
本文首发于 vivo互联网技术 微信公众号
链接: https://mp.weixin.qq.com/s/MaeXn-kmgLUah78brglFkg
作者:Yang Yijun
本文主要描述Linux Page Cache优化的背景、Page Cache的基本概念、列举之前针对Kafka的 IO 性能瓶颈采取的一些解决方案、如何进行Page Cache相关参数调整以及性能优化前后效果对比。
一、优化背景
当业务快速增长,每天需要处理万亿记录级数据量时。在读写数据方面,Kafka 集群的压力将变得巨大,而磁盘 IO 成为了 Kafka 集群最大的性能瓶颈。
当出现入流量突增或者出流量突增情况,磁盘 IO 持续处于被打满状态,导致无法处理新的读写请求,甚至造成部分broker节点雪崩而影响集群的稳定。
如下图所示,磁盘 IO 被持续打满:
这严重的影响了集群的稳定,从而影响业务的稳定运行。对此,我们做出了一些针对性的优化方案:
对Linux操作系统的Page Cache参数进行优化;【本文主要讲解内容】
对kafka集群用户的出入流量进行限制,避免出入流量突增给磁盘IO带来的压力;【本文对此方案不做讲解】
按业务对集群进行资源组隔离(集群broker的物理隔离),避免不同业务间因为共享磁盘IO相互影响;【本文对此方案不做讲解】
对Kafka集群broker节点服务参数进行优化;【本文对此方案不做讲解】
改造Kafka副本迁移源码,实现增量并发副本迁移,减少副本迁移给集群broker节点磁盘IO带来的压力;【本文对此方案不做讲解】
开发一套Kafka集群自动负载均衡服务,定期对集群进行负载均衡;【本文对此方案不做讲解】
采用IO性能更好的SSD固态硬盘替换普通的机械硬盘;进行磁盘RAID让broker内部多块磁盘间IO负载更加均衡【本文对此方案不做讲解】
改造Kafka源码,对Kafka集群单个broker及单个topic进行出入流量限制,实现流量对最细粒度控制;当单个broker流量突增时可以对其进行上限限制,避免节点被异常流量打挂;【本文对此方案不做讲解】
改造Kafka源码,修复副本迁移任务启动后不可手动终止的缺陷,实现当因迁移导致负载过高却无法停止的问题;【本文对此方案不做讲解】
机房网络带宽的竞争也将间接的影响到follower同步leader的数据,最终将导致follower同步拉取历史数据而增加IO负载,因此需要对网络带宽进行优先级打标,当有竞争时提高Kafka集群的优先级,避免kafka集群的broker和其他大量消耗网络带宽的业务共用机房交换机。【本文对此方案不做讲解】
以上只是列举了几点主要的优化方案,还有一些其他的内容这里不再赘述。本文我们主要来讲解一下 Linux操作系统的Page Cache参数调优。
二、基本概念
1、什么是Page Cache?
