
1:瞬时(Transient)[临时状态] - 由 new操作符创建,且尚未与Hibernate Session关联的对象被认定为瞬时的。瞬时对象不会被持久化到数据库中,也不会被赋予持久化标识(identifier)。如果瞬时对象在程序中没有被引用,它会被垃圾回收器销毁。使用Hibernate Session可以将其变为持久状态,Hibernate会自动执行必要的SQL语句。
2:持久(Persistent)[持久化状态] - 持久的实例在数据库中有对应的记录,并拥有一个持久化标识。持久的实例可能是刚被保存的,或刚被加载的,无论哪一种,按定义,它存在于相关联的Session作用范围内。Hibernate会检测到处于持久状态的对象的任何改动,在当前操作单元执行完毕时将对象数据 与数据库同步。开发者不需要手动执行UPDATE。将对象从持久状态变成瞬时状态同样也不需要手动执行DELETE语句。
3:脱管(Detached)[游离状态] - 与持久对象关联的 Session被关闭后,对象就变为脱管的。对脱管对象的引用依然有效,对象可继续被修改。脱管对象如果重新关联到某个新的Session上,会再次转变为持久的,在脱管期间的改动将被持久化到数据库。
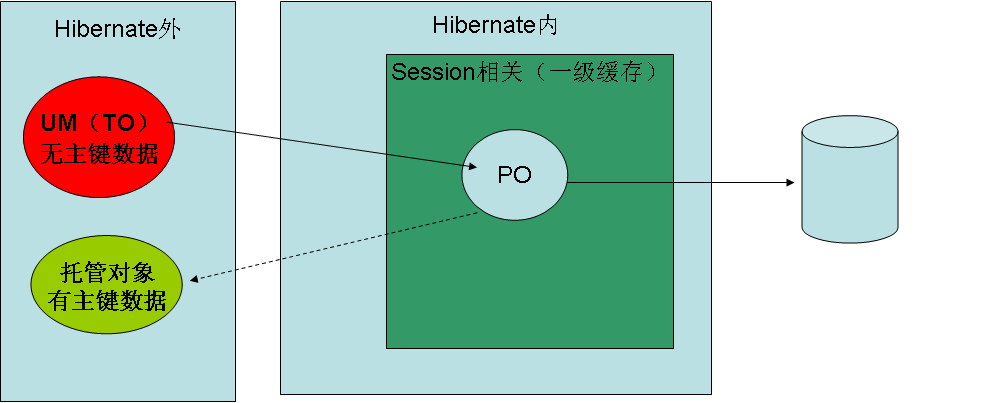
通过Session接口来操作Hibernate
新增——save方法、persist方法
1:persist() 使一个临时实例持久化。然而,它不保证立即把标识符值分配给持久性实例,这会发生在flush的时候。persist() 也保证它在事务边界外调用时不会执行INSERT 语句。这对于长期运行的带有扩展会话/持久化上下文的会话是很有用的。
2:save() 保证返回一个标识符。如果需要运行INSERT 来获取标识符(如 "identity" 而非"sequence" 生成器),这个INSERT 将立即执行,不管你是否在事务内部还是外部。这对于长期运行的带有扩展会话/持久化上下文的会话来说会出现问题。
删除——delete方法
修改——有四种方法来做,分别是:
1:直接在Session打开的时候load对象,然后修改这个持久对象,在事务提交的时候,会自动flush到数据库中。
2:修改托管对象,可用update或merge方法
3:自动状态检测:saveOrUpdate方法
update和merge方法
1:如果数据库里面存在你要修改的记录,update每次是直接执行修改语句;而merge是先在缓存中查找,缓存中没有相应数据,就到数据库去查询,然后再合并数据,如果数据是一样的,那么merge方法不会去做修改,如果数据有不一样的地方,merge才真正修改数据库。
2:如果数据库中不存在你要修改的记录,update是报错;而merge方法是当作一条新增的值,向数据库中新增一条数据。
3:update后,传入的TO对象就是PO的了,而merge还是TO的。
4:如果你确定当前session没有包含与之具有相同持久化标识的持久实例,使用update()。如果想随时合并改动而不考虑session的状态,使用 merge()。换句话说,在一个新 session中通常第一个调用的是update()方法,以保证重新关联脱管对象的操作首先被执行。
5:请注意:使用update来把一个TO变成PO,那么不管是否修改了对象,都是要执行update sql语句的。
通常下面的场景会使用update() 或saveOrUpdate()
1:程序在第一个 session 中加载对象
2:该对象被传递到表现层
3:对象发生了一些改动
4:该对象被返回到业务逻辑层
5:程序调用第二个session的update()方法持久这些改动
saveOrUpdate方法做下面的事:
1:如果对象已经在本session中持久化了,不做任何事
2:如果另一个与本session关联的对象拥有相同的持久化标识,抛出一个异常
3:如果对象没有持久化标识属性,对其调用save()
4:如果对象的持久标识表明其是一个新实例化的对象,对其调用 save()。
5:如果对象是附带版本信息的(通过
6:否则update()这个对象
merge做如下的事情
1:如果session中存在相同持久化标识的实例,用用户给出的对象的状态覆盖旧有的持久实例
2:如果session中没有相应的持久实例,则尝试从数据库中加载,或创建新的持久化实例
3:最后返回该持久实例
4:用户给出的这个对象没有被关联到session 上,它依旧是脱管的
按主键查询
1:load方法:load的时候首先查询一级缓存,没有就创建并返回一个代理对象,等到使用的时候,才查二级缓存,如果二级缓存中没有数据就查数据库,如果数据库中没有,就抛例外
