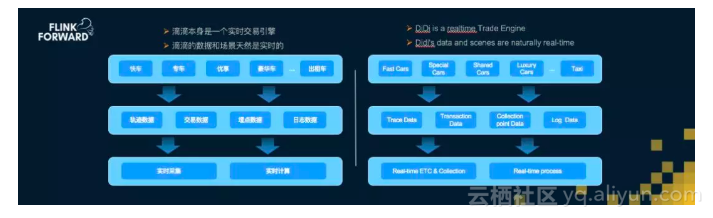
滴滴的实时业务场景主要包括实时风控、实时发券、实时异常检测,实时交易、服务和工单监控,以及实时乘客、司机和订单特征处理等。
滴滴实时计算平台发展已经经历了三个阶段,第一阶段是各个业务方自建小集群,造成集群和资源碎片化问题;第二阶段由公司统一建立了大集群,提供统一的平台化服务,降低了集群资源和维护成本;第三阶段是通过Flink SQL方式提供平台化服务,通过SQL语言优势进一步降低业务开发成本,提升开发效率。
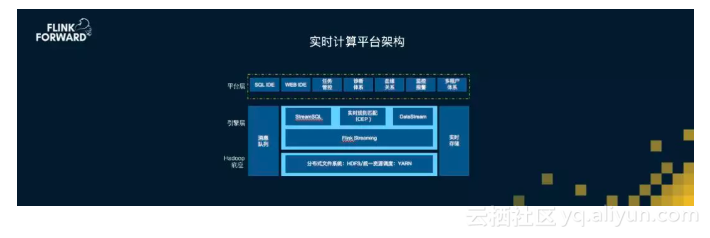
滴滴现阶段基于Apache Flink引擎建设的实时计算平台以开源的Hadoop技术体系作为平台底座,并通过DataStream, SQL和CEP三种API向滴滴内部业务提供实时计算服务,同时在平台层也已经具备相对完善的WebIDE、数据血缘管理、监控报警和多组合隔离等机制。
在滴滴实时业务的快速发展推动下,其实时计算集群已经达到千台规模,每天运行2000+流计算任务,可以处理PB级的数据。
滴滴在搭建Flink实时计算平台的过程中,在内部也对Flink做了一些改进,例如在 Stream SQL领域扩展了DDL,丰富了 UDF,支持了TTL的双流Join和维表Join等;在CEP领域,增加了更多算子支持和规则动态修改能力等,其中部分优化已经推回了社区。

最后,罗李介绍了滴滴实时计算平台的未来规划,主要方向在于进一步推广Stream SQL提升业务开发效率,推动CEP在更多业务场景落地,同时完成公司内部原有Spark Streaming向Flink的迁移,并发力IOT领域。
在下午的几个分会场中,来自阿里巴巴、腾讯、华为、滴滴、美团点评、字节跳动、爱奇艺、去哪儿、Uber、EMC、DA(Flink 创始公司)的多位嘉宾和讲师都围绕Flink技术生态和应用场景进行了分享和交流。从分享的内容上可以看出,BAT三家中阿里巴巴和腾讯都已经完全拥抱了Flink;美团、滴滴和字节跳动(TMD)三家新兴互联网企业在实时计算场景也都已经以Flink作为主流技术方向开始建设,滴滴在Keynote上分享已经令人印象深刻,美团的实时计算集群也已经突破4000台规模,字节跳动(头条和抖音的母公司)的Flink生产集群规模更是超过了1w台的惊人规模 。

由此可见Apache Flink的技术理念已经在业界得到了大量认可,基于Flink的实时计算解决方案开始在国内占据主流趋势。下一步Flink需要一方面继续完善流计算能力,争取在IOT等更多场景落地,与此同时进一步加强在批流融合能力上的全面突破,并完善在机器学习和AI生态上的建设,以及在event-driven的application和微服务场景上进行更长远的探索。