Page Cache是针对文件系统的缓存,通过将磁盘中的文件数据缓存到内存中,从而减少磁盘I/O操作提高性能。
对磁盘的数据进行缓存从而提高性能主要是基于两个因素:
磁盘访问的速度比内存慢好几个数量级(毫秒和纳秒的差距);
被访问过的数据,有很大概率会被再次访问。
文件读写流程如下所示:
2、读Cache
当内核发起一个读请求时(例如进程发起read()请求),首先会检查请求的数据是否缓存到了Page Cache中。
如果有,那么直接从内存中读取,不需要访问磁盘,这被称为cache命中(cache hit);
如果cache中没有请求的数据,即cache未命中(cache miss),就必须从磁盘中读取数据。然后内核将读取的数据缓存到cache中,这样后续的读请求就可以命中cache了。
page可以只缓存一个文件部分的内容,不需要把整个文件都缓存进来。
3、写Cache
当内核发起一个写请求时(例如进程发起write()请求),同样是直接往cache中写入,后备存储中的内容不会直接更新(当服务器出现断电关机时,存在数据丢失风险)。
内核会将被写入的page标记为dirty,并将其加入dirty list中。内核会周期性地将dirty list中的page写回到磁盘上,从而使磁盘上的数据和内存中缓存的数据一致。
当满足以下两个条件之一将触发脏数据刷新到磁盘操作:
数据存在的时间超过了dirty_expire_centisecs(默认300厘秒,即30秒)时间;
脏数据所占内存 > dirty_background_ratio,也就是说当脏数据所占用的内存占总内存的比例超过dirty_background_ratio(默认10,即系统内存的10%)的时候会触发pdflush刷新脏数据。
4、Page Cache缓存查看工具
我们如何查看缓存命中率呢?在这里我们可以借助一个缓存命中率查看工具 cachestat。
(1)下载安装
mkdir /opt/bigdata/app/cachestat
cd /opt/bigdata/app/cachestat
git clone --depth 1 https://github.com/brendangregg/perf-tools
(2)启动执行
(3)输出内容说明
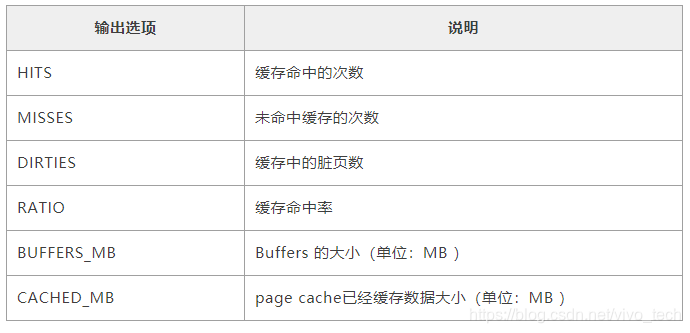
5、如何回收Page Cache
执行脚本:echo 1 > /proc/sys/vm/drop_caches 这里可能需要等待一会,因为有应用程序正在写数据。
回收前:
回收后:
缓存回收后,正常情况下,buff/cache应该是0的,我这里之所以不为0是因为有数据正在不停的写入。
三、参数调优
备注:不同硬件配置的服务器可能效果不同,所以,具体的参数值设置需要考虑自己集群硬件配置。
考虑的因素主要包括:CPU核数、内存大小、硬盘类型、网络带宽等。
1、如何查看Page Cache参数
执行命令 sysctl -a|grep dirty
2、操作系统Page Cache相关参数默认值
vm.dirty_background_bytes = 0 # 和参数vm.dirty_background_ratio实现相同功能,但两个参数只会有其中一个生效,表示脏页大小达到多少字节后开始触发刷磁盘
vm.dirty_background_ratio = 10
vm.dirty_bytes = 0 # 和参数vm.dirty_ratio实现相同功能,但两个参数只会有其中一个生效,表示脏页达到多少字节后停止接收写请求,开始触发刷磁盘
vm.dirty_ratio = 20
vm.dirty_expire_centisecs = 3000 #这里表示30秒(时间单位:厘秒)
vm.dirty_writeback_centisecs = 500 #这里表示5秒(时间单位:厘秒)
3、如果系统中cached大量数据可能存在的问题
缓存的数据越多,丢数据的风险越大。
会定期出现IO峰值,这个峰值时间会较长,在这期间所有新的写IO性能会很差(极端情况直接被hang住)。
后一个问题对写负载很高的应用会产生很大影响。
4、如何调整内核参数来优化IO性能?