2:get方法:先查缓存,如果缓存中没有这条具体的数据,就查数据库,如果数据库没有值,就返回null,总之get方法不管用不用,都要拿到真实的数据
Hibernate实现按条件查询的方式
1:最重要的按条件查询的方法是使用Query接口,使用HQL
2:本地查询(native sql):就是使用标准的sql,也是通过Query接口来实现
3:按条件查询(Query By Criteria,QBC):使用动态的,面向对象的方式来创建查询
4:按样例查询(Query By Example,简写QBE):类似我们自己写的getByCondition
5:命名查询:在hbm.xml中配置hql语句,在程序里面通过名称来创建Query接口
Query的list方法
一个查询通常在调用 list() 时被执行,执行结果会完全装载进内存中的一个集合,查询返回的对象处于持久状态。如果你知道的查询只会返回一个对象,可使用 list() 的快捷方式 uniqueResult()。
Iterator和List
某些情况下,你可以使用iterate()方法得到更好的性能。 这通常是你预期返回的结果在session,或二级缓存(second-level cache)中已经存在时的情况。 如若不然,iterate()会比list()慢,而且可能简单查询也需要进行多次数据库访问: iterate()会首先使用1条语句得到所有对象的持久化标识(identifiers),再根据持久化标识执行n条附加的select语句实例化实际的对象。
外置命名查询
可以在映射文件中定义命名查询(named queries)。
java代码:
- <query name="javass">
- <![CDATA[select Object(o) from UserModel o]]>
参数绑定及执行以编程方式完成:
List list = s.getNamedQuery("cn.javass.h3.hello.UserModel.javass").list();
注意要用全限定名加名称的方式进行访问
flush方法
每间隔一段时间,Session会执行一些必需的SQL语句来把内存中对象的状态同步到JDBC连接中。这个过程被称为刷出(flush),默认会在下面的时间点执行:
1:在某些查询执行之前
2:在调用org.hibernate.Transaction.commit()的时候
3:在调用Session.flush()的时候
涉及的 SQL 语句会按照下面的顺序发出执行:
1. 所有对实体进行插入的语句,其顺序按照对象执行save() 的时间顺序
2. 所有对实体进行更新的语句
3. 所有进行集合删除的语句
4. 所有对集合元素进行删除,更新或者插入的语句
5. 所有进行集合插入的语句
6. 所有对实体进行删除的语句,其顺序按照对象执行 delete() 的时间顺序
除非你明确地发出了flush()指令,关于Session何时会执行这些JDBC调用是完全无法保证的,只能保证它们执行的前后顺序。 当然,Hibernate保证,Query.list(..)绝对不会返回已经失效的数据,也不会返回错误数据。
lock方法:也允许程序重新关联某个对象到一个新 session 上。不过,该脱管对象必须是没有修改过的。示例如:s.lock(um, LockMode.READ);
注意:lock主要还是用在事务处理上,关联对象只是一个附带的功能
获取元数据
Hibernate 提供了ClassMetadata接口和Type来访问元数据。示例如下:(其中sf为SessionFactory)
java代码:
- ClassMetadata catMeta = sf.getClassMetadata(UserModel.class);
- String[] propertyNames = catMeta.getPropertyNames();
- Type[] propertyTypes = catMeta.getPropertyTypes();
- for (int i = 0; i < propertyNames.length; i++) {
- System.out.println("name=="+propertyNames[i] + ", type==“
- +propertyTypes[i]);
- }
HQL介绍
Hibernate配备了一种非常强大的查询语言,这种语言看上去很像SQL。但是不
要被语法结构 上的相似所迷惑,HQL是非常有意识的被设计为完全面向对象的查
询,它可以理解如继承、多态 和关联之类的概念。
看个示例,看看sql和HQL的相同与不同:
Sql:select * from tbl_user where uuid=‘123’
HQL:select Object(o) from UserModel o where o.uuid=‘123’
HQL特点
1:HQL对Java类和属性是大小写敏感的,对其他不是大小写敏感的。
2:基本上sql和HQL是可以转换的,因为按照Hibernate的实现原理,最终运行的还是sql,只不过是自动生成的而已。
3:HQL支持内连接和外连接
4:HQL支持使用聚集函数,如:count、avg、sum、min、max等
5:HQL支持order by 和 group by
6:HQL支持条件表达式,如:in、like、between等
select子句
1:直接返回对象集合,形如:select o from UserModel o
2:返回某个特定类型的集合,形如:select o.name from UserModel o
3:返回Object[],形如:select o.uuid,o.name from UserModel o
4:返回List,形如:select new List(o.uuid,o.name) from UserModel o
5:返回任意的对象,形如:select new cn.javass.h3.hello.A(o.uuid,o.name) from UserModel o ,这要求A对象有一个构造方法是传入这两个参数
6:返回Map类型,形如:select new Map(o.uuid as Id,o.name as N) from UserModel o ,返回的结果,以as后面的别名做map的key,对应的数据做值
from子句
1:直接from对象,形如: from UserModel
2:可以分配别名,形如:from UserModel as um , as关键字可以省略
3:如果from后面有多个对象,形如:from UserModel,DepModel ,相当于多表联合查询,返回他们的笛卡尔积
聚集函数
1:受支持的有avg,sum,min,max,count
2:关键字 distinct 与all 也可以使用,它们具有与 SQL 相同的语义,比如:
select count(distinct o.name) from UserModel o
nwhere子句
1:如果前面没有指派别名,那就直接使用属性名
2:如果指派了别名,必须使用别名.属性的方式
3:在where子句中允许使用的表达式包括大多数在 SQL中使用的表达式,包括:
(1)数学运算符 +,-,*,/
(2)二进制比较运算符 =, >=, <=, <>, !=, like
(3)逻辑运算符 and,or,not
(4)括号 ( ),表示分组
(5)in, not in, between, is null, is not null, is empty, is not empty, member of and not member of
(6)字符串连接符 ...||... or concat(...,...)
(7)current_date(), current_time(), and current_timestamp()
(8)second(...)、minute(...)、hour(...)、day(...)、month(...) 和 year(...)
(9)EJB-QL 3.0 定义的任何功能或操作符:substring(), trim(), lower(), upper(), length(),locate(), abs(), sqrt(), bit_length(), mod()
(10)coalesce() 和 nullif()
(11)str() 把数字或者时间值转换为可读的字符串
(12)cast(... as ...),其第二个参数是某 Hibernate 类型的名字,以及 extract(... from ...),只要 ANSI cast() 和 extract() 被底层数据库支持
(13)HQL index() 函数,作用于 join 的有序集合的别名。
(14)HQL 函数,把集合作为参数:size(), minelement(), maxelement(), minindex(), maxindex(),还有特别的 elements() 和 indices 函数,可以与数量词加以限定:some, all, exists, any, in。
(15)任何数据库支持的 SQL 标量函数,比如 sign(), trunc(), rtrim(), sin()
(16)JDBC 风格的参数传入 ?
(17)命名参数 :name,:start_date,:x1
(18)SQL 直接常量 'foo', 69, 6.66E+2, '1970-01-01 10:00:01.0'
(19)Java public static final 类型的常量 eg.Color.TABBY
group by 子句
1:对于返回聚集值的查询,可以按照任何属性进行分组
2:可以使用having子句
3:sql中的聚集函数,可以出现在having子句中
4:group by 子句与 order by 子句中都不能包含算术表达式
5:不能group by 某个实体对象,必须明确的列出所有的聚集属性
order by 子句
查询返回的列表(list)可以按照一个返回的类或组件(components)中的任何属性进行排序,可选的 asc 或 desc 关键字指明了按照升序或降序进行排序。
子查询
对于支持子查询的数据库,Hibernate 支持在查询中使用子查询。一个子查询必须被圆括号包围起来。
n连接(join)
1:Hibernate可以在相关联的实体间使用join,类似于sql,支持inner join、left outer join、right outer join、full join(全连接,并不常用)。
2:inner join可以简写成join,left outer join 和right outer join在简写的时候可以把outer去掉。
with
通过 HQL 的 with 关键字,你可以提供额外的 join 条件。
如:from Cat as cat left join cat.kittens as kitten with kitten.bodyWeight > 10.0
fetch
可以要求立即返回关联的集合对象,如:
java代码:
- from Cat as cat
- inner join fetch cat.mate
- left join fetch cat.kittens
对于没有关联的实体,如何使用join呢?
对于没有关联的实体,想要使用join,可以采用本地查询的方式,使用sql来实现,比如:
s.createSQLQuery("select um.*,dm.* from tbl_user2 um left join tbl_dep dm on um.age=dm.uuid")
.addEntity("um",UserModel.class).addEntity("dm",DepModel.class);
1:新增
2:load、 get
3:修改
4:按条件查询
(1)传入条件值的方法:?或 :名称,索引从0开始
(2)给参数赋值
(3)返回对象
(4)返回多个属性,形成Object[]
(5)getByCondition的Hibernate版实现
5:删除
6:分页
Query q = sess.createQuery("from DomesticCat cat");
q.setFirstResult(20);
q.setMaxResults(10);
List cats = q.list();
也可以使用你的数据库的Native SQL语言来查询数据。这对你在要使用数据库的
某些特性的时候(比如说在查询提示或者Oracle中的 CONNECT关键字),这是非常有
用的。这就能够扫清你把原来直接使用SQL/JDBC 的程序迁移到基于 Hibernate应用
的道路上的障碍。
使用SQLQuery
对原生SQL查询执行的控制是通过SQLQuery接口进行的,通过执行
Session.createSQLQuery()获取这个接口。下面来描述如何使用这个API进行查询。
标量查询(Scalar queries)
s.createSQLQuery(“select uuid,name from tbl_user”).list();
它将返回一个Object[]组成的List,Hibernate会使用ResultSetMetadata来判定返回的标量值的实际顺序和类型。你也可以使用scalar来明确指明类型,如:
s.createSQLQuery("select * from tbl_user").addScalar("id", LongType. INSTANCE)
id字段就明确是long型,当然你也可以指定很多个字段的类型。
实体查询(Entity queries)
上面的查询都是返回标量值的,也就是从resultset中返回的“裸”数据。下面展示如何通过addEntity()让原生查询返回实体对象。
(1) s.createSQLQuery("select * from tbl_user").addEntity(UserModel.class);
(2) s.createSQLQuery(“select uuid,userId from tbl_user2”).addEntity (UserModel.class); //一定要把表的所有字段罗列出来
(3) s.createSQLQuery("select {um}.uuid as {um.uuid},{um}.name as {um.name} from tbl_user {um}").addEntity("um",UserModel.class);
功能跟第二个差不多,也要把表的所有字段都罗列出来
(4)简单点的写法:s.createSQLQuery("select * from tbl_user2 um")
.addEntity("um",UserModel.class);
(5)添加条件的示例:
s.createSQLQuery("select * from tbl_user where uuid=? and name like ?").addEntity(UserModel.class).setString(0, "3").setString(1,"%na%");
命名Sql查询
可以在映射文档中定义查询的名字,然后就可以象调用一个命名的 HQL 查询一样直接调用命名 SQL查询.在这种情况下,我们不 需要调用 addEntity() 方法。
在hbm.xml中配置,示例如下:
java代码:
- <sql-query name="users">
- <return alias="um" class="cn.javass.h3.hello.UserModel"/>
- select um.name as {um.name},
- um.age as {um.age},
- um.uuid as {um.uuid}
- from tbl_user um
- where um.name like :name