(1)****vm.dirty_background_ratio参数优化
当cached中缓存当数据占总内存的比例达到这个参数设定的值时将触发刷磁盘操作。
把这个参数适当调小,这样可以把原来一个大的IO刷盘操作变为多个小的IO刷盘操作,从而把IO写峰值削平。
对于内存很大和磁盘性能比较差的服务器,应该把这个值设置的小一点。
#设置方法1:
sysctl -w vm.dirty_background_ratio=1(临时生效,重启服务器后失效)
#设置方法2(永久生效):
echo vm.dirty_background_ratio=1 >> /etc/sysctl.conf
sysctl -p /etc/sysctl.conf
#设置方法3(永久生效):
#当然你还可以在/etc/sysctl.d/目录下创建一个自己的参数优化文件,把系统优化参数进行归类存放,然后设置生效,如:
touch /etc/sysctl.d/kafka-optimization.conf
echo vm.dirty_background_ratio=1 >> /etc/sysctl.d/kafka-optimization.conf
sysctl --system
(2)****vm.dirty_ratio参数优化
对于写压力特别大的,建议把这个参数适当调大;对于写压力小的可以适当调小;如果cached的数据所占比例(这里是占总内存的比例)超过这个设置,
系统会停止所有的应用层的IO写操作,等待刷完数据后恢复IO。所以万一触发了系统的这个操作,对于用户来说影响非常大的。
(3)****vm.dirty_expire_centisecs参数优化
这个参数会和参数vm.dirty_background_ratio一起来作用,一个表示大小比例,一个表示时间;即满足其中任何一个的条件都达到刷盘的条件。
为什么要这么设计呢?我们来试想一下以下场景:
如果只有参数 vm.dirty_background_ratio ,也就是说cache中的数据需要超过这个阀值才会满足刷磁盘的条件;
如果数据一直没有达到这个阀值,那相当于cache中的数据就永远无法持久化到磁盘,这种情况下,一旦服务器重启,那么cache中的数据必然丢失。
结合以上情况,所以添加了一个数据过期时间参数。当数据量没有达到阀值,但是达到了我们设定的过期时间,同样可以实现数据刷盘。
这样可以有效的解决上述存在的问题,其实这种设计在绝大部分框架中都有。
(4)****vm.dirty_writeback_centisecs参数优化
理论上调小这个参数,可以提高刷磁盘的频率,从而尽快把脏数据刷新到磁盘上。但一定要保证间隔时间内一定可以让数据刷盘完成。
(5)vm.swappiness参数优化
禁用swap空间,设置vm.swappiness=0
5、参数调优前后效果对比
(1)写入流量对比
从下图可以看出,优化前写入流量出现大量突刺,波动非常大,优化后写入流量更加平滑。
(2)磁盘IO UTIL对比
从下图可以看出,优化前IO出现大量突刺,波动非常大,优化后IO更加平滑。
(3)网络入流量对比
从下图可以看出,优化前后对网络入流量并无影响。
四、总结
这里不同机型,不同硬件配置可能最终优化效果也不一样,但是参数变化的趋势应该是一致的。
1、当vm.dirty_background_ratio、vm.dirty_expire_centisecs变大时
出入流量抖动变大,出现大量突刺;
IO抖动变大,出现大量突刺,磁盘有连续打满的情况;
出入流量平均大小不受影响;
2、当vm.dirty_background_ratio、vm.dirty_expire_centisecs变小时
出入流量抖动变小,趋于平滑稳定,无突刺;
磁盘IO抖动变小,无突刺,磁盘IO无打满情况;
出入流量平均大小不受影响;
3、当vm.dirty_ratio变小(低于10)
- 出入流量隔一段时间出现一个明显的波谷;这是因为cache数据量超过vm.dirty_ratio设定的值将阻塞写请求,进行刷盘操作。
4、当vm.dirty_ratio变大时(高于40),出入流量无明显的波谷,流量平滑;
5、当以下三个参数分别为对应值时,出入流量非常平滑,趋于一条直线;
vm.dirty_background_ratio=1
vm.dirty_ratio=80
vm.dirty_expire_centisecs=1000
6、如下图所示,整个调整过程平均流量不受影响
更多内容敬请关注 vivo 互联网技术 微信公众号
注:转载文章请先与微信号:Labs2020 联系