注意:因为要返回一个对象,所以要把表的所有字段都罗列上,否则会报错“列名无效”,其实是在反射向对象赋值的时候,从sql的返回中得不到这个数据。
程序里面调用示例:Query q = s.getNamedQuery(um.getClass().getName()
+".users").setString("name", "%n%");
命名Sql查询--使用return-property
使用
在hbm.xml中配置,示例如下:
java代码:
- <sql-query name="users">
- <return alias="um" class="cn.javass.h3.hello.UserModel">
- <return-property name="name" column="umName"></return-property>
- <return-property name="uuid" column="uuid"></return-property>
- <return-property name="age" column="age"></return-property>
- </return>
- select um.name as umName,
- um.age as age,
- um.uuid as uuid
- from tbl_user um
- where um.name like :name
具有一个直观的、可扩展的条件查询API是Hibernate的特色。
创建一个Criteria 实例
org.hibernate.Criteria接口表示特定持久类的一个查询。Session是Criteria实例的工厂。
java代码:
- Criteria crit = sess.createCriteria(Cat.class);
- crit.setMaxResults(50);
- List cats = crit.list();
限制结果集内容
一个单独的查询条件是org.hibernate.criterion.Criterion 接口的一个实例org.hibernate.criterion.Restrictions类定义了获得某些内置Criterion类型的工厂方法。
java代码:
- List list = s.createCriteria(UserModel.class)
- .add(Restrictions.eq("uuid", "3"))
- .add(Restrictions.like("name", "%n%"))
- .list();
- 约束可以按照逻辑分组,示例如下:
- List cats = sess.createCriteria(Cat.class)
- .add( Restrictions.like("name", "Fritz%") )
- .add( Restrictions.or(
- Restrictions.eq( "age", new Integer(0) ),
- Restrictions.isNull("age")
- )
- ).list();
对结果集排序
可以使用org.hibernate.criterion.Order 来为查询结果排序。示例如下:
java代码:
- List cats = sess.createCriteria(Cat.class)
- .add( Restrictions.like("name", "F%")
- .addOrder( Order.asc("name") )
- .addOrder( Order.desc("age") )
- .setMaxResults(50)
- .list();
1:假如有如下程序,需要向数据库里面加如100000条数据:
java代码:
- Session session = sessionFactory.openSession();
- Transaction tx = session.beginTransaction();
- for ( int i=0; i<100000; i++ ) {
- Customer customer = new Customer(.....);
- session.save(customer);
- }
- tx.commit();
- session.close();
这个程序很显然不能正常运行,会抛出内存溢出的例外。按照前面讲过的原理,Hibernate的save方法是先把数据放到内存里面,数据太多,导致内存溢出。
那么该如何解决呢?
解决方案:
1:首先将 hibernate.jdbc.batch_size的批量抓取数量参数设置到一个合适值(比如,10 - 50 之间),同时最好关闭二级缓存,如果有的话。
2:批量插入,一个可行的方案如下:
java代码:
- for ( int i=0; i<100000; i++ ) {
- Customer customer = new Customer(.....);
- session.save(customer);
- if ( i % 20 == 0 ) {
- //将本批数据插入数据库,并释放内存
- session.flush();
- session.clear();
- }
- }
批量更新的做法跟这个类似
1:默认的Hibernate是有缓存的,称之为一级缓存。
2:也可以使用StatelessSession,来表示不实现一级缓存,也不和二级缓存和查询缓存交互
3:StatelessSession是低层的抽象,和底层JDBC相当接近
java代码:
- StatelessSession session = sessionFactory.openStatelessSession();
- Transaction tx = session.beginTransaction();
- ScrollableResults customers = session.getNamedQuery("GetCustomers") .scroll(ScrollMode.FORWARD_ONLY);
- while ( customers.next() ) {
- Customer customer = (Customer) customers.get(0);
- customer.updateStuff(...);
- session.update(customer);
- } tx.commit(); session.close();
http://sishuok.com/forum/blogPost/list/2477.html;jsessionid=487FBED87666D05D4096075DBE429503











